- Шаблон Repository в Android
- Модель домена
- Преобразователь данных (Data Mapper)
- Отдельная модель для каждого источника данных
- Кэширование только по необходимости
- Шаблон Repository в Android
- Модель домена
- Преобразователь данных (Data Mapper)
- Отдельная модель для каждого источника данных
- Кэширование только по необходимости
- Что такое репозитории android
- Антипаттерн “Репозиторий” в Android
- Репозиторий
- Репозиторий в Android Architecture Blueprints v2
- Репозиторий как Божественный объект (God Object)
- Анемичные репозитории
- Репозитории вне Android.
- Как репозиторий стал антипаттерном в Android
- Заключение
Шаблон Repository в Android
Nov 23, 2019 · 5 min read
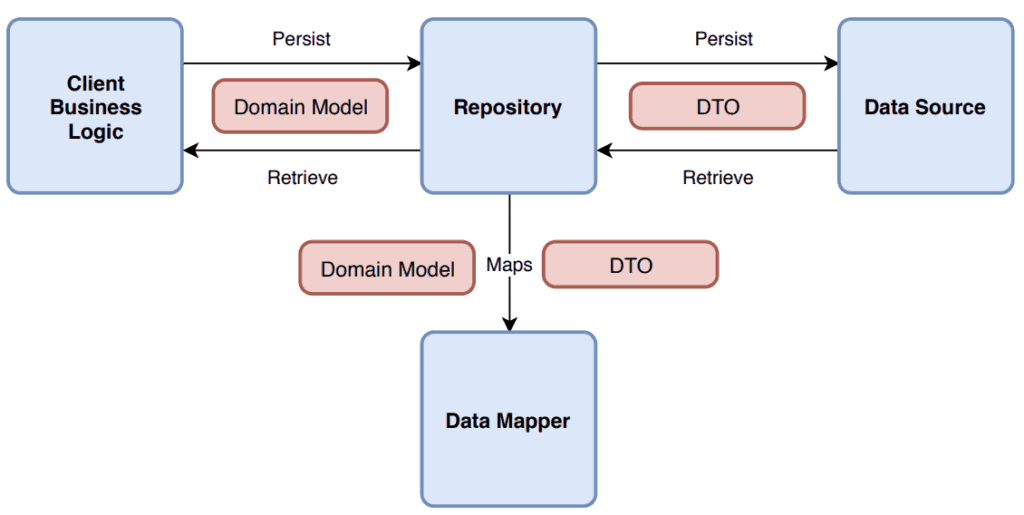
Вот 5 самых распространенных ошибок (некоторые из них также есть в официальной документации Android):
- Repository возвращает DTO (объект передачи данных) вместо доменной модели.
- Источники данных (ApiServices, DAO) используют один и тот же DTO.
- Репозиторий создается для каждого набора конечных точек, а не для каждой сущности (или Aggregate Root, если вы предпочитаете предметно-ориентированное проектирование — DDD).
- Репозиторий кэширует всю модель, даже те поля, которые должны содержать обновленную информацию.
- Источник данных используется несколькими Repository.
Как же правильно реализовать Repository?
Модель домена
Это ключевой момент в шаблоне, однако многие разработчики не понимают, что такое домен.
Цитируя Мартина Фаулера, можно сказать, что доменная модель — это:
Объектная модель домена, охватывающая поведение (функции) и свойства (данные).
Модели домена представляют корпоративные бизнес-правила. Существует 3 типа таких моделей:
- Entity (сущность) — это простой потенциально изменяемый объект с идентификатором.
- Value object (объект-значение) — неизменяемый объект без сущности.
- Aggregate root (корень агрегации) — сущность, которая связывается вместе с другими сущностями (кластер связанных объектов). Применимо только в DDD.
В простых доменах эти модели очень схожи с моделями баз данных и сетей (DTO), однако они обладают несколькими различиями:
- Доменные модели объединяют данные и процессы. Их структура наиболее подходит для приложения.
- DTO — это представление объектной модели для запроса/ответа JSON/XML или таблицы базы данных, поэтому их структура является наиболее подходящей для удаленной коммуникации.
Пример модели домена:
Таким образом, д оменная модель не зависит от фреймворков, а ее структура поддерживает многозначные атрибуты (логически сгруппированные в Price) и использует шаблон Null Object (поля non-nullable), тогда как DTO связаны с фреймворком (Gson, Room).
Благодаря этому разделению:
- Упрощается разработка приложения, поскольку не нужно проверять нулевые значения. Благодаря многозначным атрибутам не нужно отправлять модель целиком.
- Изменения в источниках данных не влияют на уровни выше.
- Отсутствуют избыточные модели.
- Плохие реализации бэкенда не влияют на уровни выше (представьте, что вам приходится выполнять 2 сетевых запроса, потому что бэкенд не может предоставить всю необходимую информацию за один раз. Позволите ли вы этой проблеме повлиять на всю базу кода?
Преобразователь данных (Data Mapper)
Здесь DTO преобразуются в доменные модели и обратно.
Поскольку большинство разработчиков считают это преобразование скучным и ненужным процессом, они предпочитают соединять всю базу кода, начиная от источников данных и заканчивая пользовательским интерфейсом, с DTO.
В результате первые релизы выполняются быстрее. Но пропуск доменного слоя и связывание пользовательского интерфейса с источниками данных вместо размещения бизнес-правил и вариантов использования на уровне представления (например, шаблон Smart UI) приводит к некоторым ошибкам. Эти ошибки можно обнаружить только в продакшне (например, бэкенд отправляет null вместо пустой строки, а она генерирует NullPointerException ).
Реализация преобразователей представляет собой скучный процесс, но их наличие гарантирует отсутствие сюрпризов из-за изменения в поведении источников данных. При отсутствии времени или желания создавать преобразователи можно воспользоваться фреймворками, такими как http://modelmapper.org/.
Поскольку я стараюсь не использовать фреймворки в реализации, чтобы избежать шаблонного кода, у меня есть универсальный интерфейс mapper для каждого преобразователя:
А также набор универсальных ListMappers , благодаря которым не нужно реализовывать каждое преобразование списка в список:
Отдельная модель для каждого источника данных
Допустим, что для сети и базы данных используется одна и та же модель:
Изначально может показаться, что этот способ намного быстрее, чем создание двух разных моделей, однако такой подход предполагает определенный риск:
- Кэширование большего количества объектов, чем это необходимо.
- Добавление полей в ответ потребует переноса базы данных, если не добавить аннотацию @Ignore .
- Для всех кэшируемых полей, которые не нужно отправлять в качестве тела запроса, необходимо добавить аннотацию @Transient .
- Новые поля должны иметь один и тот же тип данных (например, мы не можем распарсить строку n owPriceиз сетевого ответа и кэшировать nowPrice дважды).
Таким образом, этот подход требует гораздо большей поддержки, чем отдельные модели.
Кэширование только по необходимости
Допустим, нужно отобразить список продуктов, хранящихся в удаленном каталоге, и для каждого продукта показать классический значок сердца, если он находится в локальном списке пожеланий.
Для этого нужно:
- Получить список продуктов.
- Проверить локальное хранилище на наличие продуктов в локальном списке пожеланий.
Доменная модель будет выглядеть как и прежде, однако с добавлением поля, в котором указано, есть ли товар в списке пожеланий:
Сетевая модель будет выглядеть так же, а в модели базы данных просто нет необходимости. Хранить id продуктов для локального списка пожеланий можно в SharedPreferences . Не нужно усложнять логику и разбираться с переносами баз данных.
Репозиторий будет выглядеть следующим образом:
Используемые зависимости можно описать так:
Но если нужно получить только те продукты, которые относятся к списку пожеланий? В этом случае будет схожая реализация:
Источник
Шаблон Repository в Android
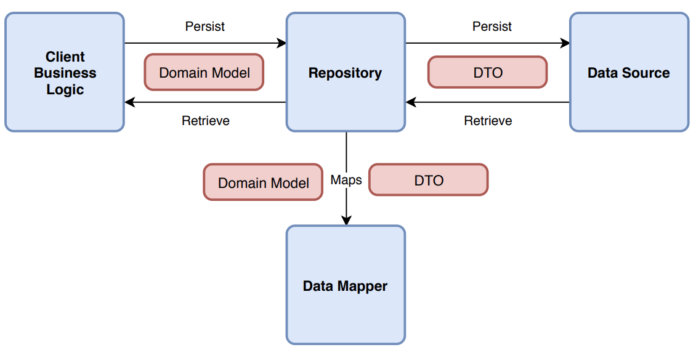
Вот 5 самых распространенных ошибок (некоторые из них также есть в официальной документации Android):
- Repository возвращает DTO (объект передачи данных) вместо доменной модели.
- Источники данных (ApiServices, DAO) используют один и тот же DTO.
- Репозиторий создается для каждого набора конечных точек, а не для каждой сущности (или Aggregate Root, если вы предпочитаете предметно-ориентированное проектирование — DDD).
- Репозиторий кэширует всю модель, даже те поля, которые должны содержать обновленную информацию.
- Источник данных используется несколькими Repository.
Как же правильно реализовать Repository?
Модель домена
Это ключевой момент в шаблоне, однако многие разработчики не понимают, что такое домен.
Цитируя Мартина Фаулера, можно сказать, что доменная модель — это:
Объектная модель домена, охватывающая поведение (функции) и свойства (данные).
Модели домена представляют корпоративные бизнес-правила. Существует 3 типа таких моделей:
- Entity (сущность) — это простой потенциально изменяемый объект с идентификатором.
- Value object (объект-значение) — неизменяемый объект без сущности.
- Aggregate root (корень агрегации) — сущность, которая связывается вместе с другими сущностями (кластер связанных объектов). Применимо только в DDD.
В простых доменах эти модели очень схожи с моделями баз данных и сетей (DTO), однако они обладают несколькими различиями:
- Доменные модели объединяют данные и процессы. Их структура наиболее подходит для приложения.
- DTO — это представление объектной модели для запроса/ответа JSON/XML или таблицы базы данных, поэтому их структура является наиболее подходящей для удаленной коммуникации.
Пример модели домена:
Таким образом, доменная модель не зависит от фреймворков, а ее структура поддерживает многозначные атрибуты (логически сгруппированные в Price) и использует шаблон Null Object (поля non-nullable), тогда как DTO связаны с фреймворком (Gson, Room).
Благодаря этому разделению:
- Упрощается разработка приложения, поскольку не нужно проверять нулевые значения. Благодаря многозначным атрибутам не нужно отправлять модель целиком.
- Изменения в источниках данных не влияют на уровни выше.
- Отсутствуют избыточные модели.
- Плохие реализации бэкенда не влияют на уровни выше (представьте, что вам приходится выполнять 2 сетевых запроса, потому что бэкенд не может предоставить всю необходимую информацию за один раз. Позволите ли вы этой проблеме повлиять на всю базу кода?
Преобразователь данных (Data Mapper)
Здесь DTO преобразуются в доменные модели и обратно.
Поскольку большинство разработчиков считают это преобразование скучным и ненужным процессом, они предпочитают соединять всю базу кода, начиная от источников данных и заканчивая пользовательским интерфейсом, с DTO.
В результате первые релизы выполняются быстрее. Но пропуск доменного слоя и связывание пользовательского интерфейса с источниками данных вместо размещения бизнес-правил и вариантов использования на уровне представления (например, шаблон Smart UI) приводит к некоторым ошибкам. Эти ошибки можно обнаружить только в продакшне (например, бэкенд отправляет null вместо пустой строки, а она генерирует NullPointerException ).
Реализация преобразователей представляет собой скучный процесс, но их наличие гарантирует отсутствие сюрпризов из-за изменения в поведении источников данных. При отсутствии времени или желания создавать преобразователи можно воспользоваться фреймворками, такими как http://modelmapper.org/.
Поскольку я стараюсь не использовать фреймворки в реализации, чтобы избежать шаблонного кода, у меня есть универсальный интерфейс mapper для каждого преобразователя:
А также набор универсальных ListMappers , благодаря которым не нужно реализовывать каждое преобразование списка в список:
Отдельная модель для каждого источника данных
Допустим, что для сети и базы данных используется одна и та же модель:
Изначально может показаться, что этот способ намного быстрее, чем создание двух разных моделей, однако такой подход предполагает определенный риск:
- Кэширование большего количества объектов, чем это необходимо.
- Добавление полей в ответ потребует переноса базы данных, если не добавить аннотацию @Ignore .
- Для всех кэшируемых полей, которые не нужно отправлять в качестве тела запроса, необходимо добавить аннотацию @Transient .
- Новые поля должны иметь один и тот же тип данных (например, мы не можем распарсить строку n owPrice из сетевого ответа и кэшировать nowPrice дважды).
Таким образом, этот подход требует гораздо большей поддержки, чем отдельные модели.
Кэширование только по необходимости
Допустим, нужно отобразить список продуктов, хранящихся в удаленном каталоге, и для каждого продукта показать классический значок сердца, если он находится в локальном списке пожеланий.
Для этого нужно:
- Получить список продуктов.
- Проверить локальное хранилище на наличие продуктов в локальном списке пожеланий.
Доменная модель будет выглядеть как и прежде, однако с добавлением поля, в котором указано, есть ли товар в списке пожеланий:
Сетевая модель будет выглядеть так же, а в модели базы данных просто нет необходимости. Хранить id продуктов для локального списка пожеланий можно в SharedPreferences . Не нужно усложнять логику и разбираться с переносами баз данных.
Репозиторий будет выглядеть следующим образом:
Используемые зависимости можно описать так:
Но если нужно получить только те продукты, которые относятся к списку пожеланий? В этом случае будет схожая реализация:
Источник
Что такое репозитории android
А где эти ссылки? 🙂 У меня в настройках проги осталось три рабочих репы со старых времён, но хотелось бы новые подключить, а линков новых нема 🙂 Поделитесь своими репами плиз (у меня естьаптоид, блэкдроид и андроид-ес) Если есть другие = напишитеих пожалуйста? 🙂
Не совсем так 🙂 Увидеть приложения в маркете можно через, например, маркет энаблер, который эмулирует симкарту одного из разрешенных на платном маркете операторв связи, только скачать их там бесплатно всё одно не дадут 🙂 Другое дело тут. Ищешь на маркете, или ещё где то приложение, которое нравится, потом лезешь сюды, и качаешь его независимо от того — платное приложение,или нет 🙂
Сообщение отредактировал BOJIKOJIAK — 29.04.10, 22:13
При первом запуске программа пишет вполне ясно:
Это же написано на офсайте 😉
взято здесь-же с ветки у конкурирующей программы!
100 программ из «Дайджеста 7 июня 2010 — 13 июня 2010» (И новые, и обновления). Буду поддерживать обновление.
Сообщение отредактировал Arhangel78ru — 18.06.10, 10:08
v1.0.8.7 (08/31/2010)
- Significant reduction of time to re-update repo.
- Fixed overlay over the tabs on big screens (nexus, desire ..).
- Added functionality to save and restore the repository list.
- Added fast scrolling in all apk listings.
- Fixed problems changing the orientation of the phone.
- Now listings show date when apk was added to repo (unused ratting removed). NOTE: Not all repositories provide this date and can cause rare date
- Improved presentation of search results.
- ”See on Market” now access directly to the app, instead of searching it.
- Removed ”APKs in SD” menu, it is very slow, use a file explorer instead.
- Added version ChangeLog dialog.
Действительно — теперь отображается нормально на WVGA, работает определенно быстрее.
Версия 1.0.8.7:  apktor.apk ( 77.18 КБ )
apktor.apk ( 77.18 КБ )
Сообщение отредактировал 5[Strogino] — 01.09.10, 11:36
Источник
Антипаттерн “Репозиторий” в Android
Перевод статьи подготовлен в преддверии старта курса «Android Developer. Professional».

Официальное руководство по архитектуре приложений Android рекомендует использовать классы репозитории (Repository) для «предоставления чистого API, чтобы остальная часть приложения могла легко извлекать данные». Однако, на мой взгляд, если вы будете использовать в своем проекте этот паттерн, вы гарантированно увязнете в грязном спагетти-коде.
В этой статье я расскажу вам о «паттерне Репозиторий» и объясню, почему он на самом деле является антипаттерном для Android приложений.
Репозиторий
В вышеупомянутом руководстве по архитектуре приложений рекомендуется следующая структура для организации логики уровня представления:
Роль объекта репозитория в этой структуре такова:
Модули репозитория обрабатывают операции с данными. Они предоставляют чистый API, чтобы остальная часть приложения могла легко извлекать эти данные. Они знают, откуда брать данные и какие вызовы API выполнять при их обновлении. Вы можете рассматривать репозитории как посредников между различными источниками данных, такими как постоянные модели, веб-службы и кэши.
По сути, руководство рекомендует использовать репозитории для абстрагирования источника данных в вашем приложении. Звучит очень разумно и даже полезно, не правда ли?
Однако давайте не будем забывать, что болтать — не мешки ворочать (в данном случае — писать код), а раскрывать архитектурные темы с помощью UML диаграмм — тем более. Настоящая проверка любого архитектурного паттерна — это реализация в коде с последующим выявлением его преимуществ и недостатков. Поэтому давайте подыщем для обзора что-нибудь менее абстрактное.
Репозиторий в Android Architecture Blueprints v2
Около двух лет назад я рецензировал «первую версию» Android Architecture Blueprints. По идее они должны были реализовывать чистый пример MVP, но на практике эти блюпринты вылились в достаточно грязную кодовую базу. Они действительно содержали интерфейсы с именами View и Presenter, но не устанавливали никаких архитектурных границ, так что это по сути был не MVP. Вы можете посмотреть данный код ревью здесь.
С тех пор Google обновил архитектурные блюпринты с использованием Kotlin, ViewModel и других «современных» практик, включая репозитории. Эти обновленные блюпринты получили приставку v2.
Давайте же посмотрим на интерфейс TasksRepository из блюпринтов v2:
Даже до начала чтения кода можно обратить внимание на размер этого интерфейса — это уже тревожный звоночек. Такое количество методов в одном интерфейсе вызвало бы вопросы даже в больших Android проектах, но мы говорим о приложении ToDo, в котором всего 2000 строк кода. Почему этому достаточно тривиальному приложению нужен класс с такой огромной поверхностью API?
Репозиторий как Божественный объект (God Object)
Ответ на вопрос из предыдущего раздела кроется в именах методов TasksRepository. Я могу примерно разделить методы этого интерфейса на три непересекающихся группы.
Теперь давайте определим сферы ответственности каждой из вышеперечисленных групп.
Группа 1 — это в основном реализация паттерна Observer с использованием средства LiveData. Группа 2 представляет собой шлюз к хранилищу данных плюс два метода refresh , которые необходимы, поскольку за репозиторием скрывается удаленное хранилище данных. Группа 3 содержит функциональные методы, которые в основном реализуют две части логики домена приложения (завершение задач и активация).
Итак, у этого единого интерфейса есть три разных круга обязанностей. Неудивительно, что он такой большой. И хотя можно утверждать, что наличие первой и второй группы как части единого интерфейса допустимо, добавление третьей — неоправданно. Если этот проект нужно будет развивать дальше и он станет настоящим приложением для Android, третья группа будет расти прямо пропорционально количеству потоков доменов в проекте. Мда.
У нас есть специальный термин для классов, которые объединяют так много обязанностей: Божественные объекты. Это широко распространенный антипаттерн в приложениях на Android. Activitie и Fragment являются стандартными подозреваемыми в этом контексте, но другие классы тоже могут вырождаться в Божественные объекты. Особенно, если их имена заканчиваются на “Manager”, верно?
Погодите… Мне кажется, я нашел более подходящее название для TasksRepository:
Теперь имя этого интерфейса намного лучше отражает его обязанности!
Анемичные репозитории
Здесь вы можете спросить: «Если я вынесу доменную логику из репозитория, решит ли это проблему?». Что ж, вернемся к «архитектурной диаграмме» из руководства Google.
Если вы захотите извлечь, скажем, методы completeTask из TasksRepository, куда бы вы их поместили? Согласно рекомендованной Google «архитектуре», вам нужно будет перенести эту логику в одну из ваших ViewModel. Это не кажется таким уж плохим решением, но как раз таким оно на самом деле и является.
Например, представьте, что вы помещаете эту логику в одну ViewModel. Затем, через месяц, ваш менеджер по работе с клиентами хочет разрешить пользователям выполнять задачи с нескольких экранов (это релевантно по отношению ко всем ToDo менеджерам, которые я когда-либо использовал). Логика внутри ViewModel не может использоваться повторно, поэтому вам нужно либо продублировать ее, либо вернуть в TasksRepository. Очевидно, что оба подхода плохи.
Лучшим подходом было бы извлечь этот доменный поток в специальный объект, а затем поместить его между ViewModel и репозиторием. Затем разные ViewModel смогут повторно использовать этот объект для выполнения этого конкретного потока. Эти объекты известны как «варианты использования» или «взаимодействия». Однако, если вы добавите варианты использования в свою кодовую базу, репозитории станут по сути бесполезным шаблоном. Что бы они ни делали, это будет лучше сочетаться с вариантами использования. Габор Варади уже освещал эту тему в этой статье, поэтому я не буду вдаваться в подробности. Я подписываюсь почти под всем, что он сказал о «анемичных репозиториях».
Но почему варианты использования намного лучше репозиториев? Ответ прост: варианты использования инкапсулируют отдельные потоки. Следовательно, вместо одного репозитория (для каждой концепции домена), который постепенно разрастается в Божественный объект, у вас будет несколько узконаправленных классов вариантов использования. Если поток зависит от сети, и от хранимых данных, вы можете передать соответствующие абстракции в класс варианта использования, и он будет «проводить арбитраж» между этими источниками.
В общем, похоже, что единственный способ предотвратить деградацию репозиториев до Божественных классов, избегая при этом ненужных абстракций, — это избавиться от репозиториев.
Репозитории вне Android.
Теперь вы можете задаться вопросом, являются ли репозитории изобретением Google. Нет, не являются. Шаблон репозитория был описан задолго до того, как Google решил использовать его в своем «руководстве по архитектуре».
Например, Мартин Фаулер описал репозитории в своей книге «Паттерны архитектуры корпоративных приложений». В его блоге также есть гостевая статья, описывающая ту же концепцию. По словам Фаулера, репозиторий — это просто оболочка вокруг уровня хранения данных, которая предоставляет интерфейс запросов более высокого уровня и, возможно, кэширование в памяти. Я бы сказал, что, с точки зрения Фаулера, репозитории ведут себя как ORM.
Эрик Эванс в своей книге Domain Driven Design также описывал репозитории. Он написал:
Клиенты запрашивают объекты из репозитория, используя методы запросов, которые выбирают объекты на основе критериев, указанных клиентом — обычно значения определенных атрибутов. Репозиторий извлекает запрошенный объект, инкапсулируя механизм запросов к базе данных и сопоставления метаданных. Репозитории могут реализовывать различные запросы, которые выбирают объекты на основе любых критериев, которые требует клиент.
Обратите внимание, что вы можете заменить «репозиторий» в приведенной выше цитате на «Room ORM», и это все равно будет иметь смысл. Итак, в контексте Domain Driven Design репозиторий — это ORM (реализованный вручную или с использованием стороннего фреймворка).
Как видите, репозиторий не был изобретен в мире Android. Это очень разумный паттерн проектирования, на котором построены все ORM фреймворки. Однако обратите внимание, чем репозитории не являются: никто из «классиков» никогда не утверждал, что репозитории должны пытаться абстрагироваться от различия между доступом к сети и к базе данных.
На самом деле, я почти уверен, что они сочтут эту идею наивной и обреченной на провал. Чтобы понять, почему, вы можете прочитать другую статью, на этот раз Джоэла Спольски (основателя StackOverflow), под названием «Закон дырявых абстракций». Проще говоря: работа в сети слишком отличается от доступа к базе данных, чтобы ее можно было абстрагировать без значительных «утечек».
Как репозиторий стал антипаттерном в Android
Итак, неужели в Google неверно истолковали паттерн репозитория и внедрили в него «наивную» идею абстрагироваться от доступа к сети? Я в этом сомневаюсь.
Я нашел самую древнюю ссылку на этот антипаттерн в этом репозитории на GitHub, который, к сожалению, является очень популярным ресурсом. Я не знаю, изобрел ли этот антипаттерн конкретно этот автор, но похоже, что именно это репо популяризировало общую идею внутри экосистемы Android. Разработчики Google, вероятно, взяли его оттуда или из одного из вторичных источников.
Заключение
Итак, репозиторий в Android превратился в антипаттерн. Он хорошо выглядит на бумаге, но становится проблематичным даже в тривиальных приложениях и может вылиться в настоящие проблемы в более крупных проектах.
Например, в другом «блюпринте» Google, на этот раз для архитектурных компонентов, использование репозиториев в конечном итоге привело к таким жемчужинам, как NetworkBoundResource. Имейте в виду, что образец браузера GitHub по-прежнему является крошечным
2 KLOC приложением.
Насколько я убедился, «паттерн репозитория», как он определен в официальных документах, несовместим с чистым и поддерживаемым кодом.
Спасибо за прочтение и, как обычно, вы можете оставлять свои комментарии и вопросы ниже.
Источник



