Программист добавил в утилиту ethminer поддержку Mac c чипом M1
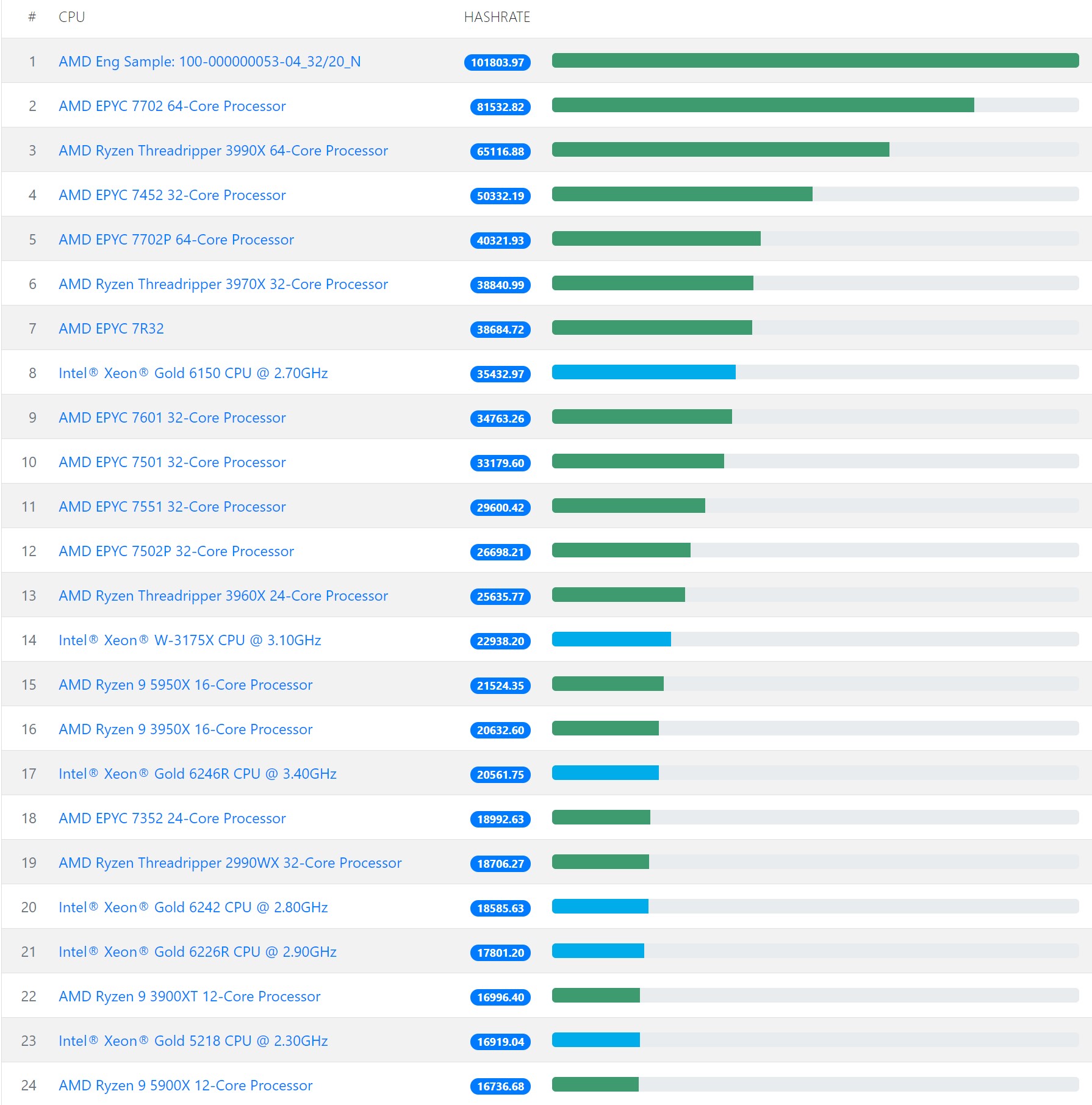
Сравнение хэшрейта на Mac c M1 и специальных майниноговых карт Nvidia CMP.
26 февраля 2021 года программист Ифань Гу (Yifan Gu) в своем блоге рассказал, что добавил в утилиту ethminer поддержку Apple M1. Ее модифицированная версия доступна в репозитории разработчика на GitHub.
Для того, чтобы запустить ethminer на MacBook Air с чипом M1 Гу пришлось сделать некоторые манипуляции с исходным кодом утилиты. Он добавил в «белый список» майнера (libethash-cl/CLMiner.cpp) чип M1 как Intel GPU. Также Гу пришлось обновить boost до последней версии и внести исправления в соответствующий код asio. Еще ему пришлось обновить OpenSSL до последней версии для поддержки связки «darwin + arm64».
Процесс запуска ethminer на MacBook Air с M1.
Разработчик пояснил, что хэшрейт при майнинге Ethereum на Apple M1 достигает 2 Mh/s, это очень мало, но ему было интересно реализовать сам запуск этого процесса в экспериментальных целях. Гу выяснил, что новый MacBook Air может майнить криптовалюту Ethereum по $0.14 в сутки (по курсу на 26 февраля).
Для сравнения, на видеокарте GeForce GTX 1050 этот параметр составляет около 9 MH/s, а в новой GTX 3060 с урезанным в vBIOS в два раза хейшейте (выдает около 25 Mh/s) на майнинге Ethereum можно получить до $6 в сутки.
Пример достигаемых параметров хэшрейта на Apple M1.
Это не первый раз, когда энтузиасты используют Apple с M1 для майнинга. В декабре 2020 года разработчики из XMRig смогли на этом чипе майнить криптовалюту Monero.
Источник
Apple m1 gpu mining
Рынок криптовалют находится на рекордном подъеме. Несмотря на серьезный откат, произошедший за несколько последних недель, курсы криптовалют держатся на высоком уровне и все еще позволяют быстро окупать оборудование для майнинга и выходить на неплохой доход. Пользователи испытывают в майнинге любые устройства и видеокарты, которые удастся найти, и владельцы новых MacBook Air не исключение.
реклама
Ифань Гу — один из счастливых обладателей MacBook Air на новейшем чипе M1, вероятно, увидев, на что способны ноутбуки с видеокартами NVIDIA, решил проверить способности встроенного 8-ядерного GPU в новом SoC от Apple. В ряде тестов графическая производительность M1 оказывается на уровне GeForce GTX 1050 Ti, однако подсистема памяти устройства недостаточно быстра для майнинга — используется LPDDR4X-4266.
Просто запустить майнинг на MacBook Air не получится, владельцу пришлось доработать код ethminer и прибегнуть к некоторым уловкам, но результаты своего труда Ифань Гу опубликовал в своем блоге и на GitHub. Производительность не впечатлила — 2 мегахеша в секунду, что позволит заработать несколько десятков центов в день.
Популярные новости
Популярные статьи
Внимание! Регистрация на сайте и вход осуществляются через конференцию.
Для регистрации перейдите по ссылке, указанной ниже. Если у вас уже есть аккаунт в конференции, то для доступа ко всем функциям сайта вам достаточно войти в конференции под своим аккаунтом.
Данный сервис работает пока только для зарегистрированных пользователей. Регистрация займет у вас всего 5 минут, но вы получите доступ к некоторым дополнительным функциям и скрытым разделам.
Соблюдение Правил конференции строго обязательно! Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам , удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.
Источник
Процессор Apple M1 протестировали в майнинге криптовалюты Monero
Компания Apple недавно выпустила в продажу новые ноутбуки MacBook Air и MacBook Pro 13 с совершенно новым процессором собственной разработки под названием Apple M1, который в некоторых приложения показывает просто чудеса производительности и энергоэффективности по сравнению с такими же ноутбуками, но на процессорах Intel. Если верить компании Apple, то новый 8-и ядерный ARM процессор M1 показывает до 3 раз лучшую энергоэффективность по сравнению с конкурирующими продуктами, о чем уже сломалось не мало копий на просторах интернета. В новой версии майнера XMrig 6.7.0 появилась возможность протестировать Apple M1 в майнинге криптовалюты Monero на алгоритме RandomX и результаты этого тестирования могут добавить еще немного жару в спор Apple vs Intel и AMD, который уже и так достаточно горячий.
Разработчики майнера XMrig ведут собственную базу по хешрейту различных процессоров на алгоритме RandomX и RandomWOW и в этом списке появились результаты тестирования процессора Apple M1:
Разрекламированный процессор Apple в этом тесте занимает 190 место с результатом в 2384H/s, что сопоставимо с процессором Intel Core i7-4770K 2013 года выпуска. Но в защиту Apple стоит отметить, что энергопотребление CPU M1 составляет всего 15W, а у i7-4770K 84W.
Поэтому если сравнить энергоэффективность процессоров в майнинге, то Apple M1 с результатом 159H/W будет значительно лучше 4770K c 27H/W.
Но т.к. Apple M1 это совершенно новый процессор 2020 года выполненный по самому современному техпроцессу в 5нм, поэтому по энергоэффективности его нужно сравнивать с процессорами AMD и Intel последнего поколения.
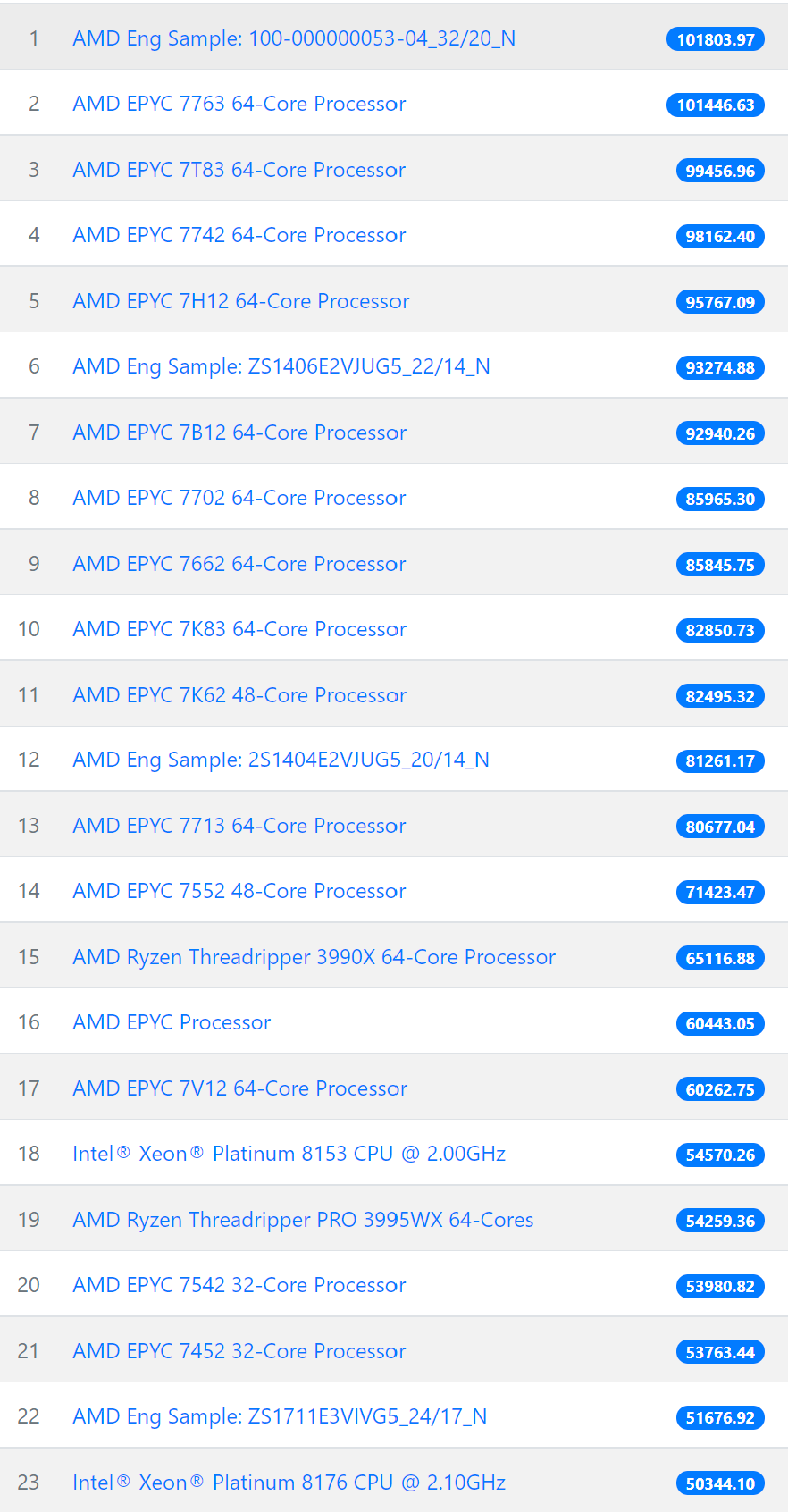
Для сравнения возьмем новый 12-ти ядерный (24 потока) процессор от AMD Ryzen 5900X выполненный по технологии 7нм с энергопотреблением 105W
Процессор AMD Ryzen 9 5900X в майнинге Monero показывает результат в 16700H/s, что значительно превосходит результаты в этом тесте Apple M1.
А если сравнить энергоэффективность, то Ryzen 5900Х показывает точно такую же энергоэффективность в майнинге как и Apple M1 — 159H/W.
Собственно на этом можно было и закончить и пригласить всех в комментарии, которых на этом сайте нету, но Вы всегда можете оставить свой комментарий в нашем телеграм канале
Счастливые обладатели MacBook с процессором M1 могут самостоятельно проверить способности своего приобретения, скачав XMrig на GitHub
Самостоятельно ознакомиться с тестами процессоров на алгоритме RandomX можно на сайте XMRIG.com
Вывод: Для майнинга ноутбуки Apple с новейшим процессором M1 не подходят т.к. дают всего 0,13 USD в день. Что бы зарабатывать на майнинге заметные суммы нужно покупать видеокарты или контракты облачного майнинга
Подпишись на наш Telegram канал @cryptoage и Вконтакте, узнавай новости про криптовалюты первым.
Общайся с криптоэнтузиастами и майнерами в Telegram чате @CryptoChat
Лучшие биржи для покупки и обмена криптовалют, токенов:
Биржа
Преимущества
Бонусы при регистрации
Binance
Самая крупная и известная крипто биржа в мире. Надежность и функционал на самом высшем уровне.
Скидка 20% на торговую комиссию
FTX
Лучшая биржа для торговли крипто фьючерсами. Проводит торги акциями крупных компаний (Apple, Tesla. )
Источник
Apple M1 Pro и M1 Max протестировали в майнинге криптовалюты Monero (RandomX)
После презентации 18 октября 2021 года новых MacBook Pro от Apple с процессорами M1 Pro и M1 MAX прошло уже почти месяц, но в сети до сих пор не утихают хвалебные отзывы и споры о преимуществах и недостатках новых ARM процессорах от Apple. Если Вы пристально следите за компьютерным рынком и за продукцией компании Apple в частности, то наверняка уже знаете о возможностях новых MacBook Pro в рабочих задачах и играх. Но как ноутбуки Apple поведут себя в майнинге криптовалют тоже не менее интересно, тем более что эта информация может еще больше добавить огня в и так горячие споры в противостоянии Apple, AMD и Intel.
В качестве бенчмарка в майнинге возьмем хешрейт процессоров на алгоритме RandomX, криптовалюта Monero, которая является самой популярной криптовалютой для майнинга на центральных процессорах.
В качестве майнера использована программа XMRig/6.15.3 (Macintosh; macOS; arm64) libuv/1.42.0 clang/12.0.5
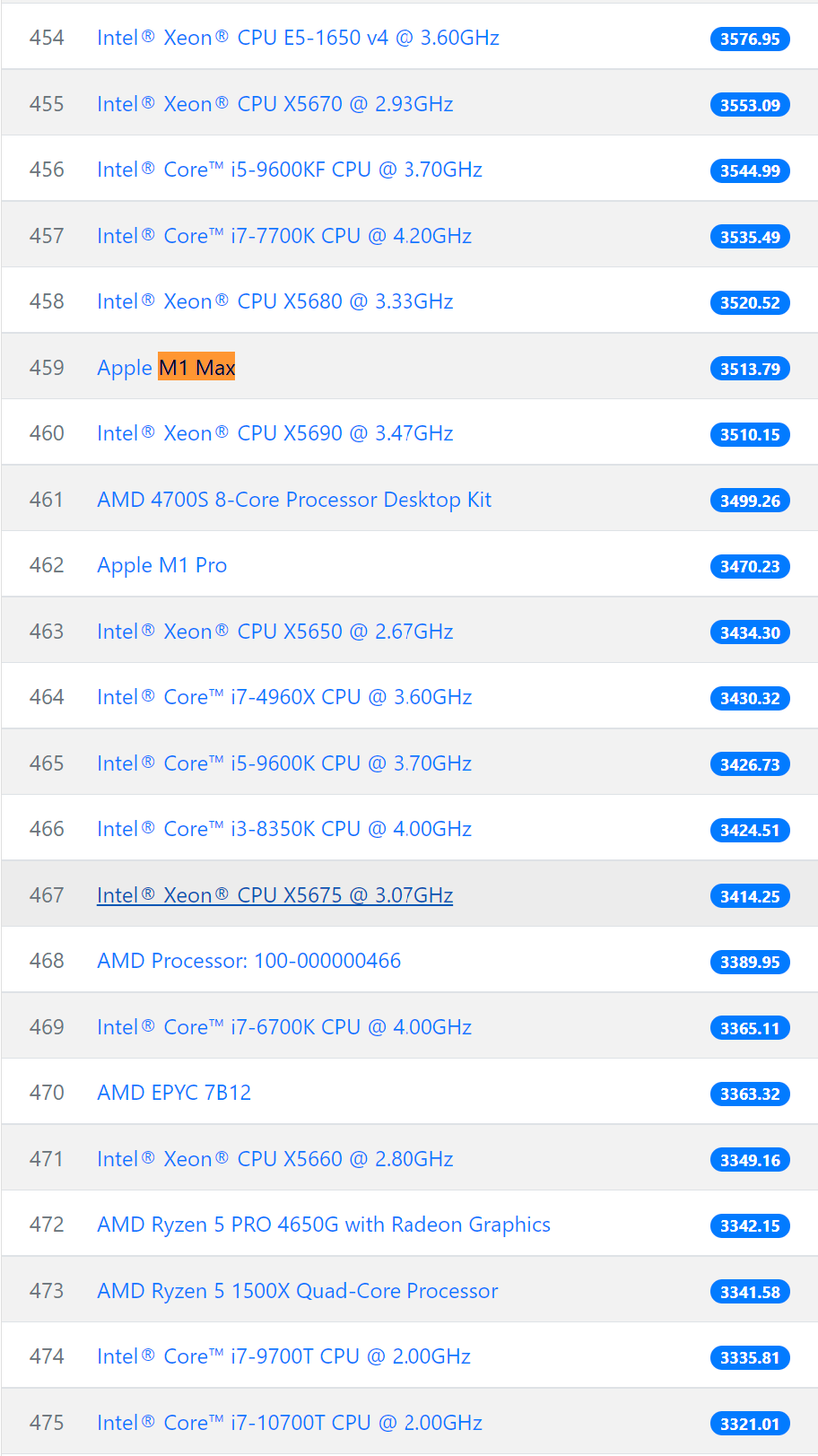
Хешрейт процессоров Apple M1, M1 Pro, M1 Max:
Apple M1 — 2390H/s
Apple M1 Pro — 3470H/s
Apple M1 Max — 3513H/s
Следует отметить, что производительность на ядро младшего процессора M1 даже выше чем у старших моделей: 430H/s против 350H/s.
По сравнению с тестированием процессора M1 в прошлом 2020 году, хешрейт у процессора за это время не изменился, т.е. текущий хешрейт на алгоритме RandomX для M1 Max и Pro можно считать максимальными значениями и ждать какого-то сильного изменения в сторону улучшения от программных доработок майнеров уже не стоит.
В общем рейтинге по производительности в майнинге процессоры Apple M1 Max и M1 Pro занимают 459 и 462 место, уступив несколько позиций популярной модели Intel 2017 года Core i7 7700K c 3535H/s.
Современный мобильный процессор от Intel — Core i7 1165G7 выдает 2724H/s, что больше чем у простого M1, но хуже чем у ПРО и МАКС версии.
Мобильный процессор Ryzen 7 5800H от компании AMD ожидаемо в этой дисциплине показывает кто в доме хозяин при производительности в 5410H/s. Не говоря уже о полноценной версии этого процессора 5800X.
Топ из процессоров для майнинга выглядит следующим образом, где преимущественно серверные процессоры:
Популярные в майнинге десктопные процессоры, для сравнения, имеют следующие хешрейты на алгоритме RandomX:
AMD Ryzen 5 5600X — 8921H/s
AMD Ryzen 7 5800X — 12445H/s
AMD Ryzen 7 5900X — 17310H/s
AMD Ryzen 7 5950X — 22900H/s
Intel Core i9 12900K — 9700H/s
Intel Core i9 11900K — 7347H/s
Intel Core i7 11700K — 7160h/s
Intel Core i5 11600K — 4846H/s
Вывод: Современные ARM процессоры APPLE M1 плохо подходят для майнинга криптовалюты Monero, т.к. традиционные X86 процессоры от Intel и AMD при схожем TDP показывают заметно более высокие результаты, не говоря уже про полноценные десктопные процессоры с TDP 60Вт и более. Если и рассматривать процессоры к покупке с использованием их в майнинге, то в первую очередь нужно обратить внимание на продукцию компании AMD.
Подпишись на наш Telegram канал @cryptoage и Вконтакте, узнавай новости про криптовалюты первым.
Общайся с криптоэнтузиастами и майнерами в Telegram чате @CryptoChat
Лучшие биржи для покупки и обмена криптовалют, токенов:
Биржа
Преимущества
Бонусы при регистрации
Binance
Самая крупная и известная крипто биржа в мире. Надежность и функционал на самом высшем уровне.
Скидка 20% на торговую комиссию
FTX
Лучшая биржа для торговли крипто фьючерсами. Проводит торги акциями крупных компаний (Apple, Tesla. )
Источник
Реверс-инжиниринг GPU Apple M1
Новая линейка компьютеров Apple Mac содержит в себе разработанную самой компанией SOC (систему на чипе) под названием M1, имеющую специализированный GPU. Это создаёт проблему для тех, кто участвует в проекте Asahi Linux и хочет запускать на своих машинах Linux: у собственного GPU Apple нет ни открытой документации, ни драйверов в open source. Кто-то предполагает, что он может быть потомком GPU PowerVR, которые использовались в старых iPhone, другие думают, что GPU полностью создан с нуля. Но слухи и домыслы неинтересны, если мы можем сами заглянуть за кулисы!
Несколько недель назад я купила Mac Mini с GPU M1, чтобы изучить набор инструкций и поток команд, а также разобраться в архитектуре GPU на том уровне, который ранее не был публично доступен. В конечном итоге я хотела ускорить разработку драйвера Mesa для этого оборудования. Сегодня я достигла своего первого важного этапа: теперь я достаточно понимаю набор команд, чтобы можно было дизассемблировать простые шейдеры при помощи свободного и open-source тулчейна, выложенного на GitHub.
Процесс декодирования набора команд и потока команд GPU аналогичен тому процессу, который я использовала для реверс-инжиниринга GPU Mali в проекте Panfrost, изначально организованном проектами свободных драйверов Lima, Freedreno и Nouveau. Обычно для реверс-инжиниринга драйвера под Linux или Android пишется небольшая библиотека-обёртка, инъектируемая в тестовое приложение при помощи LD_PRELOAD , подключающей важные системные вызовы типа ioctl и mmap для анализа взаимодействия пользователя и ядра. После вызова «передать буфер команд» библиотека может выполнить дамп всей общей памяти (расширенной) для её анализа.
В целом тот же процесс подходит и для M1, но в нём есть особенности macOS, которые нужно учитывать. Во-первых, в macOS нет LD_PRELOAD ; её аналогом является DYLD_INSERT_LIBRARIES , имеющая дополнительные функции защиты, которые для выполнения нашей задачи можно достаточно легко отключить. Во-вторых, хотя в macOS существуют стандартные системные вызовы Linux/BSD, они не используются для графических драйверов. Вместо них для драйверов ядра и пространства пользователя используется собственный фреймворк Apple IOKit , критической точкой входа которого является IOConnectCallMethod (аналог ioctl ). Такие различия достаточно просто устранить, но они добавляют слой дистанцирования от стандартного инструментария Linux.
Более серьёзной проблемой является ориентирование в мире IOKit. Так как Linux имеет лицензию copyleft, (законные) драйверы ядра выложены в open source, то есть интерфейс ioctl открыт, хотя и зависит от производителя. Ядро macOS (XNU) имеет либеральную лицензию, не обладающую такими обязательствами; интерфейс ядра в нём проприетарен и не задокументирован. Даже после обёртывания IOConnectCallMethod пришлось попотеть, чтобы найти три важных вызова: выделение памяти, создание буфера команд и передача буфера команд. Обёртывание вызовов выделения памяти и создания буфера необходимы для отслеживаемой видимой GPU памяти (а именно это мне было интересно исследовать), а обёртывание вызова передачи необходимо для подбора времени дампа памяти.
Преодолев эти препятствия, мы можем наконец перейти к двоичным файлам шейдеров, которые сами по себе являются «чёрными ящиками». Однако далее процесс становится стандартным: начинаем с самого простого фрагментного или вычислительного шейдера, вносим небольшое изменение во входящий исходный код и сравниваем получившиеся двоичные файлы. Многократное повторение этого процесса — скучное занятие, но позволяет быстро выявить основные структуры, в том числе и опкоды.
Открытия, сделанные в задокументированном процессе изучения при помощи свободного дизассемблера ПО, подтверждают наличие у GPU следующих особенностей:
Во-первых, архитектура скалярна. В отличие от некоторых GPU, которые являются скалярными для 32 бит, но векторизованными для 16 бит, GPU процессора M1 скалярен при всех битовых размерах. Хотя на ресурсах по оптимизации Metal написано, что 16-битная арифметика должна быть значительно быстрее, кроме снижения использования регистров она ведёт к повышению количества потоков (занятости процессора). Исходя из этого, можно предположить, что оборудование является суперскалярным и в нём больше 16-битных, чем 32-битных АЛУ, что позволяет получать большее преимущество от графических шейдеров низкой точности, чем у чипов конкурентов, одновременно значительно снижая сложность работы компилятора.
Во-вторых, архитектура, похоже, выполняет планирование аппаратно — это часто встречается среди десктопных GPU, но менее распространено во встроенных системах. Это тоже упрощает компилятор ценой большего количества оборудования. Похоже, команды минимально тратят лишние ресурсы при кодировании, в отличие от других архитектур, вынужденных перегружать команды nop для того, чтобы уместиться в сильно ограниченные наборы инструкций.
В-третьих, поддерживаются различные модификаторы. АЛУ с плавающей запятой могут выполнять модификаторы clamp (насыщенность), операций НЕ и абсолютных значений «бесплатно», без лишних затрат — распространённая особенность архитектуры шейдеров. Кроме того, большинство (или все?) команды позволяют «бесплатно» выполнять преобразование типов между 16-битными и 32-битными значениями и для адресата, и для источника, что позволяет компилятору более агрессивно использовать 16-битные операции, не рискуя тратить ресурсы на преобразования. Что касается целочисленных значений, то для некоторых команд есть различные «бесплатные» побитовые отрицания и сдвиги. Всё это не уникально для оборудования Apple, но заслуживает упоминания.
Наконец, не все команды АЛУ имеют одинаковые тайминги. Команды типа imad (используется для перемножения двух целых чисел и прибавления третьего) по возможности избегаются и вместо них используются многократные команды целочисленного сложения iadd . Это тоже позволяет предположить наличие суперскалярной архитектуры; оборудование с программным планированием, с которым я взаимодействую на своей повседневной работе, не может использовать различия в длине конвейеров, непреднамеренно замедляя простые команды для соответствия скорости сложных.
По своему предыдущему опыту работы с GPU я ожидала найти какой-нибудь ужас в наборе инструкций, повышающий сложность компилятора. Хотя написанное выше охватывает только небольшую площадь поверхности набора инструкций, пока всё кажется разумным и логичным. Отсутствуют сложные трюки для оптимизации, однако отказ от трюков позволяет создать простой, эффективный дизайн, выполняющий одну задачу, и справляющийся с ней хорошо. Возможно, проектировщики оборудования Apple поняли, что простота превыше всего.
Часть вторая
В первой части я начала изучать GPU Apple M1, надеясь разработать бесплатный драйвер с открытым исходным кодом. Теперь мне удалось достичь важного этапа: отрисовать треугольник с помощью собственного кода в open source. Вершинные и фрагментные шейдеры написаны вручную на машинном коде, а взаимодействие с оборудованием выполняется с помощью драйвера ядра IOKit, подобно тому, как это происходило в системном драйвере пользовательского пространства Metal.
Треугольник, отрендеренный на M1 кодом в open source
Основная часть нового кода отвечает за построение различных буферов команд и дескрипторов, находящихся в общей памяти и используемых для управления поведением GPU. Любое состояние, доступное из Metal, соответствует битам в этих буферах, поэтому следующей важной задачей будет их анализ. Пока меня больше интересует не содержимое, а связи между ними. В частности, структуры, содержащие указатели друг на друга, иногда встроенные на несколько слоёв вглубь. Процесс подготовки треугольника в моём проекте позволяет взглянуть «с высоты птичьего полёта» на то, как взаимодействуют все эти отдельные части в памяти.
Например, предоставляемые приложением данные вершин хранятся в собственных буферах. Внутренняя таблица в ещё одном буфере указывает на эти буферы вершин. Эта внутренняя таблица передаётся непосредственно на вход вершинного шейдера, заданного в другом буфере. На это описание вершинного шейдера, в том числе и на адрес кода в исполняемой памяти, указывает ещё один буфер, на который сам ссылается основной буфер команд, на который ссылается вызов IOKit на передачу буфера команд. Ого!
Другими словами, код демо пока не предназначен для демонстрации понимания мелких подробностей буферов команд, а скорее служит для демонстрации того, что «ничто не упущено». Так как виртуальные адреса GPU меняются при каждом запуске, демо подтверждает, что идентифицированы все необходимые указатели и их можно свободно перемещать в памяти с помощью нашего собственного (тривиального) распределителя. Так как в macOS присутствует некоторая «магия», связанная с распределением памяти и буферов команд, наличие этого работающего кода позволяет нам спокойно двигаться дальше.
Я использовала поэтапный процесс подготовки. Поскольку моя обёртка IOKit располагается в то же адресном пространстве, что и приложение Metal, обёртка способна модифицировать буферы команд непосредственно перед передачей в GPU. В качестве первого «hello world» я задала кодирование в памяти цвета очистки render target и показала, что могу изменять этот цвет. Аналогично, узнав о наборе инструкций для вывода дизассемблера, я заменила шейдеры написанными самостоятельно эквивалентами и убедилась, что могу исполнять код в GPU, доказать, что написала машинный код. Однако мы не обязаны останавливаться на этих «нодах листьев» системы; изменив код шейдера, я попыталась загрузить код шейдера в другую часть исполняемого буфера, модифицировав указатель командного буфера на код, чтобы компенсировать это. После этого я смогу попробовать самостоятельно загружать команды для шейдера. Проводя разработку таким образом, я смогу создать все необходимые структуры, тестируя каждую из них по отдельности.
Несмотря на затруднения, этот процесс оказался гораздо более успешным, чем попытка перейти непосредственно к построению буферов, например, при помощи «воспроизведения». Я использовала этот альтернативный способ несколько лет назад для создания драйверов Mali, однако у него есть серьёзный недостаток — чудовищно сложная отладка. Если в пяти сотнях строк магических чисел присутствует хотя бы одна опечатка, то никакой обратной связи, кроме ошибки GPU, вы не получите. Однако при последовательной работе можно выявлять причины ошибок и немедленно их исправлять, что оказывается быстрее и удобнее.
Однако затруднения всё-таки были! Моё временное ликование, вызванное возможностью изменения цветов очистки, пропало, когда я попыталась выделить буфер для цветов. Несмотря на то, что GPU кодировал те же биты, что и раньше, ему не удавалось корректно выполнить очистку. Думая, что где-то ошиблась в способе модификации указателя, я попыталась поместить цвет в неиспользованную часть памяти, уже созданную драйвером Metal, и это сработало. Содержимое осталось тем же, как и способ модификации указателей, но GPU почему-то не нравилось моё распределение памяти. Я думала, что как-то неправильно распределяю память, но использованные для вызова распределения памяти IOKit были побитово идентичны тем, что использовались Metal, что подтверждалось wrap . Моей последней отчаянной попыткой стала проверка, должна ли память GPU отображаться явным образом через какой-то побочный канал, например, через системный вызов mmap . У IOKit есть устройство-независимый вызов memory map, но никакие трассировки не позволили обнаружить свидетельств отображений через сторонние системные вызовы.
Появилась проблема. Утомившись от потраченного на устранение «невозможного» бага времени, я задалась вопросом, нет ли чего-то «магического» не в системном вызове, а в самой памяти GPU. Глупая теория, потому что если это так, то появляется серьёзная проблема «курицы и яйца»: если распределение памяти GPU должно быть одобрено другим распределением GPU, то кто одобряет первое распределение?
Чувствуя себя глупо и ощущая отчаяние, я решила протестировать теорию, вставив вызов распределения памяти посередине потока выполнения приложения, чтобы каждое последующее распределение находилось по другому адресу. Выполнив дамп памяти GPU до и после этого изменения и изучив их отличия, я обнаружила свой первый кошмар: наличие вспомогательного буфера в памяти GPU, отслеживающего все требуемые распределения. В частности, я заметила, что значения в этом буфере увеличиваются на единицу с предсказуемым смещением (через каждые 0x40 байт), и это намекает о содержании в буфере массива дескрипторов распределений. И в самом деле, эти значения точно соответствовали дескрипторам, возвращаемым из ядра при вызовах распределения памяти GPU.
Закрыв глаза на очевидные проблемы этой теории, я всё равно её протестировала, модифицировав эту таблицу и добавив в конец дескриптор моего нового распределения, а также изменив структуру данных заголовка так, чтобы увеличить количество элементов на единицу. Это не помогло. Несмотря на разочарование, это всё равно не позволяло полностью отказаться от теории. На самом деле, я заметила в элементах таблицы нечто любопытное: не все они соответствовали действительным дескрипторам. Действительными были все элементы, кроме последнего. Диспетчеры ядра имеют индексацию с 1, однако в каждом дампе памяти последний дескриптор всегда был 0 , несуществующим. Вероятно, он используется как контрольное значение, аналогично NULL-terminated string в C. Однако при таком объяснении возникает вопрос: почему? Если заголовок уже содержит количество элементов, то контрольное значение избыточно.
Я продолжила разбираться дальше. Вместо добавления ещё одного элемента с моим дескриптором, я скопировал последний элемент n в дополнительный элемент n + 1 и переписала элемент n (теперь второй с конца) новым дескриптором.
Внезапно отобразился нужный мне цвет очистки.
Итак, загадка решена? Код заработал, так что в каком-то смысле да. Но едва ли это объяснение может нас удовлетворить; на каждом этапе непонятное решение будет создавать новые вопросы. Проблему курицы и яйца решить проще всего: эта таблица отображений вместе с корневым буфером команд распределяется специальным селектором IOKit, не зависящим от распределения общего буфера, а дескриптор таблицы отображений передаётся с селектором буфера команд. Более того, идея передачи требуемых дескрипторов вместе с передачей буфера команд не уникальна; подобный механизм используется в стандартных драйверах Linux. Тем не менее, обоснование для использования 64-байтных элементов таблицы в общей памяти вместо простого массива на стороне CPU остаётся совершенно непонятной.
Но даже оставив позади проблемы с распределением памяти, двигаться вперёд пришлось не без труда. Однако благодаря терпению мне удалось полностью воссоздать память GPU параллельно с Metal, используя проприетарное пространство пользователя только для инициализации устройства. Наконец, остался последний «прыжок веры» — отказ от синхронизации с IOKit, после чего мне удалось получить свой первый треугольник.
Для второй части статьи пришлось внести в код изменения объёмом примерно 1700 строк кода, сам код выложен на GitHub. Я собрала простое демо, анимирующее на экране треугольник с помощью GPU. Интеграция с оконной системой на этом этапе практически отсутствует: требуется XQuartz, а в ПО с наивным скалярным кодом возникает detiling буфера кадров. Тем не менее, скорости CPU M1 с лихвой хватает, чтобы с этим справиться.
Теперь, когда готова начальная загрузка каждой части драйвера пространства пользователя, двигаясь дальше, мы сможем по отдельности работать над набором инструкций и буферами команд. Можно будет разобрать мелкие подробности и побитово преобразовать код из сотен необъяснимых магических констант в настоящий драйвер.

 Компания Apple недавно выпустила в продажу новые ноутбуки MacBook Air и MacBook Pro 13 с совершенно новым процессором собственной разработки под названием Apple M1, который в некоторых приложения показывает просто чудеса производительности и энергоэффективности по сравнению с такими же ноутбуками, но на процессорах Intel. Если верить компании Apple, то новый 8-и ядерный ARM процессор M1 показывает до 3 раз лучшую энергоэффективность по сравнению с конкурирующими продуктами, о чем уже сломалось не мало копий на просторах интернета. В новой версии майнера XMrig 6.7.0 появилась возможность протестировать Apple M1 в майнинге криптовалюты Monero на алгоритме RandomX и результаты этого тестирования могут добавить еще немного жару в спор Apple vs Intel и AMD, который уже и так достаточно горячий.
Компания Apple недавно выпустила в продажу новые ноутбуки MacBook Air и MacBook Pro 13 с совершенно новым процессором собственной разработки под названием Apple M1, который в некоторых приложения показывает просто чудеса производительности и энергоэффективности по сравнению с такими же ноутбуками, но на процессорах Intel. Если верить компании Apple, то новый 8-и ядерный ARM процессор M1 показывает до 3 раз лучшую энергоэффективность по сравнению с конкурирующими продуктами, о чем уже сломалось не мало копий на просторах интернета. В новой версии майнера XMrig 6.7.0 появилась возможность протестировать Apple M1 в майнинге криптовалюты Monero на алгоритме RandomX и результаты этого тестирования могут добавить еще немного жару в спор Apple vs Intel и AMD, который уже и так достаточно горячий.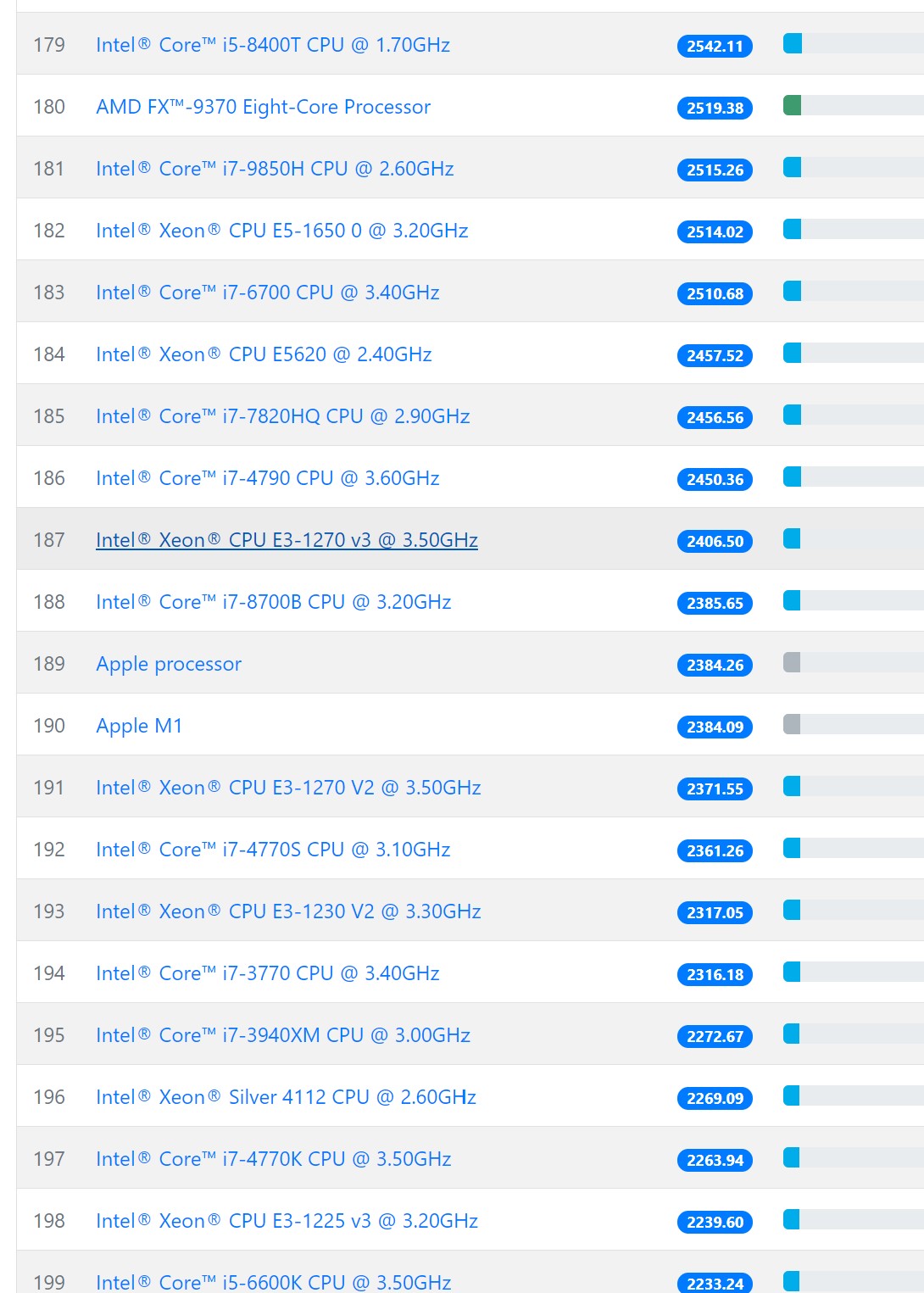
 После презентации 18 октября 2021 года новых MacBook Pro от Apple с процессорами M1 Pro и M1 MAX прошло уже почти месяц, но в сети до сих пор не утихают хвалебные отзывы и споры о преимуществах и недостатках новых ARM процессорах от Apple. Если Вы пристально следите за компьютерным рынком и за продукцией компании Apple в частности, то наверняка уже знаете о возможностях новых MacBook Pro в рабочих задачах и играх. Но как ноутбуки Apple поведут себя в майнинге криптовалют тоже не менее интересно, тем более что эта информация может еще больше добавить огня в и так горячие споры в противостоянии Apple, AMD и Intel.
После презентации 18 октября 2021 года новых MacBook Pro от Apple с процессорами M1 Pro и M1 MAX прошло уже почти месяц, но в сети до сих пор не утихают хвалебные отзывы и споры о преимуществах и недостатках новых ARM процессорах от Apple. Если Вы пристально следите за компьютерным рынком и за продукцией компании Apple в частности, то наверняка уже знаете о возможностях новых MacBook Pro в рабочих задачах и играх. Но как ноутбуки Apple поведут себя в майнинге криптовалют тоже не менее интересно, тем более что эта информация может еще больше добавить огня в и так горячие споры в противостоянии Apple, AMD и Intel.