- Голосовой ввод android studio
- Распознавание и генерация речи в Android
- Программируем распознавание речи в Android
- Генерация речи в Android
- Управление голосом в приложениях на Android
- Как встроить голосового помощника в любое мобильное приложение. Разбираем на примере Habitica
- Что нужно для работы
- Порядок действий
Голосовой ввод android studio
В этом уроке мы научим свою программу слушать хозяина. Мы научимся использовать в Android приложении функцию speech to text, то есть преобразование голоса в текст, что будет происходить с использованием стандартных возможностей Android и Google через RecognizerIntent. Для успешной работы приложения нужно подключение к Интернет. Распознаватель речи будет запускаться при нажатии пользователя на кнопку, а произнесенные слова будут отображаться в отведенном для этого элементе TextView.
Создадим новый проект и начнем. Для начала оформим интерфейс приложения. Как уже только что упоминалось, оно будет иметь всего 2 элемента: кнопку Button и элемент TextView. Открываем файл activity_main.xml и добавляем туда эти элементы:
При нажатии на кнопку будет вызываться RecognizerIntent activity, которая будет производить распознавание голоса, входящего в устройство из микрофона, и преобразовывать его в текст. Для обработки полученных данных будет использоваться функция onActivityResult (), она используется всегда, если мы запускаем какое то другое activity и желаем получить из него назад (как ответ) некоторые данные.
По сути, вся работа в этом случае (и в подобных ему) выполняется в 2 основных шага:
— первый шаг — это выполнение activity на результат startActivityForResult, где мы задаем, какую activity хотим запустить и определяем подробности своего запроса;
— второй шаг — обработка функции onActivityResult (), которая проверяет оценку успешности результата запроса и обрабатывает полученные данные.
В результате своего запроса мы будем получать массив из слов и фраз, которые программе покажутся похожими на то, что пользователь промямлит при вызове действия ACTION_RECOGNIZE_SPEECH (говорить для распознавания и преобразования в текст), а далее эти слова мы отображаем в элементе TextView. Чтобы реализовать это все, открываем файл MainActivity.java и добавляем следующее:
Теперь запускаем приложение, нажимаем кнопку «Сказать слово» и рассказываем приложению обо всех своих бедах (простите за эти роскошные скриншоты):


Как видите, оно нас понимает.
Напомню также о уроке по функции чтения текста вслух Text To Speech.
Источник
Распознавание и генерация речи в Android
 Последнее время большой интерес у пользователей вызывает возможность распознавания речи в телефонах. Огромная заслуга в популяризации этого направления принадлежит компании Aple, однако Google также располагает подобными технологиями. Собственно этой теме и будет посвящена данная статья. Мы разработаем приложение, которое будет распознавать речь пользователя и воспроизводить результат с помощью голосового движка «Text To Speech» (TTS). Отметим, что распознавание происходит на серверах Google, поэтому для работы приложению необходимо разрешить использовать коммуникационные возможности. Кроме того, распознавание речи не работает на эмуляторе. Тестировать программу необходимо на реальном устройстве.
Последнее время большой интерес у пользователей вызывает возможность распознавания речи в телефонах. Огромная заслуга в популяризации этого направления принадлежит компании Aple, однако Google также располагает подобными технологиями. Собственно этой теме и будет посвящена данная статья. Мы разработаем приложение, которое будет распознавать речь пользователя и воспроизводить результат с помощью голосового движка «Text To Speech» (TTS). Отметим, что распознавание происходит на серверах Google, поэтому для работы приложению необходимо разрешить использовать коммуникационные возможности. Кроме того, распознавание речи не работает на эмуляторе. Тестировать программу необходимо на реальном устройстве.
На самом деле работать с распознаванием и синтезом речи в Android очень просто. Все сложные вычисления скрыты от нас в довольно элегантную библиотеку с простым API. Вы сможете осилить этот урок, даже если имеете весьма поверхностные знания о программировании для Android.
Давайте создадим новый проект в Eclipse. Для наших нужд понадобится версия SDK не меньше 8. Опишем в общих чертах создаваемую программу. При запуске приложения пользователю будет показана кнопка, после нажатия на которую пользователю будет предложено надиктовать фразу. Затем будет осуществлено распознавание и будет показан список возможных вариантов. Поскольку технологии распознавания речи далеки от совершенства, программа не может ручаться за точность результата, именно поэтому будет предложено несколько вариантов. После того, как пользователь выберет один из них, будет запущен генератор голоса, который воспроизведет выбранную фразу.
Нам понадобится несколько текстовых строк, объявим их в фале «res/values/strings.xml»
Откроем файл «res/layout/main.xml» и зададим шаблон дизайна приложения. Для этого переключимся из графического в XML редактор и изменим содержимое файла
Добавим в Linear Layout элемент Text View
обратите внимание, TextView ссылается на строку intro, которую мы задали в файле strings.xml.
После Text View добавим кнопку
Пользователь будет нажимать эту кнопку, чтобы начать говорить. Кнопка имеет параметр id, через который ее можно вызвать из Java кода. После нажатия на кнопку пользователю показывается сообщение. Нам также понадобится TextView для вывода слов с предложениями
TextView будет использовать строковый ресурс. Нам также понадобится список для вариантов слов
ListView будет заполняться данными в процессе работы программы, поэтому для доступа к этому компоненту также требуется ID. Обратите также внимание на наличие ресурса drawable. Вы должны сохранить файл words_bg.xml в папке res
Ничего особенного. Вы можете настроить дизайн ListView по своему усмотрению. Нам осталось задать еще один элемент пользовательского интерфейса — шаблон для элемента ListView. Создайте новый файл res/layout/word.xml со следующим содержанием
Таким образом, каждый элемент списка представляет собой просто Text View.
Если Вы все сделали правильно, то при запуске должно получиться следующее
Программируем распознавание речи в Android
После того, как шаблон будущего приложения создан, можно перейти к кодированию. Откройте java файл главной Activity и добавьте в начало файла
Изменим немного декларацию главного класса
OnInitListener необходим для работы TTS движка. Внутри класса добавим объявления переменных перед методом onCreate
Внутри метода onCreate автоматически сгенерирован код, вызывающий метод родительского класса и устанавливающий главный контекст вывода.
Cоздадим переменные для работы с кнопкой и списком распознанных слов
Далее необходимо проверить поддерживается ли возможность распознавания голоса телефоном
Мы запрашиваем среду, поддерживается ли Recognizer Intent. Если поддерживается, мы говорим приложению, что нужно отслеживать щелчок пользователя по кнопке. Если интент не поддерживается, мы блокируем кнопку и выводим соответствующее сообщение пользователю.
Напишем код, обрабатывающий нажатие на кнопку. Внутри класса после метода OnCreate добавим метод OnClick.
Как видите, при нажатии на кнопку мы вызываем метод listenToSpeech().
Большая часть приведенного кода стандартна для программ, использующих распознавание голоса. Обратите внимание на параметр EXTRA_PROMPT. Он задает строку-приглашение для пользователя. Параметр EXTRA_MAX_RESULTS определяет максимальное число вариантов распознавания. В конце концов, мы вызываем startActivityForResult. Результат его работы будет передан в метод onActivityResult.
На следующем скриншоте показан экран в момент распознавания речи.
Определим метод onActivityResult
Обратите внимание, при проверке результата мы сравниваем переменную requestCode с константой VR_REQUEST, которую использовали ранее при вызове метода startActivityForResult. Таким образом, мы рассматриваем только результаты от нашего запроса. В метод возвращается 10 вариантов распознанных слов, которые мы записываем в список ArrayList. Этот список мы используем в ArrayAdapter компонента List View.
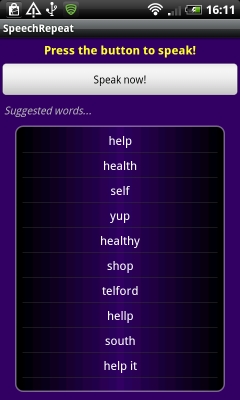
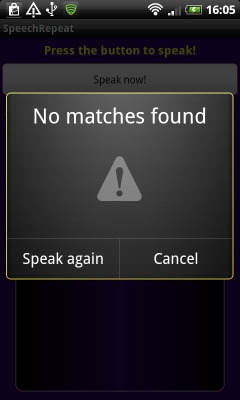
Если приложение справилось с задачей и смогло что-то распознать, вы увидите похожий н показанный на левом скриншоте результат. Если приложению не удалось распознать фразу, будет показано сообщение, как на правом скриншоте
Вот, собственно и все. Распознавание голоса в Android — довольно простая задача. Мы вызываем интент RecognizerIntent с требуемыми нами параметрами. Результат возвращается в onActivityResult.
Генерация речи в Android
Перейдем ко второй части нашего приложения, связанного с генерацией речи. Мы хотим, чтобы телефон проговаривал фразу из списка результатов. Мы должны определить строку, на которую щелкнул пользователь. Вернемся к методу onCreate и добавим в конец этого метода код
Мы используем метод setOnItemClickListener чтобы установить отслеживание щелчков для каждой строки. Внутри нового объекта OnItemClickListener мы описали метод onItemClick, который вызывается в ответ на щелчок по строке списка. Выбранная строка передается, как View в этот метод. Поскольку при проектировании шаблона приложения мы указали, что наш список состоит из TextView, мы преобразуем полученное значение в объект TextView и достаем из него строковое значение. Мы записываем это слово в лог и показываем пользователю Toast сообщение.
Если Вас не интересует процесс генерации речи, Вы можете остановиться и протестировать приложение.
Для генерации речи необходимо настроить движок TTS. Добавим код в конец метода onCreate
Как и в случае распознавания, результат интента возвращается в метод onActivityResult. В этом методе перед строкой super.onActivityResult(requestCode, resultCode, data); добавьте
Таким образом, мы проверяем наличие TTS движка, и если он не установлен — предлагаем пользователю установить соответствующую программу.
Чтобы завершить настройку TTS, добавим метод onInit, который вызывается при успешной инициализации TTS.
Здесь мы устанавливаем язык генератора речи.
Для того, чтобы заставить движок проговорить строку, нужно вызвать метод repeatTTS.speak. Вернемся к методу onCreate. Внутри метода onItemClick после строки Toast.makeText(SpeechRepeatActivity.this, «You said: «+wordChosen, Toast.LENGTH_SHORT).show(); добавьте следующий код
Таким образом, одновременно с Toast сообщением пользователь услышит сгенерированную речь. Отметим еще раз, что эмулятор не поддерживает распознавание речи, поэтому тестировать программу необходимо на телефоне.
Источник
Управление голосом в приложениях на Android
Началось все с того, что я посмотрел неплохой обзор (сравнение) Siri и Google Now. Кто из них лучше, спорить не буду, однако у меня лично планшет на Андроиде. Я подумал, а что если написать калькулятор полностью на голосовом управлении (удобно ли будет?). Но для начала пришлось немного разобраться с самим голосовым управление, точнее говоря с голосовым вводом (управления еще добиться надо). Кроме того, я только что скачал Android Studio, и мне не терпелось скорей опробовать ее на практике (ну на минипроекте). Что ж, начнем.
Кидаем на активность ListView и Button. В ЛистВью будем сохранять сами команды, точнее варианты одной команды, а кнопка будет вежливо спрашивать, чего мы желаем. Да, программа логикой не будет обладать, с ее помощью просто посмотрим саму реализацию.

Добавим так же в Манифест одно разрешение
И все, теперь можно переходить непосредственно к программированию. «Находим необходимые компоненты»:
Прописываем обработчик нажатия для кнопки, который вызовет метод startSpeak(), о котором мы поговорим далее:
Ну наконец закончилась «вода». Начинаем «говорить»:
Пришло время дать волю фантазии и решить какие команды использовать. Сам я сначала хотел показать на примере тетрисного танчика: диктовали бы ему «up», «down», «left», «fire» и так далее, но это сложно оставляю вам. Я же отдавал команды по смене цвета кнопки, выходу из приложения, открытию страниц в браузере, запуску карт и перезагрузке устройства. Что касается последнего, reboot, это команда будет работать, как я понял, только на рутованных устройствах. На телефоне у меня есть права СП и все хорошо работает, а вот на планшете, он просто игнорирует эту команду. В записи команд нет ничего сложного, думаю комментариев будет достаточно:
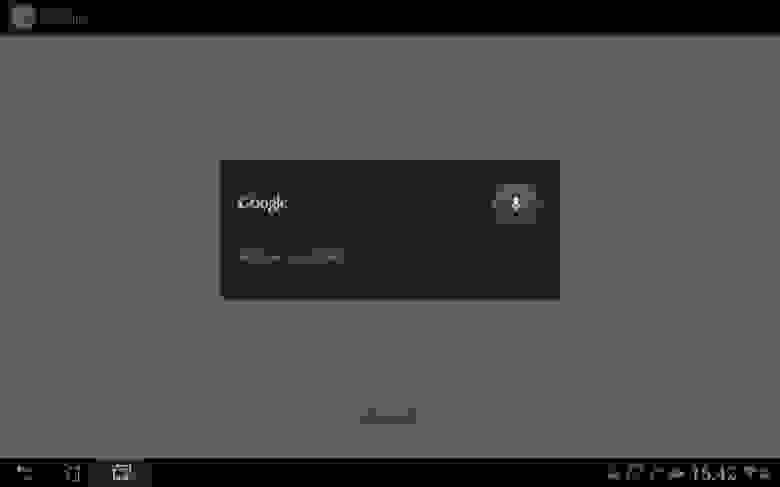
Так выглядит окно записи команд:
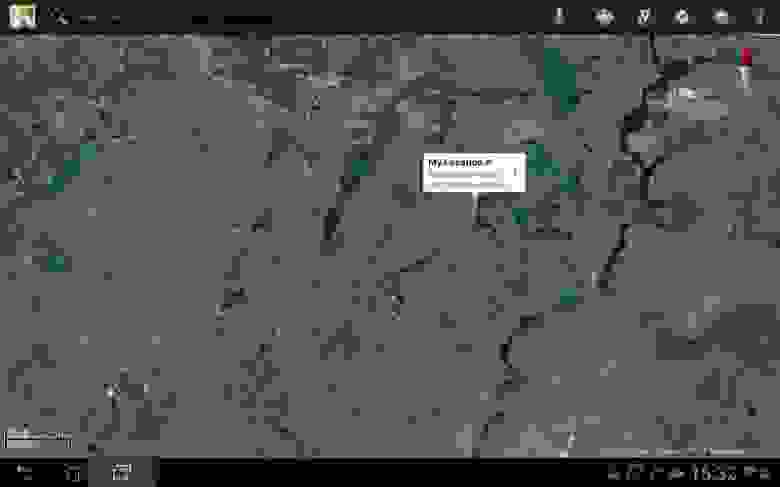
Скажем с красивым английским акцентом «maps». Вызвали Google Maps:
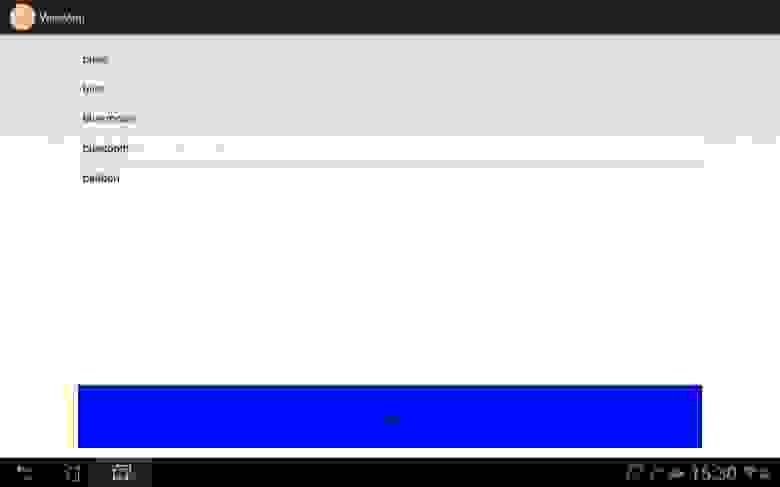
Как видите, в списке выводятся все возможные (похожие) слова и из них уже выбирается необходимое нам.
Ну и на «finish», я закончил беседу с бездушной (или нет?) машиной.
Надеюсь моя небольшая статья побудит кого-нибудь на создание (не, не терминатора) какого-либо перспективного проекта, который упростит повседневную жизнь людям, а вам принесет миллионы, ну или хотя бы окажется полезной. Дерзайте!
Источник
Как встроить голосового помощника в любое мобильное приложение. Разбираем на примере Habitica
Вам не кажется, что многие мобильные приложения стали бы куда удобнее, будь в них голосовое управление? Нет, речь не о том, чтобы вести беседы с банковским ассистентом в чате техподдержки. В основном было бы достаточно голосовой навигации по приложению или form-filling в режиме диалога.
На примере Habitica (опенсорсный app для закрепления привычек и достижения целей, написан на Kotlin) Виталя Горбачёв, архитектор решений в Just AI, показывает, как быстро и бесшовно встроить голосовой интерфейс в функционал любого приложения.
Но для начала давайте обсудим, почему голосовое управление мобильным приложением — это удобно? Начнем с очевидных вещей.
- Нам часто нужно воспользоваться приложением в момент, когда заняты руки: готовка, управление транспортным средством, тащим чемоданы, во время механической работы и так далее.
- Голос — важнейший инструмент для людей с нарушениями зрения.
Кейсы и так прозрачные, но на самом деле всё еще проще: в некоторых случаях набор голосом просто быстрее! Представьте — заказ авиабилета одной фразой «Купи мне билет на завтра на двоих в Самару» вместо долгого заполнения формы. При этом с возможностью задавать пользователю уточняющие вопросы: вечером или днем? с багажом или без?
Голос полезен при прохождении нами сценария «form-filling» и удобен для заполнения почти любых длинных форм, требующих от пользователя определенного объема информации. И такие формы присутствуют в большинстве мобильных приложений.
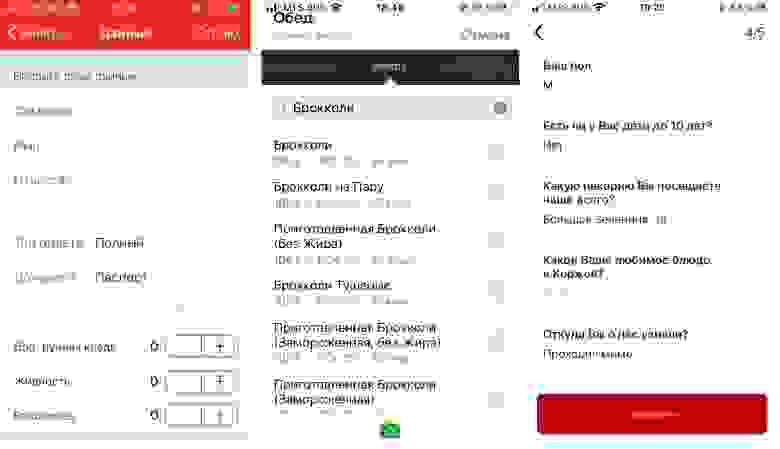
Слева направо: приложение РЖД «Пригород», дневник питания FatSecret (пользователям приходится заполнять форму несколько раз в день, выбирая из сотен продуктов), приложение пекарни «Коржов».
Из-за того, что сегодня голосовых ассистентов часто внедряют в чат поддержки и развиваются они именно оттуда, большинство компаний пытается запихнуть функционал приложения в чат. Пополнить баланс, узнать что-то о товаре или услуге… Это далеко не всегда удобно реализовано, а в случае с голосовым вводом и вовсе контрпродуктивно, хотя бы потому, что рапознавание речи часто работает совсем не идеально.
Правильный подход — встраивать ассистента бесшовно в уже существующий функционал приложения, в интерфейсе которого будет происходить заполнение формы, чтобы человек мог просто проверить, что он все правильно сказал, и нажать ОК.
Мы решили показать, как это можно сделать, на примере Habitica — это опенсорсное приложение, написаное почти на чистом Котлине. «Хабитика» отлично подходит под кейс с голосовым ассистентом — тут тоже для того, чтобы завести новую задачу, требуется заполнить довольно объемную форму. Попробуем заменить этот муторный процесс одной фразой с наводящими вопросами?
Я разбил туториал на две части. В этой статье мы разберемся, как добавить голосового ассистента в мобильное приложение и реализовать базовый сценарий (в нашем случае это готовый сценарий по уточнению прогноза погоды и времени — один из самых популярных в мире запросов к голосовым ассистентам). Во второй статье — а она выйдет уже скоро — мы научимся вызывать голосом определенные экраны и реализовывать сложные запросы внутри приложения.
Что нужно для работы
SDK. Мы взяли Aimybox как SDK для построения диалоговых интерфейсов. Из коробки Aimybox дает SDK ассистента и лаконичный и кастомизируемый UI (который при желании можно и вовсе переделать). При этом в качестве движков распознавания, синтеза и NLP можно выбрать из уже имеющихся или создать свой модуль.
По сути, Aimybox реализует архитектуру голосового помощника, стандартизируя интерфейсы всех этих модулей и правильным образом организуя их взаимодействие. Таким образом, внедряя это решение, можно значительно сократить время на разработку голосового интерфейса внутри своего приложения. Подробнее про Aimybox можно прочитать тут или тут.
Инструмент для создания сценария. Сценарий будем писать на JAICF (это опенсорсный и совершенно бесплатный фреймворк для разработки голосовых приложений от Just AI), а интенты распознавать с помощью Caila (NLU-сервис) в JAICP (Just AI Conversational Platform). Про них подробнее расскажу в следующей части туториала — когда дойдем до их использования.
Смартфон. Для тестов нам понадобится смартфон на Android, на котором мы будем запускать и тестить «Хабитику».
Порядок действий
Для начала форкаем «Хабитику» (ветку Release) и ищем самые важные для нас файлы. Я пользовался IDE Android Studio:
Находим MainActivity.kt — туда мы будем встраивать логику.
HabiticaBaseApplication.kt — там будем инициализировать Aimybox.
Activity_main.xml — туда встроим элемент интерфейса.
AndroidManifest.xml — там хранится вся структура приложения и его разрешения.
Согласно инструкции в репе «Хабитики» переименовываем habitica.properties.example и habitica.resources.example, убирая из них example, заводим проект в firebase под приложение и копируем в корень файл google-services.json.
Запускаем приложение, чтобы проверить, что сборка рабочая. Вуаля!
Для начала добавим зависимости Aimybox.
в dependencies и
И добавим сразу после compileOptions следующую строку, чтобы все работало корректно
Убираем флаги с разрешений RECORD_AUDIO и MODIFY_AUDIO_SETTINGS в AndroidManifest.xml, чтобы опции выглядели следующим образом.
Теперь инициализурем Aimybox в BaseApplication.
Добавляем AimyboxProvider при инициализации класса.

И делаем собственно инициализацию.
Вместо YOUR_KEY впоследствии будет ваш код от Aimybox Console.
Теперь встраиваем фрагмент в mainActivity.kt. Предварительно вставляем ФреймЛэйаут в activity_main.xml, прямо под фреймлэйаутом с id bottom_navigation
В сам MainActivity сначала добавляем эксплицитный запрос разрешений в OnCreate
И при их получении добавляем фрагмент в указанный выше фрейм.
Не забываем добавить в OnBackPressed возможности выйти из ассистента после захода в него.
Кроме этого, добавим в стили (styles.xml) в AppTheme
И отдельные стили чуть ниже:
Давайте проверим, добавился ли микрофончик. Запускаем приложение.
У нас посыпалась куча ошибок о неправильном синтаксисе. Исправляем все, как советует IDE.
Но микрофончик наползает на нижнюю навигацию. Давайте чуть поднимем. Добавим в стили выше в CustomAssistantButtonTheme:
Теперь подключим туда асисстента и проверим, нормально ли он отвечает. Для этого нам понадобится консоль Aimybox.
Начнем с того, что зайдем в app.aimybox.com под нашим акком гитхаба, сделаем новый проект, подключим пару навыков (я подключил DateTime для теста) и попробуем задать соответсвующие вопросы в асисстенте. Здесь же в настройках, в правом верхнем углу, берем apiKey, который вставляем в createAimybox вместо YOUR KEY.

Только надпись на английском, давайте поменяем приветственное сообщение в strings.constants.xml.

Вот ссылка на репозиторий с кодом.
В следующей статье про ассистента для «Хабитики» расскажу, как с помощью голоса не только узнавать погоду, а управлять непосредственно приложением — переходить по страничкам и добавлять привычки и задания.
Источник



