XML Pull Parser
Рассмотрим парсер XML Pull Parser. Парсер позволяет разбирать XML-документы за один проход. После прохода парсер представляет элементы документа в виде последовательности событий и тегов. На данный момент именно его рекомендует использовать Google в Android-приложениях.
Посмотрим на документ глазами парсера. Он видит следующие элементы документа:
- START_DOCUMENT – начало документа
- START_TAG – начало тега
- TEXT – содержимое элемента
- END_TAG – конец тега
- END_DOCUMENT – конец документа
Каждый документ начинается с события START_DOCUMENT и заканчивается событием END_DOCUMENT. Позиция внутри документа представлена в виде текущего события, которое можно определить, вызвав метод getEventType().
Для последовательного перехода по тегам нужно вызывать метод next(), который перемещает нас по цепочке совпавших (иногда вложенных) событий START_TAG и END_TAG. Можно извлечь имя любого тега при помощи метода getName() и получить текст между каждым набором тегов с помощью метода getNextText().
Чтобы упаковать статический XML-документ вместе с вашим приложением, поместите его в каталог res/xml/. Вы получите возможность обращаться в коде программы к этому документу (операции чтения и записи). Рассмотрим загрузку XML-документа произвольной структуры из ресурсов в код программы.
Создадим пример приложения, способный читать список имён котов и их домашних телефонов, определённых в XML-файле.
В каталоге res создайте подкаталог xml, в котором будет располагаться наш ХМL-файл. В этом файле мы напишем список котов и телефонов, и сохраним его под именем contacts.xml.
Добавим в разметку компонент ListView:
Загрузить созданный файл contacts.xml можно следующим образом:
Метод getXml() возвращает XmlPullParser, который может прочитать загруженный XML-документ в цикле while:
Как это происходит? Запускаем цикл while с условием, что он будет работать пока не достигнет конца документа, т.е. закрывающего корневого тега (END_DOCUMENT).
Далее парсер начинает перемещаться по тегам. Мы говорим ему, что если (if) встретишь тег contact, то передай ему привет добавь в массив текст из первого атрибута. И из второго атрибута. И из третьего атрибута. После чего даём пинка парсеру с помощью метода next(), чтобы он шёл искать дальше.
У элемента contact мы определили три атрибута first_name, last_name и phone, которые загружаются в список. Первые два атрибута разделяем пробелом, а третий атрибут (номер телефона) выводим на новой строке.
Полностью код выглядит следующим образом:

Для закрепления материала изменим структуру документа. Пусть он будет выглядеть следующим образом:
А теперь напишем код, который будет отслеживать все теги при разборе документа и выводить результат в лог.
Принцип тот же. Только на этот раз результат мы не выводим в списке, а просто выводим в лог. Для удобства совместил картинку документа и лог на одном экране, чтобы наглядно показать работу парсера.

Если вы будете брать документ не из ресурсов, а из файла с внешнего накопителя, то получение парсера для обработки документа будет иным:
Это самый простой пример использования парсера для чтения документа из ресурсов. В реальных приложениях вам придётся получать информацию с файла, который находится в интернете.
Источник
Работа с XML
Ресурсы XML и их парсинг
Одним из распространенных форматов хранения и передачи данных является xml . Рассмотрим, как с ним работать в приложении на Android.
Приложение может получать данные в формате xml различными способами — из ресурсов, из сети и т.д. В данном случае рассмотрим ситуацию, когда файл xml хранится в ресурсах.
Возьмем стандартный проект Android по умолчанию и в папке res создадим каталог xml . Для этого нажмем на каталог res правой кнопкой мыши и в контекстном меню выберем New -> Android Resource Directory :
В появившемся окне в качестве типа ресурсов укажем xml :
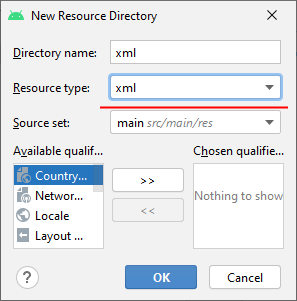
В этот каталог добавим новый файл, который назовем users.xml и который будет иметь следующее содержимое:
Это обычный файл xml, который хранит набор элементов user. Каждый элемент характеризуется наличием двух подэлементов — name и age. Условно говоря, каждый элемент описывает пользователя, у которого есть имя и возраст.
В папку, где находится основной класс MainActivity, добавим новый класс, который назовем User :
Этот класс описывает товар, информация о котором будет извлекаться из xml-файла.
И в ту же папку добавим новый класс UserResourceParser :
Определим для класса UserResourceParser следующий код:
Данный класс выполняет функции парсинга xml. Распарсенные данные будут храниться в переменной users. Непосредственно сам парсинг осуществляется с помощью функции parse . Основную работу выполняет передаваемый в качестве параметра объект XmlPullParser . Этот класс позволяет пробежаться по всему документу xml и получить его содержимое.
Когда данный объект проходит по документу xml, при обнаружении определенного тега он генерирует некоторое событие. Есть четыре события, которые описываются следующими константами:
START_TAG : открывающий тег элемента
TEXT : прочитан текст элемента
END_TAG : закрывающий тег элемента
END_DOCUMENT : конец документа
С помощью метода getEventType() можно получить первое событие и потом последовательно считывать документ, пока не дойдем до его конца. Когда будет достигнут конец документа, то событие будет представлять константу END_DOCUMENT :
Для перехода к следующему событию применяется метод next() .
При чтении документа с помощью метода getName() можно получить название считываемого элемента.
И в зависимости от названия тега и события мы можем выполнить определенные действия. Например, если это открывающий тег элемента user, то создаем новый объект User и устанавливаем, что мы находимся внутри элемента user:
Если событие TEXT , то считано содержимое элемента, которое мы можем прочитать с помощью метода getText() :
Если закрывающий тег, то все зависит от того, какой элемент прочитан. Если прочитан элемент user, то добавляем объект User в коллекцию ArrayList и сбрываем переменную inEntry, указывая, что мы вышли из элемента user:
Если прочитаны элементы name и age, то передаем их значения переменным name и age объекта User:
Теперь изменим класс MainActivity, который будет загружать ресурс xml:
Вначале получаем ресурс xml с помощью метода getXml() , в который передается название ресурса. Данный метод возвращает объект XmlPullParser , который затем используется для парсинга. Для простоты просто выводим данные в окне Logcat :
Источник
Полный список
— парсим XML с помощью XmlPullParser
XmlPullParser – XML-парсер, который можно использовать для разбора XML документа. Принцип его работы заключается в том, что он пробегает весь документ, останавливаясь на его элементах. Но пробегает он не сам, а с помощью метода next. Мы постоянно вызываем метод next и с помощью метода getEventType проверяем, на каком элементе парсер остановился.
Основные элементы документа, которые ловит парсер:
Напишем приложение, которое возьмет xml-файл и разберет его на тэги и аттрибуты.
Project name: P0791_ XmlPullParser
Build Target: Android 2.3.3
Application name: XmlPullParser
Package name: ru.startandroid.develop.p0791xmlpullparser
Create Activity: MainActivity
В папке res создайте папку xml, и в ней создайте файл data.xml:
Это файл с описанием телефона Samsung Galaxy. Указаны его цена, характеристики экрана и возможные цвета корпуса. Данные выдуманы и могут не совпадать с реальностью 🙂
В onCreate мы получаем XmlPullParser с помощью метода prepareXpp и начинаем его разбирать. Затем в цикле while мы запускаем прогон документа, пока не достигнем конца — END_DOCUMENT. Прогон обеспечивается методом next в конце цикла while. В switch мы проверяем на каком элементе остановился парсер.
START_DOCUMENT – начало документа
START_TAG – начало тега. Выводим в лог имя тэга, его уровень в дереве тэгов (глубину) и количество атрибутов. Следующей строкой выводим имена и значения атрибутов, если они есть.
END_TAG – конец тэга. Выводим только имя.
TEXT – содержимое тэга
В методе prepareXpp мы подготавливаем XmlPullParser. Для этого вытаскиваем данные из папки res/xml. Это аналогично вытаскиванию строк или картинок – сначала получаем доступ к ресурсам (getResources), затем вызываем метод, соответствующий ресурсу. В нашем случае это — метод getXml. Но возвращает он не xml-строку , а готовый XmlPullParser.
Все сохраним и запустим приложение.
START_DOCUMENT
START_DOCUMENT
START_TAG: name = data, depth = 1, attrCount = 0
START_TAG: name = phone, depth = 2, attrCount = 0
START_TAG: name = company, depth = 3, attrCount = 0
text = Samsung
END_TAG: name = company
START_TAG: name = model, depth = 3, attrCount = 0
text = Galaxy
END_TAG: name = model
START_TAG: name = price, depth = 3, attrCount = 0
text = 18000
END_TAG: name = price
START_TAG: name = screen, depth = 3, attrCount = 2
Attributes: multitouch = yes, resolution = 320×480,
text = 3
END_TAG: name = screen
START_TAG: name = colors, depth = 3, attrCount = 0
START_TAG: name = color, depth = 4, attrCount = 0
text = black
END_TAG: name = color
START_TAG: name = color, depth = 4, attrCount = 0
text = white
END_TAG: name = color
END_TAG: name = colors
END_TAG: name = phone
END_TAG: name = data
END_DOCUMENT
START_DOCUMENT
START_DOCUMENT
START_TAG: name = data, depth = 1, attrCount = 0
START_TAG: name = phone, depth = 2, attrCount = 0
START_TAG: name = company, depth = 3, attrCount = 0
text = Samsung
END_TAG: name = company
START_TAG: name = model, depth = 3, attrCount = 0
text = Galaxy
END_TAG: name = model
START_TAG: name = price, depth = 3, attrCount = 0
text = 18000
END_TAG: name = price
START_TAG: name = screen, depth = 3, attrCount = 2
Attributes: multitouch = yes, resolution = 320×480,
text = 3
END_TAG: name = screen
START_TAG: name = colors, depth = 3, attrCount = 0
START_TAG: name = color, depth = 4, attrCount = 0
text = black
END_TAG: name = color
START_TAG: name = color, depth = 4, attrCount = 0
text = white
END_TAG: name = color
END_TAG: name = colors
END_TAG: name = phone
END_TAG: name = data
END_DOCUMENT
START_DOCUMENT срабатывает два раза по неведомым мне причинам. Далее можно наблюдать, как парсер останавливается в начале каждого тега и дает нам информацию о нем: имя, уровень (глубина), количество атрибутов, имена и названия атрибутов, текст. Также он останавливается в конце тега и мы выводим имя. В конце парсер говорит, что документ закончен END_DOCUMENT.
Если xml у вас не в файле, а получен откуда-либо, то XmlPullParser надо создавать другим способом. Перепишем метод prepareXpp:
Здесь мы сами создаем парсер с помощью фабрики, включаем поддержку namespace (в нашем случае это не нужно, на всякий случай показываю) и даем парсеру на вход поток из xml-строки (укороченный вариант data.xml).
Все сохраним и запустим. Смотрим лог:
START_DOCUMENT
START_TAG: name = data, depth = 1, attrCount = 0
START_TAG: name = phone, depth = 2, attrCount = 0
START_TAG: name = company, depth = 3, attrCount = 0
text = Samsung
END_TAG: name = company
END_TAG: name = phone
END_TAG: name = data
END_DOCUMENT
Здесь уже START_DOCUMENT сработал один раз, как и должно быть. Ну и далее идут данные элементов документа.
Присоединяйтесь к нам в Telegram:
— в канале StartAndroid публикуются ссылки на новые статьи с сайта startandroid.ru и интересные материалы с хабра, medium.com и т.п.
— в чатах решаем возникающие вопросы и проблемы по различным темам: Android, Kotlin, RxJava, Dagger, Тестирование
— ну и если просто хочется поговорить с коллегами по разработке, то есть чат Флудильня
— новый чат Performance для обсуждения проблем производительности и для ваших пожеланий по содержанию курса по этой теме
Источник
Как парсить XML на Android

На сегодняшний день роль XML (eXtensible Markup Language — расширяемый язык разметки) в программировании огромна: этот формат используется повсеместно во многих языках программирования. В частности, при разработке приложений на Android XML отвечает за то, что пользователь увидит на экране своего смартфона (интерфейс приложения, строковые ресурсы, векторные изображения и т.д.). Кроме того, данный формат зачастую используется для хранения и передачи различных данных.
Именно из-за того, что XML можно использовать как хранилище данных, встаёт вопрос: как с этими данными взаимодействовать, как получать их из XML и отправлять обратно.
Ранее мы говорили о том, что в Android 8.0 Oreo для хранения конфигураций Wi-Fi сетей теперь используется другой файл (подробнее об этом можно почитать здесь). Поскольку этот файл конфигурации как раз нужного нам формата XML, попробуем распарсить его и вытащить их него нужные данные.
Сама структура XML-файла конфигурации выглядит следующим образом:
Нужные нам данные хранятся внутри тега , каждый тег обозначает тип значения, затем внутри в виде атрибутов устанавливаются его название и собственно значение.
Для извлечения данных в Android есть полезный интерфейс XmlPullParser. С его помощью можно в цикле while пройтись построчно по каждому тегу в документе и проверить его содержимое. Каждый проход по циклу представляет собой определённое событие, метод getEventType() возвращает тип этого события, например: START_DOCUMENT, END_TAG и др. Переход к следующему тегу осуществляется с помощью метода next().
Извлечём некоторые данные из XML файла. Получившийся код выглядит следующим образом:
В данном случае нас интересует событие START_TAG. Когда это событие наступает, нужно найти нужные данные по типу и имени, и затем забрать из этого тега значение. В результате выполнения цикла выводим всё на экран.

Как видно, реализация довольно проста, разработчику достаточно только понимать, как устроен XML-документ.
Однако это не единственный способ извлечь данные из XML. В Android есть также класс DocumentBuilder, который позволяет получать экземпляры DOM документов из XML DOM (Document Object Model) — это программный интерфейс, благодаря которому можно получать доступ к данным HTML или XML.
Ключевым методом здесь будет являться getElementsByTagName(), который возвращает список тегов с нужным именем, затем внутри этого списка ищется нужный по атрибуту name. Реализация выглядит следующим образом.
В результате мы получили аналогичный список, как и при первом случае.
Здесь были приведены не все способы распарсить XML, существует множество различных пользовательских библиотек, предоставляющих такой же функционал. Всё зависит от того, какой способ будет удобнее разработчику в конкретной ситуации.
Как парсить XML на Android : 2 комментария
Спасибо за хорошую статью. Жаль, раньше на нее не попал и парсил документ с помощью строковых методов java)))
Источник



