- Как web-страницу легко превратить в PDF?
- Converting HTML to PDFs in Android
- Performing the Conversion
- Controlling the Conversion
- Observing the Conversion Progress
- Intercepting Loaded Resources
- Troubleshooting
- aspose-com-gists / convert-html-to-password-protected-pdf.java
- iText HTML to PDF Example
- 1. Project Set-Up
- 2. Implementation
- 3. Download the Source Code
- Android java html to pdf
Как web-страницу легко превратить в PDF?
Преамбула:
Напишем простой сервлет, который будет брать указанную нами web-страницу по HTTP протоколу и генерировать на её основе полноценный PDF документ.
Используемые библиотеки:
- Flying Saucer PDF — основная библиотека, которая поможет создать нам PDF документ из HTML/CSS
- iText — библиотека, которая включена в состав той, что описана выше, но я не мог не включить ее в список библиотек, т.к. именно на основе неё будет генерироваться PDF документ
- HTML Cleaner — библиотека, которая будет приводить наш HTML код в порядок
Формирование страницы:
Одним из самый важных моментов является формирование страницы. Дело в том, что именно из самой страницы, посредством CSS, задаются параметры будущего PDF документа.
Здесь хочу остановиться на нескольких моментах. Для начала самое важное: все пути должны быть абсолютными! Картинки, стили, адреса шрифтов и др., на всё должны быть прописаны абсолютные пути. А теперь пройдемся по CSS правилам (то, что начинается с символа @).
@ font-face — это правило, которое скажет нашему PDF генератору какой нужно взять шрифт, и откуда. Проблема в том, что библиотека, которая будет генерировать PDF документ не содержит шрифтов, включающих в себя кириллицу. Именно поэтому таким образом придется определять ВСЕ шрифты, которые используются в Вашей странице, пусть это будут даже стандартные шрифты: Arial, Verdana, Tahoma, и пр., в противном случае Вы рискуете не увидеть кириллицу в Вашем документе.
Обратите внимание на такие свойства как «-fs-pdf-font-embed: embed;» и «-fs-pdf-font-encoding: Identity-H;», эти свойства необходимы, их просто не забывайте добавлять.
@ page — это правило, которое задает отступы для PDF документа, ну и его размер. Здесь хотелось бы отметить, что если Вы укажите размер страницы A3 (а как показывает практика, это часто необходимо, т.к. страница не помещается в документ по ширине), то это не значит, что пользователю необходимо будет распечатывать документ (при желании) в формате A3, скорее просто весь контент будет пропорционально уменьшен/увеличен до желаемого (чаще A4). Т.е. относитесь к значению свойства size скептически, но знайте, что оно может сыграть для Вас ключевую роль.
@ media — правило, позволяющее создавать CSS классы для определенного типа устройств, в нашем случае это «print». Внутри этого правила мы создали класс, после которого наш генератор PDF документа создаст новую страницу.
Сервлет:
Кстати, совсем не обязательно писать для этих целей сервлет, Вы можете перенести логику этого сервлета хоть в консольное приложение, которое будет сохранять PDF документы в файлы. Как Вы могли заметить, в сервлете не нужно ничего настраивать, менять, дополнять, и т.д. (ну за исключением пути до страницы и, возможно, кодировки), соответственно вся работа по подготовке PDF документа очень проста и происходит исключительно во вьюшке.
Источник
Converting HTML to PDFs in Android
You can use HtmlToPdfConverter to generate PDFs from an HTML file or HTML string. PSPDFKit utilizes full power of the system WebView when generating PDF files from HTML, allowing you to use CSS, embed images, use JavaScript, or take advantage of a variety of modern HTML features.
ℹ️ Note: Using these APIs requires the HTML-to-PDF conversion feature in your license.
Performing the Conversion
Here’s an example that shows how to convert a simple HTML string to PDF:
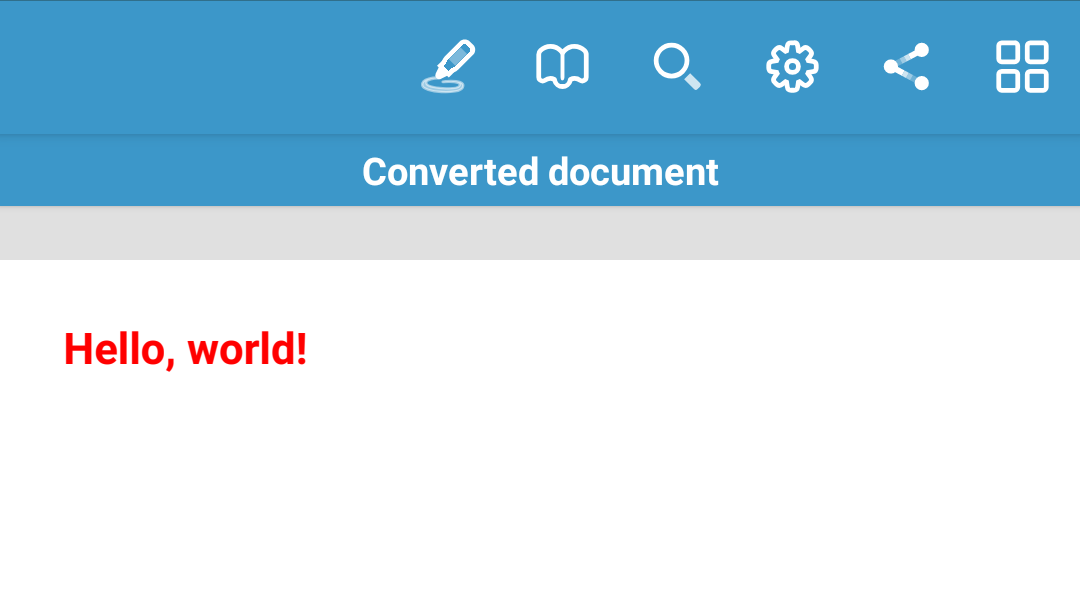
In addition to providing source HTML from a string, you can also load your data from URIs by creating a converter via the factory method HtmlToPdfConverter#fromUri() . Both local and remote URIs are supported:
Local URIs with the file scheme for local files and content scheme for data are provided by the content provider. Note that the file scheme can also refer to the Android resources ( file:///android_res/ ) and assets ( file:///android_asset ) that are also supported.
Remote URIs with the schemes http and https .
For more details about how to generate PDF files from HTML strings and URLs, take a look at HtmlToPdfConverter documentation and ConvertHtmlToPdfExample from our Catalog app.
Controlling the Conversion
HtmlToPdfConverter provides basic control over the generated PDF. This includes:
pageSize() to configure the page size of the created PDF. Defaults to A4 page size.
density() to control density used when converting HTML images to PDF. Defaults to 300dpi.
title() to configure the document title of the created PDF. Defaults to null title.
There are also multiple methods for controlling the conversion itself:
timeout() configures a timeout for loading the HTML page before conversion. Once this timeout is reached, the conversion fails with an error. Defaults to 30,000 ms (or 30 seconds).
setJavaScriptEnabled() controls whether or not JavaScript execution should be enabled while converting. Defaults to enabled. Note that the JavaScript execution could cause security and performance issues. Please review your JavaScript carefully or consider disabling this property.
Observing the Conversion Progress
If you wish to observe the HTML page loading progress (for example, when loaded from the network), use setPageLoadingProgressListener() to register the page loading progress listener:
Intercepting Loaded Resources
HtmlToPdfConverter will try to resolve and load all resources referenced by the source HTML document. This includes but isn’t limited to images, stylesheets, and JavaScript (if enabled).
You can provide otherwise inaccessible resources or override default resource loading by registering ResourceInterceptor via setResourceInterceptor() :
ℹ️ Note: The resource interceptor’s method — shouldInterceptRequest() — is invoked for most supported URI schemes ( http(s) , file , etc.) and isn’t limited to requests made over the network. This isn’t called for javascript , data , and blob schemes or for Android assets ( file:///android_asset/ ) or Android resources ( file:///android_res/ ).
Troubleshooting
Since we rely on the system-provided WebView for rendering PDFs, sometimes the final output won’t match what’s expected. In this case, you should check the following:
Is your WebView up to date? Depending on your OS version, either the Android System Webview or Chrome will be responsible for providing the WebView , so make sure they are up to date.
If there are no updates for either of the above, check if updating to a beta build of the WebView as described here will solve your issue.
Should the rendering still not match your expectations, feel free to contact us.
Источник
aspose-com-gists / convert-html-to-password-protected-pdf.java
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| // Create HTML load options |
| HtmlLoadOptions htmloptions = new HtmlLoadOptions (); |
| // Load HTML file |
| Document doc = new Document ( » HTML-Document.html » , htmloptions); |
| // Set passwords and encryption PDF document |
| doc . encrypt( » userpassword » , » ownerPassword » , Permissions . ModifyContent , CryptoAlgorithm . AESx256 ); |
| // Save HTML file as PDF |
| doc . save( » HTML-to-PDF.pdf » ); |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| // Create and initialize URL |
| URL oracleURL = new URL ( » https://docs.oracle.com/javase/tutorial/networking/urls/readingURL.html » ); |
| // Get web page as input stream |
| InputStream is = oracleURL . openStream(); |
| // Initialize HTML load options |
| HtmlLoadOptions htmloptions = new HtmlLoadOptions (); |
| // Load stream into Document object |
| Document pdfDocument = new Document (is, htmloptions); |
| // Save output as PDF format |
| pdfDocument . save( » HTML-to-PDF.pdf » ); |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| // Create HTML load options |
| HtmlLoadOptions htmloptions = new HtmlLoadOptions (); |
| // Load HTML file |
| Document doc = new Document ( » HTML-Document.html » , htmloptions); |
| // Convert HTML file to PDF |
| doc . save( » HTML-to-PDF.pdf » ); |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Источник
iText HTML to PDF Example
Posted by: Chandan Singh in Core Java November 16th, 2015 7 Comments Views
In the previous examples, we have studied about various Itext Classes like PDFTable, PDFStamper,PDFRectangle etc. that help us in creation of the PDF document. In this example, we will demonstrate when we already have a document in HTML format and need to convert it to a PDF Document.
1. Project Set-Up
We shall use Maven to setup our project. Open eclipse and create a simple Maven project and check the skip archetype selection checkbox on the dialogue box that appears. Replace the content of the existing pom.xml with the pom.xml below:
In this example, we have added one more dependency for the Xmlworker JAR. That’s all from setting-up project point of view, let’s start with the actual code writing now:
2. Implementation
We will convert the below HTML document into a PDF document:
Here’s the how the document looks like in a browser(CHROME here):
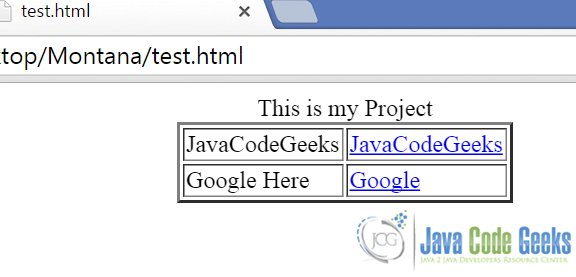
Fig 1 : HTML Document
The com.itextpdf.tool.xml.XMLWorkerHelper converts the XHTML code to PDF. The Xhtml is a stricter version of HTML which ensures the document are well-formed and hence can be parsed efficiently by the standard XML parsers. Not closing the tags or any other syntax errors can lead to exception like :
Now that we are clear with the basics let’s write the code for the actual conversion:
We create an instance of the Document and FileOutputStream and pass it the PDFWriter . Now we create a StringBuilder object which holds the HTML source code. The XMLWorker class accepts the Byte Array of the HTML source code. XMLWorkerHelper.getInstance().parseXHtml() method parses the HTML source code and writes to the document created earlier via the PDFWriter instance.
Here’s how the converted PDF document looks like:

Fig 2 : Html to PDF Document
3. Download the Source Code
Here, we demonstrated how we can convert a HTML Document to PDF format using the Itext library.
Источник
Android java html to pdf
OPEN HTML TO PDF

Open HTML to PDF is a pure-Java library for rendering a reasonable subset of well-formed XML/XHTML (and even some HTML5) using CSS 2.1 (and later standards) for layout and formatting, outputting to PDF or images.
Use this library to generated nice looking PDF documents. But be aware that you can not throw modern HTML5+ at this engine and expect a great result. You must special craft the HTML document for this library and use it’s extended CSS feature like #31 or #32 to get good results. Avoid floats near page breaks and use table layouts.
- Integration guide — get maven artifacts and code to get started.
- 1.0.10 Online Sandbox — Now with logs!
- Templates for Openhtmltopdf — MIT licensed templates that work with this project. Updated 2021-09-21.
- Showcase Document — PDF
- Documentation wiki
- Template Author Guide — PDF — DEPRECATED — Prefer wiki — Moving info to wiki
- Sample Project — Pretty Resume Generator
DIFFERENCES WITH FLYING SAUCER
- Uses the well-maintained and open-source (LGPL compatible) PDFBOX as PDF library, rather than iText.
- Proper support for generating accessible PDFs (Section 508, PDF/UA, WCAG 2.0).
- Proper support for generating PDF/A standards compliant PDFs.
- New, faster renderer means this project can be several times faster for very large documents.
- Better support for CSS3 transforms.
- Automatic visual regression testing of PDFs, with many end-to-end tests.
- Ability to insert pages for cut-off content.
- Built-in plugins for SVG and MathML.
- Font fallback support.
- Limited support for RTL and bi-directional documents.
- On the negative side, no support for OpenType fonts.
- Footnote support.
- Much more. See changelog below.
Open HTML to PDF is distributed under the LGPL. Open HTML to PDF itself is licensed under the GNU Lesser General Public License, version 2.1 or later, available at http://www.gnu.org/copyleft/lesser.html. You can use Open HTML to PDF in any way and for any purpose you want as long as you respect the terms of the license. A copy of the LGPL license is included as license-lgpl-2.1.txt or license-lgpl-3.txt in our distributions and in our source tree.
An exception to this is the pdf-a testing module, which is licensed under the GPL. This module is not distributed to Maven Central and is for testing only.
Open HTML to PDF uses a couple of FOSS packages to get the job done. A list of these can be found in the dependency graph.
Open HTML to PDF is based on Flying-saucer. Credit goes to the contributors of that project. Code will also be used from neoFlyingSaucer
- OPEN HTML TO PDF is tested with OpenJDK 8, 11 and 17 (early access). It requires at least Java 8 to run.
- No, you can not use it on Android.
- You should be able to use it on Google App Engine (Java 8 or greater environment). Let us know your experience.
Flowing columns are not implemented.Implemented in RC12.- No, it’s not a web browser. Specifically, it does not run javascript or implement many modern standards such as flex and grid layout.
Test cases, failing or working are welcome, please place them in /openhtmltopdf-examples/src/main/resources/testcases/ and run them from /openhtmltopdf-examples/src/main/java/com/openhtmltopdf/testcases/TestcaseRunner.java .
NOTE: After this release the old slow renderer will be deleted. Fast mode has been the default (since 1.0.5) so you only have to check your code if you are calling the useSlowMode method which will be removed.
- #551SECURITY Fix near-infinite loop for very deeply nested content with page-break-inside: avoid constraint. Thanks for persisting @swillis12 and debugging @syjer.
- #729SECURITY Upgrade xmlgraphics-commons (used in SVG rendering) to avoid CVE. Thanks @electrofLy.
- #711 Footnote support (beta). See footnote documentation on wiki. Thanks for requesting @a-leithner and @slumki.
- #761 CSS property to disable bevels on borders to prevent ugly anti-aliasing effects, especially on table cells. See -fs-border-rendering property on wiki. Thanks for providing sample @gandboy91.
- #103 Output exception class name and message by default for log messages with an associated exception.
- #711 (mixed) Better boxing for ::before and ::after content. Should now be able to define a border around pseudo content correctly.
- #738 Support for additional elements in PDF/UA including art, part, sect, section, caption and blockquote. Thanks @AndreasJacobsen.
- #736 New example of using a dom mutator to implement unsupported content such as font tag attributes. Thanks for requesting @mgabhishek06kodur.
- #707 Fix regression where PDF/UA documents that weren’t also PDF/A compliant were missing Dublin Core metadata. Thanks @mgm-rwagner, @syjer.
- #732 Allow table element to be positioned. Thanks @fcorneli.
- #727 Allow the use of an initial page number for page and pages counters. Thanks for PR @fanthos.
SECURITY RELEASE: This release was brought forward due to security releases of the PDFBOX and Batik dependencies.
- #722 Upgrade PDFBOX (to 2.0.24) — avoids CVEs in earlier versions and PDFBoxGraphics2D. Thanks a lot @rototor.
- #678 Upgrade Batik Version to 1.14 (CVE-2020-11987) — Again it is strongly advised to avoid untrusted SVG and XML. Thanks @rototor.
- #716 Replace rogue println calls with log calls. Thanks @syjer for PR, @tfo for reporting.
- #708 Allow shape-rendering SVG CSS property. Thanks @syjer for PR, @RAlfoeldi for reporting.
- #703 Remove calls to deprecated method calls in JRE standard library. May change XML reader class. Implemented by @danfickle.
- #702 Set timeouts for default HTTP/HTTPS handlers. Thanks for reporting @gengzi.
- 162228 Put links to raster images in SVGs through the URL resolver.
- #694 Fix incorrect B3 paper size. Thanks @lfintalan for reporting with line number!
- ab48fd Do not log a missing font more than once.
NOTE: PDFBOX CVEs relate to the loading of untrusted PDFs in PDFBOX and thus this project is not directly affected. However, it is not a good idea to have CVEs on your classpath.
SECURITY RELEASE
- #675 Update PDFBOX to 2.0.23 to avoid CVEs. Thanks for reporting @Samuel3.
NOTE: These CVEs relate to the loading of untrusted PDFs in PDFBOX and thus this project is not directly affected. However, it is not a good idea to have CVEs on your classpath.
- #650 Support for multiple background images on the one element. Thanks for requesting @baedorf.
- #669 Support fallback fonts. Thanks for requesting @asu2 and assisting @draco1023.
- #640 Implement file embeds via the download attribute on links. Thanks for original PR @syjer and for requesting @lindamarieb and @vader.
- #666 API to get the bottom-most y position of rendered content to be able to position follow on content with other tools. Thanks for extensive reviewing of PR @stechio and for request by @DSW-AK.
- #664 Improved support for PDF/A and PDF/UA standards. Thanks for PR @qligier.
- #653 Fix for inline-block elements with a z-index or transform were being output twice. Thanks for reporting @hannes123bsi.
- #655 Correct layout of ordered lists in RTL direction. Thanks for PR @johnnyaug.
- #658 Implement target-text function for content property. Thanks for PR @BenjaminVega.
- #647 Fix race condition in setting up logger in multi-threaded environments. Thanks for PR @syjer.
- #638 Ability to plug-in external resource control based on resource type and url. Thanks for original PR @syjer.
- #628 Use enhanced image embedding methods from PDF-BOX. Thanks for PR @rototor and your work in PDF-BOX implementing this.
- #627 Fix regression where a null font style was causing NPE. Thaks for PR @rototor.
- #338 Implement read-only radio button group. Thanks for investigating, reporting and patience @ThoSchCon, @aleks-shbln, @dmitry-weirdo, @syjer and @paulito-bandito.
IMPORTANT: #615 This is a bug fix release for an endless loop issue when using break-word with floating elements with a top/bottom margin.
- #624 Update PDFBOX to 2.0.22 and pdfbox-graphics2d to 0.30. Thanks @rototor.
- #467 Prevent possibility of CSS import loop.
- #621 Allow spaces in data uris. Thanks @syjer.
SECURITY: #609 Updates Apache Batik SVG renderer to latest version to avoid security issue. If you are using this project to render untrusted SVGs (advised against), you should update immediately. Thanks a lot @halvorbmundal.
IMPORTANT: The fast renderer is now the default in preparation of removing the old slow renderer. To temporarily use the slow renderer, you can call the deprecated method builder.useSlowMode() (PDF output only).
IMPORTANT: #543 This version stays on PDFBOX version 2.0.20 due to a bug with non-breaking spaces in version 2.0.21. Please make sure version 2.0.21 is not on your classpath. This bug has been fixed in the upcoming 2.0.22.
Источник



