Библиотека jsoup — Суп с котом

Вместо предисловия
Первоначально статья писалась, когда деревья были большими, коты были котятами, Android был версии 2.3, а библиотека jsoup была версии 1.6.1.
С тех пор утекло много воды. Хорошая новость — библиотека подросла до версии 1.13.1, стала чуть меньше размером, стала быстрее работать (почти в два раза). Плохая новость — мои примеры, связанные с интернетом, перестали работать в Android 4.0, так как теперь явно запретили использовать сетевые операции в основном потоке.
Я оставлю старую версию статьи здесь. Если вы пишете программы под старые устройства, то всё остаётся без изменений. Примеры под новые устройства находятся в закрытой зоне 4 курса.
Общая информация
Рассмотрим примеры работы с библиотекой jsoup. Java-библиотека jsoup предназначена для разбора HTML-страниц (парсинг), позволяя извлечь необходимые данные, используя DOM, CSS и методы в стиле jQuery.
Библиотека поддерживает спецификации HTML5 и позволяет парсить страницы, как это делают современные браузеры.
Библиотеке можно подсунуть для анализа URL, файл или строку.
Подключаем библиотеку
В Android Studio пропишите в файле build.gradle строку в блоке зависимостей.
Создаём новый проект JsoupDemo. Добавляем на форму кнопку и TextView.
После установки библиотеки вам нужно получить документ для разбора текста. Это может быть страница на сайте или локальный файл на устройстве. Таким образом вам надо подключиться к нужной странице и получить объект класса Document. При импортировании обращайте внимание на полное название класса org.jsoup.nodes.Document, так как многие пакеты имеют в своём составе одноимённый класс.
Получив документ в своё распоряжение, вы можете извлекать требуемую информацию. Например, вы можете получить все теги meta:
Метод select() позволяет получить нужные теги.
Если нужно получить атрибут тега, то используйте метод attr():
Можно выбрать теги с заданным классом. Например, на странице встречается тег типа
Первый пример для знакомства
Для первого знакомства разберём простой пример. А потом будем его усложнять. Создадим переменную, содержащий html-текст. Далее вызываем библиотеку jsoup и смотрим на результат.
Запустите проект и нажмите на кнопку. На экране отобразится наш текст. Но если вы присмотритесь внимательнее, то заметите некоторые отличия (скорее всего вы и не заметили). Я намеренно сделал две «ошибки». Во-первых, я не закрыл тег , а также не закрыл тег
у первого параграфа. Однако библиотека сама подставила недостающие элементы. Именно так поступают и браузеры, если веб-мастер по невнимательности забывает ставить закрывающие парные теги.

Что мы сделали? Мы передали нужный html-текст библиотеке Jsoup и попросили его осуществить его разбор (метод parse()). В результате мы получаем экземпляр класса Document, из которого с помощью метода html() извлекаем уже обработанный текст, с которым можно работать дальше.
Если у вас всё получилось, то можно перейти к более сложным примерам. Подробная документация по методам и свойствам есть на сайте библиотеки. Вам нужно только пробовать.
Извлекаем заголовок страницы
Заголовок страницы находится в теге . Чтобы получить текст заголовка, воспользуемся методом Document.title():
Извлекаем ссылки
Теперь попробуем поработать с ссылками. В нашем тексте есть ссылка, которую можно разбить на несколько логических элементов: адрес, на который ведёт ссылка, текст в ссылке и полная ссылка, которая объединяет оба элемента.
Начнём с адреса ссылки:
Чтобы получить текст ссылки:
И, наконец, общий вариант:
Разбор текста с сайта
Некоторые несознательные граждане могут меня обвинить в том, что я использовал синтетический пример, специально подготовленный для демонстрации. И хотят видеть пример с использованием ваших тырнетов. Ну что ж, вот вам пример.
Я подключаюсь к самой известной странице в мире http://developer.alexanderklimov.ru/android/ и получаю его заголовок.
Не забудьте установить разрешение на подключение к Интернету вашей программе. Я сам сначала долго тупил, не понимая, почему моя программа вылетала с ошибкой. Но, посмотрев в честные глаза своего кота, я понял в чем моя ошибка и исправил ее. Коты рулят.
Разбор текста из файла
Последний пример, который мы не разобрали — это разбор текста из файла. В этом случае используется метод Jsoup.parse(File in, String charsetName, String baseUri):
Попробуйте самостоятельно. Удачи в программировании! Да пребудет с вами кот!
Источник
Getting Started with JSOUP in Android

Nov 22, 2017 · 3 min read

Jsoup is a Java html parser. It is a Java library that is used to parse html documents. Jsoup gives programming interface to concentrate and control information from URL or HTML documents. It utilizes DOM, CSS and Jquery-like systems for concentrating and controlling records.
In this tutorial, you will get to know few steps to start with in parsing html document in an android application interface using Jsoup.
Update
Kindly note that this implementation might not be useful anymore. You can check out for articles that explain this with latest technologies. Thanks! 🙂
Example
This simple android application shows details of Firebase with Jsoup used to parse the logo and title from the web page.
Let’s get s t arted. Create a new android project with an Empty Activity.
Add Jsoup dependency to the app level of your build.gradle file since this is an external library.
Add Internet permission to the Android Manifest file for internet access.
Prepare a layout to display the data that will be fetched from the web page. For example, logo and title.
Go to your MainActivity.java class, in the OnCreate() method, initialize your views. Create an AsyncTask class that will be used to fetch the data in the background before displaying it on the main thread.
Let me explain some lines of codes and elements of Jsoup before calling them in the AsyncTask class.
In the above codes;
Document document = Jsoup.connect(url).get(): Document is a Jsoup node API element used in connecting to the website.
Element img = document.select(“img”).first() : allows the program check through the webpage to get the first since logo is usually placed at the very beginning of the code.
String imgSrc = img.absUrl(“src”): allows the program check through absolute attribute ‘src’ of and get the respective URL.
InputStream input = new java.net.URL().openStream(imgSrc): this downloads the logo from the url.
Bitmap bitmap = BitmapFactory.decodeStream(input): this code creates the logo bitmap.
String title = document.title(): this automatically gets the title of the website.
These lines of codes work at the background process in the doInBackground() method and the respective results are displayed in the onPostexecute() method. Then the AsyncTask class is called to execute in the onCreate() method.
Running the application gives;
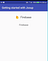
This brings us to the end of the tutorial… So far, Jsoup provides a very convenient API for extracting and manipulating data.
Источник
«Правильный» html парсинг

Первый раз я запустил Eclipse еще весной, почитал книжки на английском, поставил SDK, немного поигрался и забросил. В начале зимы я купил себе первый смартфон на базе Android, но вновь вернутся к разработке меня подтолкнул недавний пост, в котором говорилось, что можно обойтись и знанием C#, с которым в отличии от Java я знаком. Мне было достаточно одного вечера, чтобы понять, что за связку Visual Studio и Monodroid я больше не сяду, позже я прочитал этот пост, где полностью согласился с автором.
После небольшого вступления перейду к теме топика. Довольно большое количество приложений под мобильные устройства взаимодействуют с сайтами и не секрет, что порой нужно получить какую-то информацию со страницы — это может быть курс валют или что-нибудь другое, и нет никакого желания делать это посредством браузера.
Большинство разработчиков, получают html код страницы и перегоняют его в xml, что является неправильным подходом, так как html является «правильным» xml не всегда, вроде на хабре писали, что для браузера не обязателен тег html (современный браузер и без него должен отобразить страницу) или просто будут ошибки, тогда на помощь приходят библиотеки. Из них я выбрал HtmlCleaner.
Под катом я расскажу, как подключить эту библиотеку, а также напишем простой парсер stackoverflow.com.
Рассказывать как установить Android SDK, Eclipse и ADT Plugin я не буду, если эти слова Вам ничего не говорят, то посетите эти две ссылки:
Installing the SDK
ADT Plugin for Eclipse
Главная страница stackoverflow.com выглядит следующим образом:

Парсить я буду информацию, выделенную красными прямоугольниками.
Всё рассчитано на новичков, поэтому будет много картинок. На данном этапе у Вас должен быть полностью настроенный Eclipse, для создания проекта нажимаем File -> New -> Project… и выбираем Android Project, после чего заполним форму:
Пишу для своего устройства, поэтому выбрал версию 2.2, второй важный параметр — это package name, который должен быть уникальным, принято, что это имя сайта наоборот, плюс название приложения. Тесты создавать не будет, поэтому смело нажимаем Finish. Создался проект, рекомендую Вам изучить какие файлы и где лежат, но по своему опыту скажу, что сразу я малость испугался, того количества файлов, которое появилось при первом запуске Eclipse.
Приступим к редактированию файла res\layout\main.xml, тут я удалю TextView и добавлю два элемента управления: Button и ListView, изменю идентификаторы, для кнопки установлю android:layout_width=«fill_parent» и android:text=«Получить данные». Готовый результат выглядит таким образом:
xml version =»1.0″ encoding =»utf-8″ ? >
LinearLayout xmlns:android =»http://schemas.android.com/apk/res/android»
android:orientation =»vertical»
android:layout_width =»fill_parent»
android:layout_height =»fill_parent» >
Button android:id =»@+id/parse»
android:layout_height =»wrap_content»
android:layout_width =»fill_parent»
android:text =»Получить данные» >
Button >
ListView android:id =»@+id/listViewData»
android:layout_height =»wrap_content»
android:layout_width =»match_parent» >
ListView >
LinearLayout >
* This source code was highlighted with Source Code Highlighter .
Это простейший интерфейс, в случае, если Вы сделаете приложение и решите опубликовать его в маркете, то обязательно его нужно изменить, поставить тот же фон через android:background=»@drawable/Имя_файла_без_расширения» и т.д.
Для парсинга нам понадобиться скачать библиотеку htmlcleaner-2.2.jar, далее её следует подключить добавив в Build Paths. Хороший мануал как это сделать можно найти тут, если у Вас появились какие-то трудности.
Прежде всего нужно указать, что нашему приложению нужен интернет, иначе у Вас ничего не выйдет, добавим в файл AndroidManifest.xml:
uses-permission android:name =»android.permission.INTERNET»/>
Теперь создадим класс HtmlHelper, который будет делать основную работу:
public class HtmlHelper <
TagNode rootNode;
//Конструктор
public HtmlHelper(URL htmlPage) throws IOException
<
//Создаём объект HtmlCleaner
HtmlCleaner cleaner = new HtmlCleaner();
//Загружаем html код сайта
rootNode = cleaner.clean(htmlPage);
>
List getLinksByClass( String CSSClassname)
<
List linkList = new ArrayList ();
//Выбираем все ссылки
TagNode linkElements[] = rootNode.getElementsByName( «a» , true );
for ( int i = 0; linkElements != null && i //получаем атрибут по имени
String classType = linkElements[i].getAttributeByName( «class» );
//если атрибут есть и он эквивалентен искомому, то добавляем в список
if (classType != null && classType.equals(CSSClassname))
<
linkList.add(linkElements[i]);
>
>
В главном классе установим слушателя для кнопки и вызовем асинхронно парсинг с помощью AsyncTask, сразу я делал с помощью создания потока и потом через handler обновлял интерфейс, но прочитал, что это не лучшее решение и лучше для этих целей подходит AsyncTask, также, чтобы было видно, что приложение работает я вызову диалог, который будет информировать о процессе. Собственно главный класс выглядит следующим образом:
public class StackParser extends Activity <
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) <
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
//Находим кнопку
Button button = (Button)findViewById(R.id.parse);
//Регистрируем onClick слушателя
button.setOnClickListener(myListener);
>
//Диалог ожидания
private ProgressDialog pd;
//Слушатель OnClickListener для нашей кнопки
private OnClickListener myListener = new OnClickListener() <
public void onClick(View v) <
//Показываем диалог ожидания
pd = ProgressDialog.show(StackParser. this , «Working. » , «request to server» , true , false );
//Запускаем парсинг
new ParseSite().execute( «http://www.stackoverflow.com» );
>
>;
private class ParseSite extends AsyncTask String , Void, List String >> <
//Фоновая операция
protected List String > doInBackground( String . arg) <
List String > output = new ArrayList String >();
try
<
HtmlHelper hh = new HtmlHelper( new URL(arg[0]));
List links = hh.getLinksByClass( «question-hyperlink» );
for (Iterator iterator = links.iterator(); iterator.hasNext();)
<
TagNode divElement = (TagNode) iterator.next();
output.add(divElement.getText().toString());
>
>
catch (Exception e)
<
e.printStackTrace();
>
return output;
>
//Событие по окончанию парсинга
protected void onPostExecute( List String > output) <
//Убираем диалог загрузки
pd.dismiss();
//Находим ListView
ListView listview = (ListView) findViewById(R.id.listViewData);
//Загружаем в него результат работы doInBackground
listview.setAdapter( new ArrayAdapter String >(StackParser. this ,
android.R.layout.simple_list_item_1 , output));
>
>
>
Если Вы всё делали со мной, то у Вас должна была получится, следующая иерархия файлов:
А после запуска приложение должно выглядеть следующим образом:
Источник



