Pagination in Android with Paging 3, Retrofit and kotlin Flow

Haven’t you asked how does Facebook, Instagram, Twitter, Forbes, etc… let you “scroll infinitely” without reach a “end” of information in their apps? Wouldn’t you like to implement something like that?
This “endless scrolling” feature is commonly called “Pagination” and it’s nothing new. In a brief resume, pagination help you to load chunks of data associated with a “page” index.
Let’s assume you have 200 items to display in your RecyclerView. What you would do normally is just execute your request, get the response items and submit your list to your adapter. We already know that RecyclerView by it’s own is optimized for “recycle our views”. But do we really need to get those 200 items immediately? What if our user never reach the top 100, or top 50? The rest of the non displayed items are still keep on memory.
What pagination does (in conjunction with our API) is that it let us establish a page number, and how many items per page can we load. In that way, we can request for the next page of items only when we reach the bottom of our RecyclerView.
Non library approach
Before paging 3, you could have implemented Pagination by adding some listeners to your RecyclerView and those listeners would be triggered when you reach the bottom of your list. There are some good samples about it, here is a video with a vey detailed explanation (it’s on Indi, but it is understandable anyways).
A real PRODUCTION ready example is on the Plaid app. Look at their InfinteScrollListener class.
Android Jetpack Paging 3 and Flow
Today you gonna learn how to implement Pagination by using paging 3 from the android jetpack libraries. For my surprise the codelab of Paging 3 was one of the most easiest I have ever done. Florina Muntenescu did a great job with each step of the codelab, go check it out and give it a try. If you want to go straight to the sample code, check this pull request and see step by step how I implement paging 3 to this project.
Источник
How to Create User Interface Login & Register with Android Studio
ok, this is my first article in Medium. In this section, I want to share with you about the User Interface on Android and we will create a Login page and a Register page. Some components that I will use:
1. Viewpager
2. Fragment
3. Edittext
4. Button
5. Textview
6. Imageview
What about the results? let’s coding (follow step by step)
- Of course we must already have an Android Studio. if not, you can download it first on the official Android Studio website. If you already have one, please open your Android studio.
2. We create a new project by clicking “Start a new Android Studio project”. Fill in the application name column with “LoginApp”, then click next.
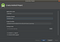
3. Select the minimum SDK you need or want, then click next.
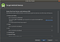

4. Select “Empty Activity” and click next. After that, the “Activity Name” and “Layout Name” columns will appear, in this section just leave it like that, then click finish.
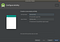
After you click finish, Android Studio will make you an Application with the name “LoginApp”.
After the application is successfully built, you can simply make adjustments to the following sections:
Open the colors.xml file in app/res/values/colors.xml, and change it like this:
Create a folder with the name “font” in the res folder, by right clicking on the res directory, select new / directory and name it “font”. After that, copy this font into font directory. (download the font 1 and font 2).
Create some Drawable Resource File in the drawable directory, by right-clicking on the drawable directory, select new / Drawable Resource File.
After that open file styles.xml and change like this :
Add the theme property in the Main Activity in the manifest, in the app / manifests / AndroidManifest.xml folder
So the AndroidManifest.xml file will be as follows:
After all the steps above are done, then make 2 fragments with the name fragment_login and fragment_register in the layout directory, by right-clicking on the layout directory, New/Fragment/Fragment (Blank)
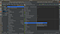
Uncheck:
include fragment factory methods? and include interface methods?
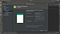
Adjustment of several layouts :
change the activity_main.xml layout, fragment_login.xml and fragment_register.xml so that it will be as below
Open the strings.xml file in the res / values / strings.xml directory and change it to something like the following :
So that the overall structure of the project will be as follows :

Connect fragments with viewpager
Create an inner class in the MainActivity.java class with the name AuthenticationPapterAdapter. This class is a derivative of the FragmentPagerAdapter class and serves to connect Fragments with ViewPager,
Then call the class in the onCreate() method in MainActivity.java and connect with viewpager
So the MainActivity.java class will be like this
The display of the final application will be like this
Источник
Кэшируем пагинацию в Android
Наверняка каждый Android разработчик работал со списками, используя RecyclerView. А также многие успели посмотреть как организовать пагинацию в списке, используя Paging Library из Android Architecture Components.
Все просто: устанавливаем PositionalDataSource, задаем конфиги, создаем PagedList и скармливаем все это вместе с адаптером и DiffUtilCallback нашему RecyclerView.
Но что если у нас несколько источников данных? Например, мы хотим иметь кэш в Room и получать данные из сети.
Кейс получается довольно кастомный и в интернете не так уж много информации на эту тему. Я постараюсь это исправить и показать как можно решить такой кейс.

Если вы все еще не знакомы с реализацией пагинации с одним источником данных, то советую перед чтением статьи ознакомиться с этим.
Как бы выглядело решение без пагинации:
- Обращение к кэшу (в нашем случае это БД)
- Если кэш пуст — отправка запроса на сервер
- Получаем данные с сервера
- Отображаем их в листе
- Пишем в кэш
- Если кэш имеется — отображаем его в списке
- Получаем актуальные данные с сервера
- Отображаем их в списке○
- Пишем в кэш
Такая удобная штука как пагинация, которая упрощает жизнь пользователям, тут нам ее усложняет. Давайте попробуем представить какие проблемы могут возникнуть при реализации пагинируемого списка с несколькими источниками данных.
Алгоритм примерно следующий:
- Получаем данные из кэша для первой страницы
- Если кэш пуст — получаем данные сервера, отображаем их в списке и пишем в БД
- Если кэш есть — загружаем его в список
- Если доходим до конца БД, то запрашиваем данные с сервера, отображаем их
- в списке и пишем в БД
Из особенностей такого подхода можно заметить, что для отображения списка в первую очередь опрашивается кэш, и сигналом загрузки новых данных является конец кэша.
В Google задумались над этим и создали решение, которое идет из коробки PagingLibrary — BoundaryCallback.
BoundaryCallback сообщает когда локальный источник данных “заканчивается” и уведомляет об этом репозиторий для загрузки новых данных.
На официальном сайте Android Dev есть ссылка на репозиторий с примером проекта, использующего список с пагинацией с двумя источниками данных: Network (Retrofit 2) + Database (Room). Для того, чтобы лучше понять как работает такая система попробуем разобрать этот пример, немного его упростим.
Начнем со слоя data. Создадим два DataSource.
В этом интерфейсе описаны запросы к API Reddit и классы модели (ListingResponse, ListingData, RedditChildrenResponse), в объекты которых будут сворачиваться ответы API.
И сразу сделаем модель для Retrofit и Room
Класс RedditDb.kt, который будет наследовать RoomDatabase.
Помним, что создавать класс RoomDatabase каждый раз для выполнения запроса к БД очень затратно, поэтому в реальном кейсе создавайте его единожды за все время жизни приложения!
И класс Dao с запросами к БД RedditPostDao.kt
Вы наверное заметили, что метод получения записей postsBySubreddit возвращает
DataSource.Factory. Это необходимо для создания нашего PagedList, используя
LivePagedListBuilder, в фоновом потоке. Подробнее об этом вы можете почитать в
уроке.
Отлично, слой data готов. Переходим к слою бизнес логики.Для реализации паттерна “Репозиторий” принято создавать интерфейс репозитория отдельно от его реализации. Поэтому создадим интерфейс RedditPostRepository.kt
И сразу вопрос — что за Listing? Это дата класс, необходимый для отображения списка.
Создаем реализацию репозитория MainRepository.kt
Давайте посмотрим что происходит в нашем репозитории.
Создаем инстансы наших датасорсов и интерфейсы доступа к данным. Для базы данных:
RoomDatabase и Dao, для сети: Retrofit и интерфейс апи.
Далее реализуем обязательный метод репозитория
который настраивает пагинацию:
- Создаем SubRedditBoundaryCallback, наследующий PagedList.BoundaryCallback<>
- Используем конструктор с параметрами и передадим все, что нужно для работы BoundaryCallback
- Создаем триггер refreshTrigger для уведомления репозитория о необходимости обновить данные
- Создаем и возвращаем Listing объект
В Listing объекте:
- livePagedList
- networkState — состояние сети
- retry — callback для вызова повторного получения данных с сервера
- refresh — тригер для обновления данных
- refreshState — состояние процесса обновления
Реализуем вспомогательный метод
для записи ответа сети в БД. Он будет использоваться, когда нужно будет обновить список или записать новую порцию данных.
Реализуем вспомогательный метод
для тригера обновления данных. Тут все довольно просто: получаем данные с сервера, чистим БД, записываем новые данные в БД.
С репозиторием разобрались. Теперь давайте взглянем поближе на SubredditBoundaryCallback.
В классе, который наследует BoundaryCallback есть несколько обязательных методов:
Метод вызывается, когда БД пуста, здесь мы должны выполнить запрос на сервер для получения первой страницы.
Метод вызывается, когда “итератор” дошел до “дна” БД, здесь мы должны выполнить запрос на сервер для получения следующей страницы, передав ключ, с помощью которого сервер выдаст данные, следующие сразу за последней записью локального стора.
Метод вызывается, когда “итератор” дошел до первого элемента нашего стора. Для реализации нашего кейса можем проигнорировать реализацию этого метода.
Дописываем колбэк для получения данных и передачи их дальше
Дописываем метод записи полученных данных в БД
Что за хэлпер PagingRequestHelper? Это ЗДОРОВЕННЫЙ класс, который нам любезно предоставил Google и предлагает вынести его в библиотеку, но мы просто скопируем его в пакет слоя логики.
* The helper provides an API to observe combined request status, which can be reported back to the * application based on your business rules. * */ // THIS class is likely to be moved into the library in a future release. Feel free to copy it // from this sample. public class PagingRequestHelper < private final Object mLock = new Object(); private final Executor mRetryService; @GuardedBy("mLock") private final RequestQueue[] mRequestQueues = new RequestQueue[]
mListeners = new CopyOnWriteArrayList<>(); /** * Creates a new com.memebattle.pagingwithrepository.domain.util.PagingRequestHelper with the given <@link Executor>which is used to run * retry actions. * * @param retryService The <@link Executor>that can run the retry actions. */ public PagingRequestHelper(@NonNull Executor retryService) < mRetryService = retryService; >/** * Adds a new listener that will be notified when any request changes <@link Status state>. * * @param listener The listener that will be notified each time a request’s status changes. * @return True if it is added, false otherwise (e.g. it already exists in the list). */ @AnyThread public boolean addListener(@NonNull Listener listener) < return mListeners.add(listener); >/** * Removes the given listener from the listeners list. * * @param listener The listener that will be removed. * @return True if the listener is removed, false otherwise (e.g. it never existed) */ public boolean removeListener(@NonNull Listener listener) < return mListeners.remove(listener); >/** * Runs the given <@link Request>if no other requests in the given request type is already * running. *
* If run, the request will be run in the current thread. * * @param type The type of the request. * @param request The request to run. * @return True if the request is run, false otherwise. */ @SuppressWarnings(«WeakerAccess») @AnyThread public boolean runIfNotRunning(@NonNull RequestType type, @NonNull Request request) < boolean hasListeners = !mListeners.isEmpty(); StatusReport report = null; synchronized (mLock) < RequestQueue queue = mRequestQueues[type.ordinal()]; if (queue.mRunning != null) < return false; >queue.mRunning = request; queue.mStatus = Status.RUNNING; queue.mFailed = null; queue.mLastError = null; if (hasListeners) < report = prepareStatusReportLocked(); >> if (report != null) < dispatchReport(report); >final RequestWrapper wrapper = new RequestWrapper(request, this, type); wrapper.run(); return true; > @GuardedBy(«mLock») private StatusReport prepareStatusReportLocked() < Throwable[] errors = new Throwable[]< mRequestQueues[0].mLastError, mRequestQueues[1].mLastError, mRequestQueues[2].mLastError >; return new StatusReport( getStatusForLocked(RequestType.INITIAL), getStatusForLocked(RequestType.BEFORE), getStatusForLocked(RequestType.AFTER), errors ); > @GuardedBy(«mLock») private Status getStatusForLocked(RequestType type) < return mRequestQueues[type.ordinal()].mStatus; >@AnyThread @VisibleForTesting void recordResult(@NonNull RequestWrapper wrapper, @Nullable Throwable throwable) < StatusReport report = null; final boolean success = throwable == null; boolean hasListeners = !mListeners.isEmpty(); synchronized (mLock) < RequestQueue queue = mRequestQueues[wrapper.mType.ordinal()]; queue.mRunning = null; queue.mLastError = throwable; if (success) < queue.mFailed = null; queue.mStatus = Status.SUCCESS; >else < queue.mFailed = wrapper; queue.mStatus = Status.FAILED; >if (hasListeners) < report = prepareStatusReportLocked(); >> if (report != null) < dispatchReport(report); >> private void dispatchReport(StatusReport report) < for (Listener listener : mListeners) < listener.onStatusChange(report); >> /** * Retries all failed requests. * * @return True if any request is retried, false otherwise. */ public boolean retryAllFailed() < final RequestWrapper[] toBeRetried = new RequestWrapper[RequestType.values().length]; boolean retried = false; synchronized (mLock) < for (int i = 0; i
Со слоем бизнес логики закончили, можем переходить к реализации представления.
В слое представления у нас новая MVVM от Google на ViewModel и LiveData.
В методе onCreate инициализируем ViewModel, адаптер списка, подписываемся на изменение названия подписки и вызываем через модель запуск работы репозитория.
Если вы не знакомы с механизмами LiveData и ViewModel, то рекомендую ознакомиться с уроками.
В модели реализуем методы, которые будут дергать методы репозитория: retry и refesh.
Адаптер списка будет наследовать PagedListAdapter. Тут все также как и работе с пагинацией и одним источником данных.
И все те же ViewHolder ы для отображения записи и итема состояния загрузки данных из сети.
Если мы запустим приложение, то можем увидеть прогресс бар, а затем и данные с Reddit по запросу androiddev. Если отключим сеть и долистаем до конца нашего списка, то будет сообщение об ошибке и предложение попытаться загрузить данные снова.
Все работает, супер!
И мой репозиторий, где я постарался немного упростить пример от Google.
На этом все. Если вы знаете другие способы как “закэшировать” пагинацию, то обязательно напишите в комменты.
Источник



