- Map (Отображение)
- Набор данных интерфейса Map
- Наиболее часто используемые методы интерфейса Map
- Описание Hashtable
- Конструкторы Hashtable
- Дополнительные методы Hashtable
- Набор данных HashMap
- Конструкторы и описание HashMap
- Хэш-таблицы LinkedHashMap
- Конструкторы и описание LinkedHashMap
- Набор данных TreeMap
- Конструкторы и описание TreeMap
- Map в Java с примерами
- Реализация
- Вставка элементов
- Только объекты могут быть вставлены
- Последующие вставки с тем же ключом
- Нулевые ключи не допускаются
- Допустимы нулевые значения
- Вставка всех элементов с другой карты
- Как получить элементы
- Возвращение значения по умолчанию
- Проверка содержится ли ключ
- Проверка содержится ли значение
- Перебор ключей
- Использование ключевого итератора
- Использование цикл for-each
- Использование ключевого потока
- Итерация значений
- Использование Value Iterator
- Использование for-each
- Использование потока
- Итерация записей
- Использование итератора ввода
- Использование For-Each
- Удаление записей
- Удаление всех записей
- Замена записи
- Количество записей
- Проверка, пуста ли карта
- Общие карты
- Функциональные операции
- compute()
- computeIfAbsent()
- computeIfPresent()
- merge()
Map (Отображение)
В контейнерах Map (отображение) хранятся два объекта: ключ и связанное с ним значение. Иногда используют термин «ассоциативный массив» или «словарь».
Map позволяет искать объекты по ключу. Объект, ассоциированный с ключом, называется значением. И ключи, и значения являются объектами. Ключи могут быть уникальными, а значения могут дублироваться. Некоторые отображения допускают пустые ключи и пустые значения.
Классы для карт:
- AbstractMap — абстрактный класс, реализующий большую часть интерфейса Map
- EnumMap — расширяет класс AbstractMap для использования с ключами перечислимого типа enum
- HashMap — структура данных для хранения связанных вместе пар «ключ-значение», применяется для использования хеш-таблицы
- TreeMap — для использования дерева, т.е. отображение с отсортированными ключами
- WeakHashMap — для использования хеш-таблицы со слабыми ключами, отображение со значениями, которые могут удаляться сборщиком мусора, если они больше не используются
- LinkedHashMap — отображение с запоминанием порядка, в котором добавлялись элементы, разрешает перебор в порядке вставки
- IdentityHashMap — использует проверку ссылочной эквивалентности при сравнении документов, отображение с ключами, сравниваемыми с помощью операции == вместо метода equals()
Метод toString() выводит содержимое в виде фигурных скобок, где ключи и значения разделяются знаком равенства. Ключи слева, значения справа.
Отображения не поддерживают реализацию интерфейса Iterable, поэтому нельзя перебрать карту через цикл for в форме for-each.
Интерфейс Map соотносит уникальные ключи со значениями. Ключ — это объект, который вы используете для последующего извлечения данных. Задавая ключ и значение, вы можете помещать значения в объект отображения. После того как это значение сохранено, вы можете получить его по ключу.
В параметре K указывается тип ключей, в V — тип хранимых значений.
- void clear() — удаляет все пары «ключ-значение» из вызывающего отображения
- boolean containsKey(Object k) — возвращает значение true, если вызывающее отображение содержит ключ k. В противном случае возвращает false
- boolean containsValue(Object v) — возвращает значение true, если вызывающее отображение содержит значение v. В противном случае возвращает false
- Set > entrySet() — возвращает набор, содержащий все значения отображения. Набор содержит объекты интерфейса Map.Entry. Т.е. метод представляет отображение в виде набора
- boolean equals(Object o) — возвращает значение true, если параметр o — это отображение, содержащее одинаковые значения. В противном случае возвращает false
- V get(Object k) — возвращает значение, ассоциированное с ключом k. Возвращает значение null, если ключ не найден.
- int hashCode() — возвращает хеш-код вызывающего отображения
- boolean isEmpty() — возвращает значение true, если вызывающее отображение пусто. В противном случае возвращает false
- Set keySet() — возвращает набор, содержащий ключи вызывающего отображения. Метод представляет ключи вызывающего отображения в виде набора
- V put(K k, V v) — помещает элемент в вызывающее отображение, переписывая любое предшествующее значение, ассоциированное с ключом. Возвращает null, если ключ ранее не существовал. В противном случае возвращается предыдущее значение, связанное с ключом.
- void putAll(Map m) — помещает все значения из m в отображение
- V remove(Object k) — удаляет элемент, ключ которого равен k
- int size() — возвращает количество пар «ключ-значение» в отображении
- Collection values() — возвращает коллекцию, содержащую значения отображения.
Основные методы — get() и put(), чтобы получить или поместить значения в отображение.
Интерфейс Sortedmap расширяет интерфейс Map и гарантирует, что элементы размещаются в возрастающем порядке значений ключей.
Интерфейс NavigableMap (Java 7) расширяет интерфейс Sortedmap и определяет поведение отображения, поддерживающее извлечение элементов на основе ближайшего соответствия заданному ключу или ключам.
Интерфейс Map.Entry позволяет работать с элементом отображения.
HashMap обеспечивает максимальную скорость выборки, а порядок хранения его элементов не очевиден. TreeMap хранит ключи отсортированными по возрастанию, а LinkedHashMap хранит ключи в порядке вставки, но не обеспечивает скорость поиска HashMap.
В Android 11 (R) обещают добавить несколько перегруженных версий метода of(), которые являются частью Java 8.
В Android 11 (R) обещают добавить методы ofEntries() и entry(), которые являются частью Java 8.
Источник
Набор данных интерфейса Map
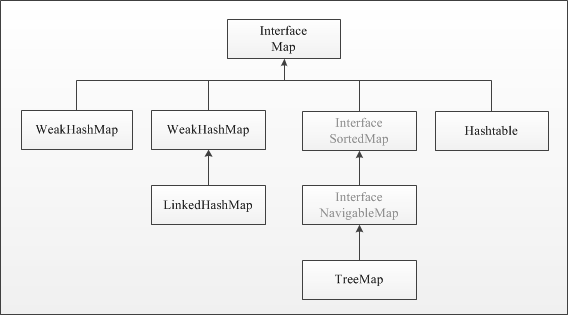
Интерфейс Map располагается на вершине иерархии в Java Collection. Он входит в состав JDK начиная с версии 1.2, предоставляя разработчику базовые методы для работы с данными вида «ключ — значение». Функции интерфейса расширяются вместе с развитием технологий Java. Полную англоязычную документацию интерфейса Map можно найти здесь.
Иерархия интерфейса Map представлена на рисунке.
Наиболее часто используемые методы интерфейса Map
| Метод | Описание |
|---|---|
| void clear() | Очистка хеш-таблицы |
| boolean containsKey(Object key) | Функция проверки присутствия объекта по ключу |
| boolean containsValue(Object value) | Функция проверки присутствия объекта по значению |
| Set > entrySet() | Функция получения объекта в виде коллекции Set |
| boolean equals(Object object) | Функция сравнения с объектом object |
| Object get(Object key) | Функция получения записи по ключу |
| boolean isEmpty() | Функция проверки наличия записей |
| Set keySet() | Функция получения записей в виде коллекции Set |
| void put(K key, V value) | Функция добавления записи |
| void putAll(Map t) | Функция добавления записей |
| void remove(Object key) | Метод удаления объекта по ключу key |
| boolean remove(Object key, Object value) | Функция удаления записи по соответствию значений ключа и значения |
| void replace(K key, V value) | Замена значения value для записи с ключом key |
| boolean replace(K key, V oldValue, V newValue) | Замена значения oldValue на newValue для записи с ключом key |
| int size() | Функция определения количества записей в хеш-таблице |
| Collection values() | Получение значений записей в виде коллекции |
Описание Hashtable
Класс Hashtable позволяет реализовывать структуру данных типа hash-таблица, содержащую пары вида «ключ — значение». Значение «null» в качестве значения или ключа использовать нельзя. Hashtable является синхронизированной, т.е. почти все методы помечены как synchronized, в связи с чем могут быть проблемы с производительностью.
Экземпляр Hashtable включает два параметра, влияющие на его производительность. Это начальная емкость и коэффициент загрузки. Начальная емкость формируется на этапе создания объекта.
Коэффициент загрузки определяет объем информации, по достижении которого емкость Hashtable автоматически будет увеличена. Обычно, значение коэффициента загрузки равно 0.75. Более высокие значения уменьшают издержки пространства, но увеличивают стоимость времени поиска записи.
Полную документацию по Hashtable можно найти здесь.
Конструкторы Hashtable
- Hashtable()
Создание хеш-таблицы с емкостью по умолчанию (11 записей) и коэффициент загрузки по умолчанию (0.75). - Hashtable(int initialCapacity)
Создание хеш-таблицы с указанной начальной емкостью и коэффициентом загрузки по умолчанию (0.75). - Hashtable(int initialCapacity, float loadFactor)
Создание хеш-таблицы с указанной начальной емкостью и указанным коэффициентом загрузки. - Hashtable(Map t)
Создание хеш-таблицы с указанными параметрами.
Дополнительные методы Hashtable
Hashtable реализует все методы интерфейса Map и включает дополнительно следующие методы :
| Метод | Описание |
|---|---|
| Объект clone() | Создание копии хеш-таблицы |
| boolean contains(Object value) | Функция проверки присутствия объекта value в хеш-таблице |
| Enumeration elements() | Получение ключей хеш-таблицы в виде объекта Enumeration |
| Enumeration keys() | Функция получения ключей хеш-таблицы в виде объекта Enumeration |
| void rehash() | реорганизация hash ключей и увеличение емкости |
В качестве примера рассмотрим задачу организации небольшого телефонного справочника с помощью Hashtable, позволяющего использовать механизм хеш-таблиц для эффективного поиска записей по ключу. С помощью метода put программа добавляет новые записи в хеш-таблицу. Извлечение записей выполняется методом get, которому в качестве параметра передается ключ.
Пример телефонного справочника, содержащего имена и телефоны :
Для добавления записей используется метод put, которому в качестве параметров передается «ключ» (первый параметр — имя) и «значение» (второй параметр — телефон). Для чтения списка ключей используется метод keys класса Hashtable, который возвращает объект класса Enumeration.
Условие завершения цикла — возвращение методом hasMoreElements значения «false». С помощью метода nextElement в цикле извлекаются все значения ключей, а затем методом get получаем соответствующие этим ключам значения.
Набор данных HashMap
Набор данных HashMap является альтернативой Hashtable. Основными отличиями от Hashtable являются то, что HashMap не синхронизирован и позволяет использовать null как в качестве ключа, так и значения.
Также как и Hashtable, коллекция HashMap не является упорядоченной: порядок хранения элементов зависит от хэш-функции. Реализация HashMap обеспечивает постоянно-разовую производительность для основных операций (get и put).
У экземпляра HashMap есть два параметра, влияющие на его производительность. Это начальная емкость и коэффициент загрузки. Емкость — это число блоков в хэш-таблице. Начальная емкость определяется при создании хэш-таблицы.
Полную документацию по HashMap можно найти здесь.
Конструкторы и описание HashMap
| Метод | Описание |
|---|---|
| HashMap() | Конструктор с используемыми по умолчанию значениями начальной емкости (16) и коэффициентом загрузки (0.75) |
| HashMap(int initialCapacity) | Конструктор с используемым по умолчанию значением коэффициентом загрузки (0.75) и начальной емкостью initialCapacity |
| HashMap(int initialCapacity, float loadFactor) | Конструктор с используемыми значениями начальной емкости initialCapacity и коэффициентом загрузки loadFactor |
| HashMap(Map m) | Конструктор с определением структуры согласно объекту-параметра. |
Пример использования методов HashMap.
Результат работы программы :
Хэш-таблицы LinkedHashMap
LinkedHashMap — это упорядоченная реализация хэш-таблицы, в которой имеются двунаправленные связи между элементами подобно LinkedList. Это преимущество имеет и недостаток — увеличение памяти, которое занимет коллекция.
Конструкторы и описание LinkedHashMap
| Метод | Описание |
|---|---|
| LinkedHashMap() | Конструктор с используемыми по умолчанию значениями начальной емкости (16) и коэффициентом загрузки (0.75) |
| LinkedHashMap(int initialCapacity) | Конструктор с используемым по умолчанию значением коэффициентом загрузки (0.75) и начальной емкостью initialCapacity |
| LinkedHashMap(int initialCapacity, float loadFactor) | Конструктор с используемыми значениями начальной емкости initialCapacity и коэффициентом загрузки loadFactor |
| LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) | Конструктор с используемыми значениями начальной емкости initialCapacity и коэффициентом загрузки loadFactor. accessOrder — the ordering mode — true for access-order, false for insertion-order |
| LinkedHashMap(Map m) | Конструктор с определением структуры согласно объекта-параметра. |
Полную документацию по LinkedHashMap можно найти здесь.
Пример использования LinkedHashMap :
Результат работы программы :
Набор данных TreeMap
TreeMap, как и LinkedHashMap, является упорядоченным набором данных. По-умолчанию, TreeMap сортируется по ключам с использованием принципа «natural ordering». Но это поведение может быть настроено под конкретную задачу при помощи объекта Comparator, который указывается в качестве параметра при создании объекта TreeMap.
Конструкторы и описание TreeMap
| Метод | Описание |
|---|---|
| TreeMap() | Пустой конструктор создания объекта без упорядочивания данных (using the natural ordering of its keys) |
| TreeMap(Comparator comparator) | Конструктор создания объекта с упорядочиванием значений согласно comparator |
| TreeMap(Map m) | Конструктор с определением структуры согласно объекту-параметра |
| TreeMap(SortedMap m) | Конструктор с определением структуры и сортировки согласно объекту-параметра. |
Полную документацию по TreeMap можно найти здесь.
Источник
Map в Java с примерами
Интерфейс Java Map, java.util.Map, представляет отображение между ключом и значением. В частности, может хранить пары ключей и значений. Каждый ключ связан с определенным значением. После сохранения на карте вы можете позже найти значение, используя только ключ.
Интерфейс не является подтипом интерфейса Collection. Следовательно, он немного отличается от остальных типов коллекций.
Реализация
Поскольку Map является интерфейсом, вам необходимо создать конкретную реализацию интерфейса для его использования. API коллекций содержит следующие:
- java.util.HashMap;
- java.util.Hashtable;
- java.util.EnumMap;
- Jawakutilkidentity ः ashanap;
- Jawakutilklaidaked ः ashanap;
- java.util.Properties;
- java.util.TreeMap;
- java.util.WeakHashMap.
Наиболее часто используемые реализации – это HashMap и TreeMap. Каждая из них ведет себя немного по-разному в отношении порядка элементов при итерации карты и времени (большая запись 0), необходимого для вставки и доступа к элементам в картах.
- HashMap отображает ключ и значение. Это не гарантирует какой-либо порядок элементов, хранящихся внутри карты.
- TreeMap также отображает ключ и значение. Кроме того, он гарантирует порядок, в котором ключи или значения повторяются – это порядок сортировки.
Вот несколько примеров того, как создать экземпляр:
Вставка элементов
Чтобы добавить элементы, вы вызываете ее метод put(). Вот несколько примеров:
Три вызова put() отображают строковое значение на строковый ключ. Затем вы можете получить значение, используя этот ключ.
Только объекты могут быть вставлены
Только объекты могут быть использованы в качестве ключей и значений. Если вы передаете примитивные значения (например, int, double и т. Д.) в качестве ключа или значения, они будут автоматически упакованы перед передачей в качестве параметров. Вот пример параметров примитива auto-boxing, передаваемых методу put():
Значение, переданное методу put() в приведенном выше примере, является примитивом int. Java автоматически упаковывает его внутри экземпляра Integer, поскольку для put() в качестве ключа и значения требуется экземпляр Oject. Автобокс также может произойти, если вы передадите примитив в качестве ключа.
Последующие вставки с тем же ключом
Заданный ключ может появляться на карте только один раз. Это означает, что только одна пара ключ + значение для каждого из них может существовать одновременно. Другими словами, для ключа «key1» в одном экземпляре может храниться только одно значение. Конечно, вы можете хранить значения одного и того же ключа в разных экземплярах карты.
Если вы вызываете put() более одного раза с одним и тем же ключом, последнее заменяет существующее значение для данного ключа.
Нулевые ключи не допускаются
Обратите внимание, что ключ не может быть нулевым!
Карта использует методы ключа hashCode() и equals() для внутреннего хранения пары ключ-значение, поэтому, если ключ имеет значение null, карта не может правильно разместить пару внутри.
Допустимы нулевые значения
Значение пары ключ + значение, хранящееся на карте, может быть нулевым, так что это совершенно правильно:
Просто имейте в виду, что вы получите null, когда позже вызовете get() с этим ключом:
Переменная value будет иметь значение null после выполнения этого кода, если нулевое значение было вставлено для этого ключа ранее (как в предыдущем примере).
Вставка всех элементов с другой карты
Интерфейс имеет метод putAll(), который может копировать все пары ключ-значение (записи) из другого экземпляра в себя. В теории множеств это также называется объединением двух экземпляров Map .
После выполнения этого кода карта, на которую ссылается переменная mapB, будет содержать обе записи ключ + значение, вставленные в mapA в начале примера кода.
Копирование записей идет только в одну сторону. Вызов mapB.putAll(mapA) будет копировать только записи из mapA в mapB, а не из mapB в mapA. Чтобы скопировать записи другим способом, вам нужно будет выполнить код mapA.putAll(mapB).
Как получить элементы
Чтобы получить определенный элемент вы вызываете его метод get(), передавая ключ для этого элемента в качестве параметра:
Обратите внимание, что метод get() возвращает Java-объект, поэтому мы должны привести его к String(поскольку мы знаем, что значение является String). Позже в этом руководстве по Java Map вы увидите, как использовать Java Generics для ввода Map, чтобы она знала, какие конкретные типы ключей и значений она содержит. Это делает ненужным приведение типов и усложняет случайное добавление неправильных значений в карту.
Возвращение значения по умолчанию
Интерфейс имеет метод getOrDefault(), который может возвращать значение по умолчанию, предоставленное вами – в случае, если никакое значение не сохранено с помощью данного ключа:
В этом примере создается карта и в ней хранятся три значения с использованием ключей A, B и C. Затем вызывается метод Map getOrDefault(), передавая в качестве ключа строку String E вместе со значением по умолчанию – значением String по умолчанию. Поскольку карта не содержит объектов, хранящихся в ключе E, будет возвращено заданное значение по умолчанию.
Проверка содержится ли ключ
Используется метод containsKey():
После выполнения этого кода переменная hasKey будет иметь значение true, если пара ключ + значение была вставлена ранее с помощью строкового ключа 123, и false, если такая пара ключ + значение не была вставлена.
Проверка содержится ли значение
Используется метод containsValue():
После выполнения этого кода переменная hasValue будет содержать значение true, если пара ключ-значение была вставлена раньше, со строковым значением «значение 1», и false, если нет.
Перебор ключей
Существует несколько способов итерации ключей, хранящихся на карте. Наиболее часто используемые методы:
- С помощью ключа Iterator.
- Через цикл for-each.
- Через поток.
Все методы будут рассмотрены в следующих разделах.
Использование ключевого итератора
С помощью метода keySet():
Как вы можете видеть, ключ Iterator возвращает каждый ключ, сохраненный в Map, один за другим (по одному для каждого вызова next()). Получив ключ, вы можете получить элемент, сохраненный для этого ключа, с помощью метода get().
Использование цикл for-each
В Java 5 вы также можете использовать цикл for-each для итерации ключей, хранящихся на карте:
Эффект приведенного выше кода очень похож на код, показанный в предыдущем разделе.
Использование ключевого потока
Интерфейс Stream является частью Java Stream API, который был добавлен в Java 8. Сначала вы получаете ключ Set из карты, и из него вы можете получить Stream:
Итерация значений
Также возможно просто перебрать значения, хранящиеся в Map, с помощью метода values(). Варианты:
- Использование итератора.
- Использование цикла.
- Использование потока значений.
Все эти параметры описаны в следующих разделах.
Использование Value Iterator
Первый способ – это получить экземпляр итератора значения из значения Set и выполнить итерацию:
Поскольку набор неупорядочен, у вас нет никаких гарантий относительно порядка, в котором значения повторяются.
Использование for-each
Второй метод – это цикл Java for-each:
В этом примере будут распечатаны все значения, хранящиеся в переменной mapA MapA.
Использование потока
Подразумевает использование потока значений с помощью API-интерфейса Stream. Сначала вы получаете значение Set из карты, а из значения Set вы можете получить поток:
Итерация записей
Под записями подразумеваются пары ключ + значение. Существует два способа:
- Использование итератора ввода.
- Использование цикла for-each.
Обе эти опции будут объяснены в следующих разделах.
Использование итератора ввода
Обратите внимание, как ключ и значение могут быть получены из каждого экземпляра Map.Entry.
Имейте в виду, что приведенный выше код можно сделать немного лучше, используя Map, типизированную с помощью Generics, как показано далее в этом руководстве.
Использование For-Each
Обратите внимание, что этот пример тоже можно сделать немного красивее, используя универсальную карту.
Удаление записей
Вы удаляете записи, вызывая метод remove(Object key). Таким образом, вы удаляете пару (ключ, значение), соответствующую ключу:
После выполнения этой инструкции карта, на которую ссылается mapA, больше не будет содержать запись (пара ключ + значение) для ключа key1.
Удаление всех записей
Используется метод clear():
Замена записи
Можно заменить элемент, используя метод replace(). Он будет вставлять новое значение только в том случае, если к ключу сопоставимо существующее значение. В ином случае никакое значение не вставлено. Это отличается от того, как работает метод put(), который всегда вставляет значение, несмотря ни на что.
После выполнения этого кода экземпляр Map будет содержать более новое значение String для ключа String.
Количество записей
Вы можете узнать количество записей, используя метод size(). Количество записей в Java-карте также называется размером карты – отсюда и имя метода size(). Вот пример:
Проверка, пуста ли карта
Интерфейс имеет специальный метод для проверки isEmpty() и возвращает:
- true, если экземпляр Map содержит 1 или более записей;
- если карта содержит 0 записей, isEmpty() вернет false.
Общие карты
По умолчанию вы можете поместить любой объект в карту, но Generics из Java 5 позволяет ограничить типы объектов, которые вы можете использовать как для ключей, так и для значений в карте:
Эта карта теперь может принимать только объекты String для ключей и экземпляры MyObject для значений. Затем вы можете получить доступ к итерированным ключам и значениям без их приведения. Вот как это выглядит:
Функциональные операции
Интерфейс имеет несколько функциональных операций, добавленных из Java 8. Они позволяют взаимодействовать с Map в более функциональном стиле. Например, вы передаете лямбда-выражение в качестве параметра этим методам. Функциональные методы работы:
compute()
Метод принимает ключевой объект и лямбда-выражение в качестве параметров. Лямбда-выражение должно реализовывать интерфейс java.util.function.BiFunction. Вот пример:
- Метод compute() будет вызывать лямбда-выражение внутри себя, передавая ключевой объект и любое значение, сохраненное в Map для этого ключевого объекта, в качестве параметров лямбда-выражения.
- Какое бы значение не возвращалось лямбда-выражением, оно сохраняется вместо текущего значения этого ключа. Если лямбда-выражение возвращает ноль, запись удаляется. Там не будет ключа -> нулевое отображение хранится на карте.
- Если лямбда-выражение выдает исключение, запись также удаляется.
В приведенном выше примере вы можете видеть, что лямбда-выражение проверяет, является ли значение, сопоставленное данному ключу, нулевым или нет, перед вызовом toString(). ToUpperCase() для него.
computeIfAbsent()
Метод Map computeIfAbsent() работает аналогично методу compute():
- Лямбда-выражение вызывается, только если для данного ключа уже не существует записи.
- Значение, возвращаемое лямбда-выражением, вставляется в карту. Если возвращается ноль, запись не вставляется.
- Если лямбда-выражение генерирует исключение, запись также не вставляется.
Этот пример на самом деле просто возвращает постоянное значение – строку 123. Однако лямбда-выражение могло вычислить значение любым необходимым способом – например, извлечь значение из другого объекта или объединить его с другими значениями и т. д.
computeIfPresent()
Метод работает противоположно computeIfAbsent(). Он вызывает только лямбда-выражение, переданное ему в качестве параметра, если в Map уже существует запись для этого ключа:
- Значение, возвращаемое лямбда-выражением, будет вставлено в экземпляр Map.
- Если лямбда-выражение возвращает ноль, запись для данного ключа удаляется.
- Если лямбда-выражение выдает исключение, оно перебрасывается, и текущая запись для данного ключа остается неизменной.
merge()
Метод принимает в качестве параметров ключ, значение и лямбда-выражение, реализующее интерфейс BiFunction.
- Если в карте нет записи для ключа или если значение для ключа равно нулю, значение, переданное в качестве параметра методу merge(), вставляется для данного ключа.
- Однако, если существующее значение уже сопоставлено с данным ключом, вместо этого вызывается лямбда-выражение, переданное как параметр. Таким образом, лямбда-выражение получает возможность объединить существующее значение с новым значением. Значение, возвращаемое им, затем вставляется в карту для данного ключа.
- Если лямбда-выражение возвращает ноль, запись для данного ключа удаляется.
- Если в лямбда-выражении выдается исключение, оно перебрасывается, и текущее отображение для данного ключа сохраняется без изменений.
В этом примере будет вставлено значение XYZ в карту, если значение не сопоставлено с ключом (123) или если значение NULL сопоставлено с ключом. Если ненулевое значение уже сопоставлено с ключом, вызывается лямбда-выражение. Лямбда-выражение возвращает новое значение (XYZ) + значение -abc, что означает XYZ-abc.
Источник



