- Как реализовать чистую архитектуру на Android?
- Что вы найдёте в этой статье?
- Важность архитектуры приложений
- Пример
- Какое наименее гибкое решение?
- Как понять архитектуру приложений в Android?
- Применение архитектуры в Android
- Что это за слои?
- 1. Уровень представления
- 2. Уровень бизнес-логики
- 3. Уровень данных
- Как слои взаимодействуют?
- В теории:
- На практике:
- Заключительные замечания по архитектуре приложений
- Clean Architecture с Kotlin
- Зачем нужен чистый подход?
- Какие бывают слои?
- Что такое Domain-слой?
- UseCases
- Репозитории
- Что такое Data-слой?
- Clean Architecture в Android для начинающих
- Немного теории
- Прагматичный подход
- Практическая часть — небольшое приложение для книжного каталога
- Модуль домена
- Модуль домена
- Слой данных
- Слой презентации или приложения
Как реализовать чистую архитектуру на Android?

Что вы найдёте в этой статье?
В 2016 году я начал изучать Java, а в начале 2017 года — Android. С самого начала я уже знал, что существует понятие архитектуры приложений, но не знал, как это применить в своём коде. Я находил много разных гайдов, но понятнее от этого мне не становилось.
Эта статья — именно та, которую мне хотелось бы прочитать в начале своего пути.
Важность архитектуры приложений
Многие компании проводят технические тесты для кандидатов, которые проходят отбор. Тесты могут отличаться, но есть то, что их объединяет. Все они требуют понимания и умения применения хорошей программной архитектуры.
Хорошая программная архитектура позволяет легко понимать, разрабатывать, поддерживать и внедрять систему [Книга «Чистая архитектура», глава 15]
Цель этой статьи — научить того, кто никогда не использовал архитектуру для разработки приложений на Android, делать это. Для этого мы рассмотрим практический пример приложения, при создании которого реализуем наименее гибкое решение и более оптимальное решение с использованием архитектуры.
Пример
Элементы в RecyclerView:

- Мы будем получать данные из API и показывать результаты пользователю.
- Результатом будет список пива с названием, описанием, изображением и содержанием алкоголя для каждого.
- Пиво должно быть упорядочено по градусу крепости.
Для решения этой задачи:
- Мы должны получить данные из API.
- Упорядочить элементы от самого низкого до самого высокого градуса крепости.
- Если содержание алкоголя меньше 5%, будет нарисован зелёный кружок, если оно находится между 5% и 8% — кружок будет оранжевым, а выше 8% — красный кружок.
- Наконец, мы должны показать список элементов.
Какое наименее гибкое решение?
Наименее гибким решением является создание одного класса, который будет выполнять четыре предыдущих пункта. Это то решение, которое любой из нас делал бы, если бы не знал, что такое архитектура приложений.
Результат для пользователя будет приемлемым: он увидит упорядоченный список на экране. Но если нам понадобится масштабировать эту систему, мы поймём, что структуру нелегко понять, разрабатывать дальше, поддерживать и внедрять.
Как понять архитектуру приложений в Android?
Я приведу очень простой пример. Представьте себе автомобильный завод с пятью зонами:
- Первая зона создает шасси.
- Вторая зона соединяет механические части.
- Третья зона собирает электронную схему.
- Четвертая область — покрасочная.
- И последняя область добавляет эстетические детали.
Это означает, что у каждой зоны есть своя ответственность, и они работают в цепочке с первой зоны по пятую для достижения результата.
У такой системы есть определённое преимущество. Если автомобиль выдаст ошибку после того, как он будет закончен, то в зависимости от его поведения мы будем знать, какой отдел должен её исправить, не беспокоя других.
Если мы захотим добавить больше эстетических деталей, мы обратимся непосредственно к пятому отделу. А если мы захотим изменить цвет, мы обратимся к четвёртому. И если мы изменим шасси, это никак не изменит способ работы покрасочной области. То есть мы можем точечно модифицировать нашу машину, не беспокоя при этом всю фабрику.
Кроме того, если со временем мы захотим открыть вторую фабрику для создания новой модели автомобиля, будет легче разделить рабочие зоны.
Применение архитектуры в Android
Мы собираемся добиться того, чтобы не было класса, который выполнял бы всю работу в одиночку: запрос данных от API, их сортировка и отображение. Всё это будет распределено по нескольким областям, которые называются слоями.
Что это за слои?
Для этого примера мы собираемся создать чистую архитектуру, которая состоит из трёх уровней, которые в свою очередь будут подразделяться на пять:
- Уровень представления.
- Уровень бизнес-логики.
- И уровень данных.
1. Уровень представления
Уровень представления — это пользовательский уровень, графический интерфейс, который фиксирует события пользователя и показывает ему результаты. Он также выполняет проверку того, что во введённых пользователем данных нет ошибок форматирования, а отображаемые данные отображаются корректно.
В нашем примере эти операции разделены между уровнем пользовательского интерфейса и уровнем ViewModel:
- Уровень пользовательского интерфейса содержит Activity и фрагменты, фиксирующие пользовательские события и отображающие данные.
- Уровень ViewModel форматирует данные так, что пользовательский интерфейс показывает их определённым образом.
Вместо использования ViewModel мы можем использовать другой слой, который выполняет эту функцию, просто важно понять обязанности каждого слоя.
В нашем примере слой пользовательского интерфейса отображает список пива, а слой ViewModel сообщает цвет, который вы должны использовать в зависимости от алкогольного диапазона.
2. Уровень бизнес-логики
На этом уровне находятся все бизнес-требования, которым должно соответствовать приложение. Для этого здесь выполняются необходимые операции. В нашем примере это сортировка сортов пива от самой низкой до самой высокой крепости.
3. Уровень данных
На этом уровне находятся данные и способ доступа к ним.
Эти операции разделены между уровнем репозитория и уровнем источника данных:
- Уровень репозитория реализует логику доступа к данным. Его ответственность заключается в том, чтобы получить данные. Необходимо проверить, где искать их в определённый момент. Например, вы можете сначала проверить локальную базу данных и, если там данных нет, сделать запрос к API и сохранить данные в базу данных. То есть он определяет способ доступа к данным. В нашем примере он запрашивает данные о пиве непосредственно у уровня, который взаимодействует с API.
- Уровень источника данных отвечает непосредственно за получение данных. В нашем примере он реализует логику доступа к API для получения данных о пиве.
Как слои взаимодействуют?
Давайте посмотрим на теоретический и практический подходы взаимодействия.
В теории:

Каждый слой должен общаться только со своими непосредственными соседями. В этом случае, если мы посмотрим на схему архитектуры программного обеспечения:
- Пользовательский интерфейс может общаться только с ViewModel.
- ViewModel может общаться только с уровнем бизнес-логики.
- Уровень бизнес-логики может общаться только с уровнем репозитория.
- И репозиторий может общаться только с источником данных.
На практике:
Структура пакетов в IDE Android Studio при чистой архитектуре:

У нас есть структура пакетов, в которой создаются классы, каждый из которых имеет свою зону ответственности.
Заключительные замечания по архитектуре приложений
Мы увидели, что каждый уровень архитектуры программного обеспечения имеет свою зону ответственности и все они связаны между собой.
Важно подчеркнуть, что ни разу не говорилось об используемых библиотеках или языках программирования, поскольку архитектура ориентирована на правильное структурирование кода, чтобы он был масштабируемым. Со временем библиотеки меняются, но принципы архитектуры сохраняются.
Дальше рекомендуется почитать о внедрении зависимостей, чтобы избежать создания экземпляров объектов непосредственно в классах архитектуры и, таким образом, иметь возможность выполнить модульное тестирование с помощью Mockito и JUnit.
Я делюсь репозиторием, где вы можете увидеть:
- Пример чистой архитектуры на Android с Kotlin.
- Использование LiveData для связи пользовательского интерфейса с ViewModel.
- Использование корутин.
- Kodein для внедрения зависимостей.
- JUnit и Mockito для тестирования бизнес-логики.
Источник
Clean Architecture с Kotlin

Apr 20, 2019 · 4 min read
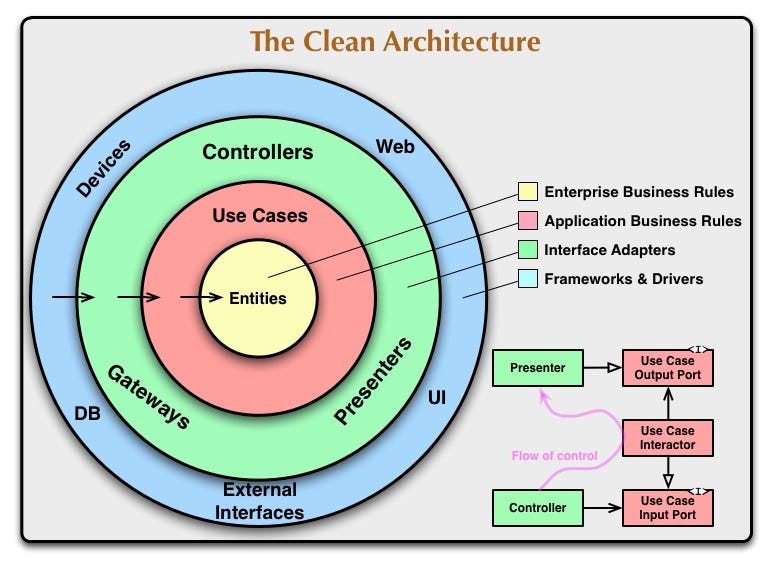
Мощная базовая архитектура — важный показатель для масштабируемости приложения. Внесение таких изменений, как замена API на обновленную и оптимизированную структуру API, требует переписать практически все приложение полностью.
Причина заключается в том, что код тесно связан с модулем данных ответа. Использование Чистой архитектуры (Clean architecture) помогает решить эту проблему. Это лучшее решение для крупных приложений с большим количеством функций и SOLID-принципами. Она была предложена Робертом С. Мартином (известным как Дядя Боб) в блоге “Чистый код” в 2012 году.
Зачем нужен чистый подход?
- Разделение кода на разные слои с назначенными обязанностями облегчает дальнейшую модификацию
- Высокий уровень абстракции
- Слабая связанность между частями кода
- Легкость тестирования кода
“Чистый код всегда выглядит так, будто написан с заботой.”
Какие бывают слои?

Domain-слой: Запускает независимую от других уровней бизнес-логику. Представляет собой чистый пакет kotlin без android-зависимостей.
Data-слой : Отправляет необходимые для приложения данные в domain-слой, реализуя предоставляемый доменом интерфейс.
Presentation-слой: Включает в себя как domain-, так и data-слои, а также является специфическим для android и выполняет UI-логику.
Что такое Domain-слой?
Базовый слой, соединяющий presentation-слой с data-слоем, в котором выполняется бизнес-логика приложения.

UseCases
Используется в качестве исполнителя логики приложения. Как видно из названия, для каждой функциональности можно создать отдельный прецедент.
Прецедент возвращает Flowable, который можно модифицировать в соответствии с требуемым наблюдателем. Есть два параметра. Т рансформер или ObservableTransformer, контролирующий выбор потока для выполнения логики, и репозиторий, который представляет собой интерфейс для data-слоя. Для передачи данных в data-слой используется HashMap.
Репозитории
Определяют функциональности в соответствии с требованиями прецедента, которые реализуются data-слоем.
Что такое Data-слой?
Этот слой предоставляет необходимые для приложения данные. Data-слой должен быть организован таким образом, чтобы данные могли быть использованы любым приложением без модификации логики представления.

API реализуют удаленную сеть. Он может включать любую сетевую библиотеку, такую как retrofit, volley и т. д. Аналогичным образом, DB реализует локальную базу данных.
В репозитории реализуются локальные, удаленные и любые другие источники данных. В примере выше класс NewsRepositoryImpl.kt реализует предоставляемый domain-слоем интерфейс. Он выступает в качестве единой точки доступа для data-слоя.
Что такое presentation-слой?
Presentation-слой реализует пользовательский интерфейс приложения. Этот слой выполняет только инструкции без какой-либо логики. Он внутренне реализует такие архитектуры, как MVC, MVP, MVVM, MVI и т. д. В этом слое соединяются все части архитектуры.

Папка DI обеспечивает внедрение всех зависимостей при запуске приложения, таких как сети, View Models, Прецеденты и т.д. DI в android реализуется с помощью dagger, kodein, koin или шаблона service locator. Все зависит от типа приложения. Я выбрал koin, поскольку его легче понять и реализовать, чем dagger.
Зачем использовать ViewModels?
В соответствии с документацией android, ViewModel:
Хранит и управляет данными пользовательского интерфейса с учетом жизненного цикла. С его помощью данные остаются целыми при изменении конфигурации, например, при повороте экрана.
Таким образом, ViewModel сохраняет данные при изменении конфигурации. Presenter в MVP привязан к представлению с интерфейсом, что усложняет тестирование, в то время как в ViewModel отсутствует интерфейс из-за архитектурно-ориентированных компонентов.
Базовый View Model использует CompositeDisposable для добавления всех observables и удаляет их на стадии жизненного цикла @OnCleared.
Класс data wrapper используется в LiveData в качестве вспомогательного класса, который уведомляет представление о состоянии запроса (запуск, результат и т.д.).
Каким образом соединяются все слои?
Каждый слой обладает собственной сущностью ( entities), специфичной для данного пакета. Mapper преобразовывает сущность одного слоя в другую. Все слои обладают разными сущностями, благодаря чему каждый из них полностью независим, и лишь необходимые данные могут быть переданы последующему слою.
Источник
Clean Architecture в Android для начинающих

Feb 17 · 7 min read

Даже до того, как я начал специализироваться на Android, меня, как разработчика, всегда восхищал хорошо структурированный, чистый и понятный в целом код.
“Задача архитектуры программного обеспечения — минимизация человеческих ресурсов, необходимых для создания и обслуживания требуемой системы”
Однако не всегда просто написать такой код, который легко тестировать и поддерживать, который облегчает всей команде совместную работу.
Теоретически обосновал достижение этих целей Robert Martin (он же Uncle Bob). Он написал три книги о применении «чистого» подхода при разработке программного обеспечения (ПО). Одна из этих книг называется «Чистая архитектура, профессиональное руководство по структуре и дизайну программного обеспечения (ПО )», она и явилась источником вдохновения при создании этой статьи.

Кто-то скажет, это так, но меня это не касается, ведь в моем приложении уже есть архитектура MVVM?
Что ж, возм о жно, Clean Architecture может показаться излишней в том случае, если вы работаете над простым проектом. Но как быть, если нужно разделить модули, протестировать их изолированно и помочь всей команде в работе над отдельными контейнерами кода? Подход Clean Architecture освобождает разработчиков от дотошного изучения программного кода, пытаясь понять функции и логику функционирования.
Немного теории

Вероятно, вы много раз видели эту послойную диаграмму. Правда, мне она не очень помогла понять, как преобразовать эти слои в подготовленном проекте Android. Но сначала разберемся с теорией и определениями:
· Сущности ( Entities): инкапсулируют наиболее важные правила функционирования корпоративного уровня. Сущности могут быть объектом с методами или набором из структур данных и функций.
· Сценарии использования ( Use cases): организуют поток данных к объектам и от них.
· Контроллеры, сетевые шлюзы, презентеры ( Controllers, Gateways, Presenters): все это набор адаптеров, которые наиболее удобным способом преобразуют данные из сценариев использования и формата объектов для передачи в верхний слой (обычно пользовательский интерфейс).
· UI, External Interfaces, DB, Web, Devices: самый внешний слой архитектуры, обычно состоящий из таких элементов, как пользовательские и внешние интерфейсы, базы данных и веб-фреймворки.
После прочтения этих определений я всегда оказывался в замешательстве и не был готов реализовать «чистый» подход в своих Android проектах.

Прагматичный подход
Типичный проект Android обычно требует разделения понятий между пользовательским интерфейсом, логикой функционирования и моделью данных. Поэтому, учитывая «теорию», я решил разделить свой проект на три модуля:
· Домен: содержит определения логики функционирования приложения, модели данных сервера, абстрактное определение репозиториев и определение сценариев использования. Это простой, чистый модуль kotlin (независимый от Android).
· Данные: содержит реализацию абстрактных определений доменного слоя. Может быть повторно использован любым приложением без модификаций. Он содержит репозитории и реализации источников данных, определение базы данных и ее DAO, определения сетевых API, некоторые средства преобразования для конвертации моделей сетевого API в модели базы данных и наоборот.

· Приложение (или слой представления): он зависит от Android и содержит фрагменты, модели представления, адаптеры, действия и т.д. Он также содержит указатель служб для управления зависимостями, но при желании вы можете использовать Hilt.
Практическая часть — небольшое приложение для книжного каталога
Чтобы применить на практике все эти “абстрактные” понятия, я разработал простое приложение, которое демонстрирует список книг, написанных дядей Бобом, и которое дает пользователям возможность помечать некоторые из них как “избранные”.

Модуль домена
Чтобы получить список книг, я использовал API Google книги. Это API возвращает список книг, отфильтрованных по параметру строки запроса:
В доменном слое мы определяем модель данных, сценарии использования и абстрактное определение репозитария книг. API возвращает список книг или томов с определенной информацией, такой как названия, авторы и ссылки на изображения.
data class Volume(val id: String, val volumeInfo: VolumeInfo)
Простая сущность класса данных:
Абстрактное определение репозитария книг
Сценарии использования “Get books”
Модуль домена
Чтобы получить список книг, я использовал API Google книги. Это API возвращает список книг, отфильтрованных по параметру строки запроса:
В доменном слое мы определяем модель данных, сценарии использования и абстрактное определение репозитария книг. API возвращает список книг или томов с определенной информацией, такой как названия, авторы и ссылки на изображения.
Простой объект (entity) класса данных:
data class Volume(val id: String, val volumeInfo: VolumeInfo)
Абстрактное определение репозитария книг:
Сценарии использования “Get books”:
Слой данных
Как уже отмечалось, слой данных должен реализовывать абстрактное определение слоя домена, поэтому нам нужно поместить в этот слой конкретную реализацию репозитория. Для этого мы можем определить два источника данных: «локальный» для обеспечения устойчивости и «удаленный» для извлечения данных из API.
Поскольку мы определили источник данных для управления постоянством (persistence), на этом уровне нам также необходимо определить базу данных (можно использовать Room) и ее объекты. Кроме того, рекомендуется создать несколько модулей (mappers) для сопоставления ответа API с соответствующим объектом базы данных. Помните, нам нужно, чтобы доменный слой был независим от слоя данных, поэтому мы не можем напрямую аннотировать объект доменного тома ( Volume ) с помощью аннотации @Entity room . Нам определенно нужен еще один класс BookEntity , и мы определим маппер (mapper) между Volume и BookEntity .
Слой презентации или приложения
В этом слое нам нужен фрагмент для отображения списка книг. Мы можем сохранить наш любимый подход MVVM. Модель представления принимает сценарии использования в своих конструкторах и вызывает соответствующий сценарий использования соответственно действиям пользователя (get books, bookmark, unbookmark).
Каждый сценариё использования вызывает соответствующий метод в репозитории:
Этот фрагмент только наблюдает за изменениями в модели представления и обнаруживает действия пользователя в пользовательском интерфейсе:
Теперь посмотрим, как мы выполнили связь между слоями:

Как видите, каждый слой обменивается данными только с ближними к нему, сохраняя независимость внутренних слоев от нижних. Таким образом, легче правильно определять тесты в каждом модуле, а разделение проблем поможет разработчикам совместно работать над различными модулями этого проекта.
Источник



