- LiveData with Coroutines and Flow — Part I: Reactive UIs
- Part I: Reactive UIs
- Scopes
- Android Architecture Components. Часть 3. LiveData
- LiveData with Coroutines and Flow — Part II: Launching coroutines with Architecture Components
- ViewModel scope
- Activity and Fragment scopes
- Application scope
- ViewModel + LiveData
- LiveData Coroutine builder with a switchMap
- Emit all items from another LiveData
- Cancelling coroutines
- One-shot vs multiple values
- One-shot operations with coroutines
- Receiving multiple values with LiveData
LiveData with Coroutines and Flow — Part I: Reactive UIs

This article is a summary of the talk I gave with Yigit Boyar at the Android Dev Summit 2019.
Part I: Reactive UIs (this post)
Part I: Reactive UIs
Since the early days of Android, we’ve learned very quickly that Android lifecycles were hard to understand, full of edge cases, and that the best way to stay sane was to avoid them as much as possible.
For this, we recommend a layered architecture, so we can write UI-independent code without thinking too much about lifecycles. For example, we can add a domain layer that holds business logic (what you app actually does) and a data layer.
Furthermore, we learned that the presentation layer could be split into different components with different responsibilities:
- The View — Activity or Fragment dealing with the lifecycle callbacks, user events and navigation, and
- A Presenter or a ViewModel — providing data to the View and mostly unaware of the lifecycle party going on in the View. This means there are no interruptions and no need to clean up when the View is recreated.
Naming aside, there are two mechanisms to send data from the ViewModel/Presenter to the View:
- Having a reference to the View and calling it directly. Usually associated with how Presenters work.
- Exposing observable data to observers. Usually associated with how ViewModels work.
This is a convention that is pretty well established in the Android community, but you’ll find articles that disagree. There are hundreds of blog posts defining Presenter, ViewModel, MVP and MVVM in different ways. My suggestion is that you focus on the characteristics of your presentation layer, and that you use the Android Architecture Components ViewModel which:
- Survives configuration changes, like rotations, locale changes, windows resizes, dark mode switch, etc.
- Has a very simple lifecycle. It has a single lifecycle callback, onCleared, which is called once its lifecycle owner is finished.
The ViewModel is designed to be used using the observer pattern:
- It should not have a reference to the View.
- It exposes data to observers, unaware of what those observers are. You could use LiveData for this.
When a View (an Activity, Fragment or any Lifecycle owner) is created, the ViewModel is obtained and it starts exposing data through one or more LiveDatas, which the View subscribes to.
This subscription can be set up with LiveData.observe or automatically with the Data Binding library.
Now, if the device is rotated then the View is destroyed (#1) and a new instance is created (#2):
If we had a reference to the activity in the ViewModel, we would need to make sure to:
- Clear it when the View is destroyed
- Avoid access if the View is in a transitional state.
But we don’t have to deal with this anymore with ViewModel+LiveData. This is why we recommend this approach in the Guide to App Architecture.
Scopes
As Activities and Fragments have an equal-or-shorter lifespan than ViewModels, we can start talking about the scope of operations.
An operation is anything you need to do in your app, like fetching data from the network, filtering results or calculating the arrangement of some text.
For any operation that you create, you need to think about its scope: the extent of time between launch and when it’s cancelled. Let’s look at two examples:
- You start an operation in an activity’s onStart and you stop it in onStop .
- You start an operation in a ViewModel’s init block and you stop it in onCleared() .
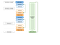
Looking at the diagram, we can locate where each operation makes sense.
- Fetching data in an operation scoped to the activity will force us to fetch it again after a rotation, so it should be scoped to the ViewModel instead.
- Arranging text makes no sense in an operation scoped to the ViewModel because after a rotation your text container might have changed shape.
Obviously, a real world app can have a lot more scopes than these. For example, in the Android Dev Summit App we can use:
- Fragment scopes, multiple per screen
- Fragment ViewModel scopes, one per screen
- Main Activity scope
- Main Activity ViewModel scope
- Application scope
This can produce a dozen different scopes so managing all can get overwhelming. We need a way to structure this concurrency!
One very convenient solution is Kotlin Coroutines.
We love using Coroutines in Android for many reasons. Some of them are:
- It’s easy to get off the main thread. Android apps are constantly switching between threads for a smooth UX and coroutines make this super simple.
- There’s minimal boilerplate. Coroutines are baked into the language so using things like suspend functions is a breeze.
- Structured concurrency. This means that you are forced to define the scope of your operation and that you can enjoy some guarantees that remove a lot of boilerplate, such as clean up code. Think of structured concurrency as “automatic cancellation”.
If you want an intro to coroutines, check out Android’s introduction and Kotlin’s official documentation.
Источник
Android Architecture Components. Часть 3. LiveData

Компонент LiveData — предназначен для хранения объекта и разрешает подписаться на его изменения. Ключевой особенностью является то, что компонент осведомлен о жизненном цикле и позволяет не беспокоится о том, на каком этапе сейчас находиться подписчик, в случае уничтожения подписчика, компонент отпишет его от себя. Для того, чтобы LiveData учитывала жизненный цикл используется компонент Lifecycle, но также есть возможность использовать без привязки к жизненному циклу.
Сам компонент состоит из классов: LiveData, MutableLiveData, MediatorLiveData, LiveDataReactiveStreams, Transformations и интерфейса: Observer.
Класс LiveData, являет собой абстрактный дженериковый класс и инкапсулирует всю логику работы компонента. Соответственно для создания нашего LiveData холдера, необходимо наследовать этот класс, в качестве типизации указать тип, который мы планируем в нем хранить, а также описать логику обновления хранимого объекта.
Для обновления значения мы должны передать его с помощью метода setValue(T), будьте внимательны поскольку этот метод нужно вызывать с main треда, в противном случае мы получим IllegalStateException, если же нам нужно передать значение из другого потока можно использовать postValue(T), этот метод в свою очередь обновит значение в main треде. Интересной особенностью postValue(T) является еще то, что он в случае множественного вызова, не будет создавать очередь вызовов на main тред, а при исполнении кода в main треде возьмет последнее полученное им значение. Также, в классе присутствует два колбека:
onActive() — будет вызван когда количество подписчиков изменит свое значение с 0 на 1.
onInactive() — будет вызван когда количество подписчиков изменит свое значение с 1 на 0.
Их назначение соответственно уведомить наш класс про то, что нужно обновлять даные или нет. По умолчанию они не имеют реализации, и для обработки этих событий мы должны переопределить эти методы.
Давайте рассмотрим, как будет выглядеть наш LiveData класс, который будет хранить wife network name и в случае изменения будет его обновлять, для упрощения он реализован как синглтон.
В целом логика фрагмента следующая, если кто-то подписывается, мы инициализируем BroadcastReceiver, который будет нас уведомлять об изменении сети, после того как отписывается последний подписчик мы перестаем отслеживать изменения сети.
Для того чтобы добавить подписчика есть два метода: observe(LifecycleOwner, Observer ) — для добавления подписчика с учетом жизненного цикла и observeForever(Observer ) — без учета. Уведомления об изменении данных приходят с помощью реализации интерфейса Observer, который имеет один метод onChanged(T).
Выглядит это приблизительно так:
Примечание: Этот фрагмент только для примера, не используйте этот код в реальном проекте. Для работы с LiveData лучше использовать ViewModel(про этот компонент в следующей статье) или позаботиться про отписку обсервера вручную.
В случае использования observe(this,this) при повороте экрана мы будем каждый раз отписываться от нашего компонента и заново подписываться. А в случае использование observeForever(this) мы получим memory leak.
Помимо вышеупомянутых методов в api LiveData также входит getValue(), hasActiveObservers(), hasObservers(), removeObserver(Observer observer), removeObservers(LifecycleOwner owner) в дополнительных комментариях не нуждаются.
Класс MutableLiveData, является расширением LiveData, с отличием в том что это не абстрактный класс и методы setValue(T) и postValue(T) выведены в api, то есть публичные.
По факту класс является хелпером для тех случаев когда мы не хотим помещать логику обновления значения в LiveData, а лишь хотим использовать его как Holder.
Класс MediatorLiveData, как понятно из названия это реализация паттерна медиатор, на всякий случай напомню: поведенческий паттерн, определяет объект, инкапсулирующий способ взаимодействия множества объектов, избавляя их от необходимости явно ссылаться друг на друга. Сам же класс расширяет MutableLiveData и добавляет к его API два метода: addSource(LiveData , Observer ) и removeSource(LiveData ). Принцип работы с классом заключается в том что мы не подписываемся на конкретный источник, а на наш MediatorLiveData, а источники добавляем с помощью addSource(..). MediatorLiveData в свою очередь сам управляет подпиской на источники.
Для примера создадим еще один класс LiveData, который будет хранить название нашей мобильной сети:
И перепишем наше приложение так чтоб оно отображало название wifi сети, а если подключения к wifi нет, тогда название мобильной сети, для этого изменим MainActivity:
Как мы можем заметить, теперь наш UI подписан на MediatorLiveData и абстрагирован от конкретного источника данных. Стоит обратить внимание на то что значения в нашем медиаторе не зависят напрямую от источников и устанавливать его нужно в ручную.
Класс LiveDataReactiveStreams, название ввело меня в заблуждение поначалу, подумал что это расширение LiveData с помощью RX, по факту же, класс являет собой адаптер с двумя static методами: fromPublisher(Publisher publisher), который возвращает объект LiveData и toPublisher(LifecycleOwner lifecycle, LiveData liveData), который возвращает объект Publisher . Для использования этого класса, его нужно импортировать отдельно:
compile «android.arch.lifecycle:reactivestreams:$version»
Класс Transformations, являет собой хелпер для смены типизации LiveData, имеет два static метода:
map(LiveData , Function ) — применяет в main треде реализацию интерфейса Function и возвращает объект LiveData
, где T — это типизация входящей LiveData, а P желаемая типизация исходящей, по факту же каждый раз когда будет происходить изменения в входящей LiveData она будет нотифицировать нашу исходящую, а та в свою очередь будет нотифицировать подписчиков после того как переконвертирует тип с помощью нашей реализации Function. Весь этот механизм работает за счет того что по факту исходящая LiveData, является MediatiorLiveData.
switchMap(LiveData , Function ) — похож к методу map с отличием в том, что вместо смены типа в функции мы возвращаем сформированный объект LiveData.
Базовый пример можно посмотреть в репозитории: git
Источник
LiveData with Coroutines and Flow — Part II: Launching coroutines with Architecture Components
This article is part II of a summary of the talk I gave with Yigit Boyar at the Android Dev Summit 2019.
Part II: Launching coroutines with Architecture Components (this post)
Jetpack’s Architecture Components provide a bunch of shortcuts so you don’t have to worry about Jobs and cancellation. You simply have to choose the scope of your opeations:
ViewModel scope
This is one of the most common ways to launch a coroutine because most data operations begin in the ViewModel. With the viewModelScope extension, jobs are cancelled automatically when the ViewModel is cleared. Use viewModelScope.launch to start coroutines.
Activity and Fragment scopes
Similarly, you can scope an operation to a specific instance of a view if you use lifecycleScope.launch .
You can even have a narrower scope if you limit the operation to a certain lifecycle state with launchWhenResumed , launchWhenStarted or launchWhenCreated .
Application scope
There are good use cases for an application-wide scope (read all about it here) but, first, you should consider using WorkManager if your job must be executed eventually.
ViewModel + LiveData
So far we’ve seen how to start a coroutine but not how to receive a result from it. You could use a MutableLiveData like so:
But, since you will be exposing this result to your view, you can save some typing by using the liveData coroutine builder which launches a coroutine and lets you expose results through an immutable LiveData. You use emit() to send updates to it.
LiveData Coroutine builder with a switchMap
In some cases you want to start a coroutine whenever the value of a LiveData changes. For example when you need an ID before starting a data load operation. There’s a handy pattern for that using Transformations.switchMap:
result is an immutable LiveData that will be updated with the result from calling the fetchItem suspend function, whenever itemId has a new value.
Emit all items from another LiveData
This feature is less common but can also save some boilerplate: you can use emitSource passing a LiveData source. Useful when you want to emit an initial value first and a succession of values later.
Cancelling coroutines
If you use any of the patterns above you don’t have to explicitly cancel jobs. However, there’s an important thing to remember: coroutine cancellation is cooperative.
This means that you have to help Kotlin stop a job if the calling coroutine is cancelled. Let’s say you have a suspend function that starts an infinite loop. Kotlin has no way of stopping that loop for you, so you need to cooperate, checking if the job is active regularly. You can do that by checking the isActive property.
By the way if you use any of the functions in kotlinx.coroutines (like delay ), you should know they’re all cancellable, meaning that they do that check for you.
That said, I recommend you add the check regardless, since it could happen that someone removes that delay call in the future, introducing a subtle bug in your code.
One-shot vs multiple values
To understand coroutines (and reactive UIs for that matter) we need to make an important distinction between:
- One-shot operations: They run once and can return a result
- Operations that return multiple values: Subscriptions to a source of data that can emit multiple values over time.
One-shot operations with coroutines
Using suspend functions and calling them with viewModelScope or liveData<> is a very convenient way to run non-blocking operations.
However, things get a bit more complicated when we’re listening to changes.
Receiving multiple values with LiveData
I covered this topic in LiveData beyond the ViewModel (2018), where I talked about patterns you could use to work around the fact that LiveData was never designed as a fully-featured streams builder.
Nowadays, a better approach is to use Kotlin’s Flow (warning: some parts are still experimental). Flow is similar to the reactive streams features within RxJava.
However, while coroutines make non-blocking one-shot operations way easier, this is not the same case for Flow. Streams are still hard to grasp. Still, if you want to create fast and solid reactive UIs, I’d say it’s worth the time investment. Since it’s part of the language and a small dependency, many libraries are starting to add Flow support (such as Room).
So, instead of LiveData, we can expose Flows from the Data Source and the Repository but the ViewModel still exposes LiveData because it’s lifecycle-aware.
Источник



