- Declaring dependencies
- What are dependency configurations
- Configuration inheritance and composition
- Resolvable and consumable configurations
- Советы по работе с Gradle для Android-разработчиков
- Небольшой оффтоп для тех, кому совсем ничего не понятно в Gradle-скриптах
- #1 Не редактируйте Gradle-скрипты через IDE
- #2 Обращайте внимание на соглашение по именованию модулей
- #3 Что выбрать: Kotlin vs Groovy
- #4 Как прописывать зависимости в многомодульных проектах
- Java platform plugin
- Описание зависимостей в extra properties
- Описание зависимостей в скриптовом плагине
- Описание зависимостей в buildSrc
- Композитные сборки
- #5 Как обновлять зависимости
- #6 Старайтесь не использовать feature-флаги в build config
- #7 Несколько слов про базовую структуру проекта
- #8 Не забывайте про matchingFallbacks
- #9 Убирайте ненужные build variant
- #10 В некоторых модулях, завязанных на Android Framework, можно не использовать Android Gradle Plugin
- #11 Как написать Gradle-плагин для CI на примере gitlab
- Шаг 1: в настройках проекта на gitlab создать переменные окружения
- Шаг 2: создать композитную сборку
- Шаг 3: написать плагин
- Шаг 4: подключить плагин
- В заключение
- Что ещё посмотреть
Declaring dependencies
Before looking at dependency declarations themselves, the concept of dependency configuration needs to be defined.
What are dependency configurations
Every dependency declared for a Gradle project applies to a specific scope. For example some dependencies should be used for compiling source code whereas others only need to be available at runtime. Gradle represents the scope of a dependency with the help of a Configuration. Every configuration can be identified by a unique name.
Many Gradle plugins add pre-defined configurations to your project. The Java plugin, for example, adds configurations to represent the various classpaths it needs for source code compilation, executing tests and the like. See the Java plugin chapter for an example.
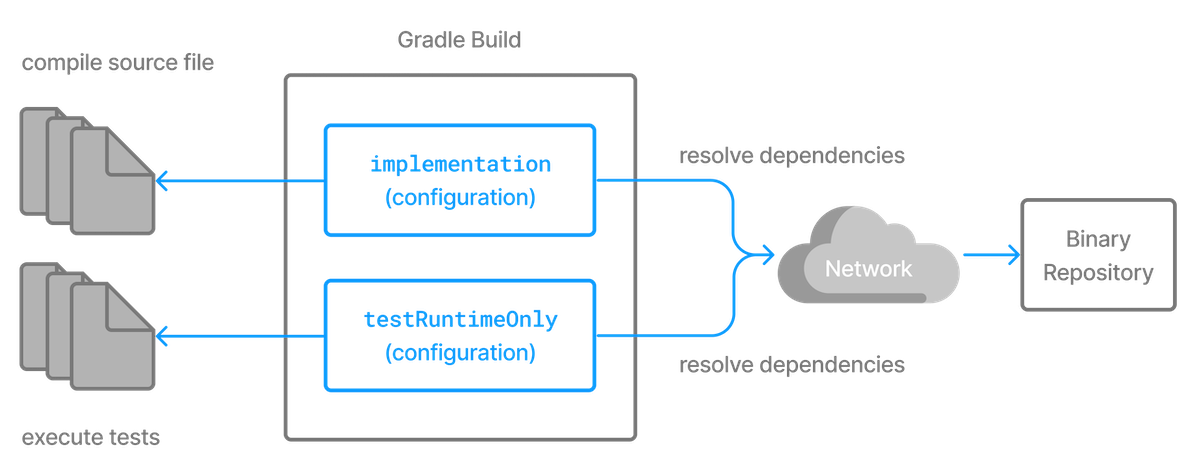
For more examples on the usage of configurations to navigate, inspect and post-process metadata and artifacts of assigned dependencies, have a look at the resolution result APIs.
Configuration inheritance and composition
A configuration can extend other configurations to form an inheritance hierarchy. Child configurations inherit the whole set of dependencies declared for any of its superconfigurations.
Configuration inheritance is heavily used by Gradle core plugins like the Java plugin. For example the testImplementation configuration extends the implementation configuration. The configuration hierarchy has a practical purpose: compiling tests requires the dependencies of the source code under test on top of the dependencies needed write the test class. A Java project that uses JUnit to write and execute test code also needs Guava if its classes are imported in the production source code.
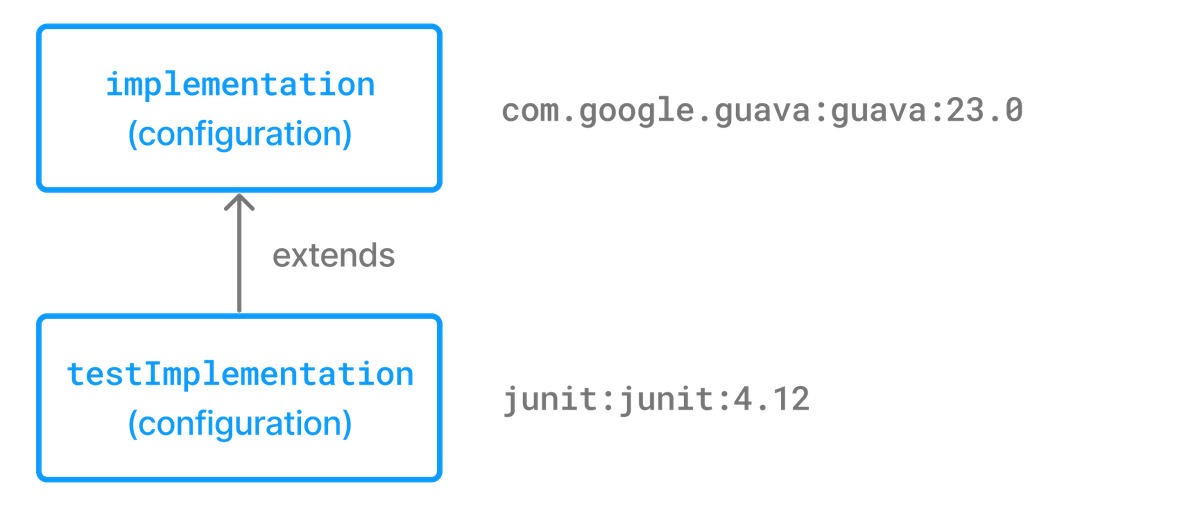
Under the covers the testImplementation and implementation configurations form an inheritance hierarchy by calling the method Configuration.extendsFrom(org.gradle.api.artifacts.Configuration[]). A configuration can extend any other configuration irrespective of its definition in the build script or a plugin.
Let’s say you wanted to write a suite of smoke tests. Each smoke test makes a HTTP call to verify a web service endpoint. As the underlying test framework the project already uses JUnit. You can define a new configuration named smokeTest that extends from the testImplementation configuration to reuse the existing test framework dependency.
Resolvable and consumable configurations
Configurations are a fundamental part of dependency resolution in Gradle. In the context of dependency resolution, it is useful to distinguish between a consumer and a producer. Along these lines, configurations have at least 3 different roles:
to declare dependencies
as a consumer, to resolve a set of dependencies to files
as a producer, to expose artifacts and their dependencies for consumption by other projects (such consumable configurations usually represent the variants the producer offers to its consumers)
For example, to express that an application app depends on library lib , at least one configuration is required:
Configurations can inherit dependencies from other configurations by extending from them. Now, notice that the code above doesn’t tell us anything about the intended consumer of this configuration. In particular, it doesn’t tell us how the configuration is meant to be used. Let’s say that lib is a Java library: it might expose different things, such as its API, implementation, or test fixtures. It might be necessary to change how we resolve the dependencies of app depending upon the task we’re performing (compiling against the API of lib , executing the application, compiling tests, etc.). To address this problem, you’ll often find companion configurations, which are meant to unambiguously declare the usage:
At this point, we have 3 different configurations with different roles:
someConfiguration declares the dependencies of my application. It’s just a bucket that can hold a list of dependencies.
compileClasspath and runtimeClasspath are configurations meant to be resolved: when resolved they should contain the compile classpath, and the runtime classpath of the application respectively.
This distinction is represented by the canBeResolved flag in the Configuration type. A configuration that can be resolved is a configuration for which we can compute a dependency graph, because it contains all the necessary information for resolution to happen. That is to say we’re going to compute a dependency graph, resolve the components in the graph, and eventually get artifacts. A configuration which has canBeResolved set to false is not meant to be resolved. Such a configuration is there only to declare dependencies. The reason is that depending on the usage (compile classpath, runtime classpath), it can resolve to different graphs. It is an error to try to resolve a configuration which has canBeResolved set to false . To some extent, this is similar to an abstract class ( canBeResolved =false) which is not supposed to be instantiated, and a concrete class extending the abstract class ( canBeResolved =true). A resolvable configuration will extend at least one non-resolvable configuration (and may extend more than one).
On the other end, at the library project side (the producer), we also use configurations to represent what can be consumed. For example, the library may expose an API or a runtime, and we would attach artifacts to either one, the other, or both. Typically, to compile against lib , we need the API of lib , but we don’t need its runtime dependencies. So the lib project will expose an apiElements configuration, which is aimed at consumers looking for its API. Such a configuration is consumable, but is not meant to be resolved. This is expressed via the canBeConsumed flag of a Configuration :
Источник
Советы по работе с Gradle для Android-разработчиков
Всем привет! Я пишу приложения под Android, в мире которого система сборки Gradle является стандартом де-факто. Я решил поделиться некоторыми советами по работе с системой с теми, у кого нет чёткого понимания, как правильно структурировать свои проекты и писать build-скрипты.

Часто разработчики используют Gradle по наитию и не изучают целенаправленно, потому что не всегда хватает ресурсов на инфраструктурные задачи. А если возникают какие-либо проблемы, то просто копируют готовые куски build-скриптов из ответов на Stack Overflow. Во многом проблема кроется в сложности и чрезмерной гибкости Gradle, а также в отсутствии описания лучших практик в официальной документации.
Поработав больше пяти лет на аутсорсе, я видел много проектов разной сложности. И на всех этих проектах build-скрипты писались по-разному, где-то встречались не очень удачные решения. Я провел небольшую ретроспективу и резюмировал свой опыт в виде разных советов по использованию Gradle и рассказал их на одном из наших внутренних митапов. В статье я перевел эти советы в текст.
Небольшой оффтоп для тех, кому совсем ничего не понятно в Gradle-скриптах
Я заметил, что в Android-сообществе встречаются люди, которые могут годами разрабатывать приложения, но при этом не понимать, как работает Gradle. И достаточно продолжительное время и я был одним из них. Но однажды всё же решил, что гораздо проще потратить время на системное изучение Gradle, чем постоянно натыкаться на непонятные проблемы.
А так как лучший способ изучить что-то — это попытаться рассказать об этом другим людям, то я подготовил рассказ об основах использования Gradle в контексте Android-разработки специально для тех, кто совсем не разбирается в теме. Так что, возможно, этот митап вам поможет.
#1 Не редактируйте Gradle-скрипты через IDE
Android studio умеет генерировать стартовый проект с базовой структурой и готовыми build-скриптами, а также удалять и добавлять модули в существующем проекте. А при редактировании Gradle-скриптов IDE нам заботливо подсказывает, что можно вносить изменения в скрипты через графический интерфейс в меню «File -> Project structure. «. И в начале своей карьеры я вполне успешно пользовался этим инструментом. Но у него есть существенный недостаток: IDE не запускает честную фазу конфигурации Gradle и не смотрит на то, что формируется в памяти при сборке, а всего лишь пытается как-то парсить build-скрипты. Зачастую этот инструмент не распознает то, что было написано вручную, что, на мой взгляд, перечеркивает его пользу.
Мой совет: лучше не редактировать скрипты через IDE, а использовать редактор кода.
#2 Обращайте внимание на соглашение по именованию модулей
В Gradle имя проекта (модуля) берется из соответствующего поля name в объекте Project или названия директории, в которой он лежит. В своей практике я видел разные стили именования модулей, например, в camel- или snake- кейсе: MyAwesomeModule , my_awesome_module . Но есть ли какие-то устоявшиеся соглашения об именах модулей? Кажется, официальная документация Gradle ничего нам об этом не говорит. Но нужно принять во внимание тот факт, что проекты Gradle при публикации в Maven будут соответствовать один к одному модулям Maven. И у Maven есть соглашение, что слова в названиях модулей должны разделяться через символ — . То есть правильнее будет такое название модуля: my-awesome-module .
#3 Что выбрать: Kotlin vs Groovy
Изначально в Gradle для DSL использовался язык Groovy, но впоследствии была добавлена возможность писать build-скрипты на Kotlin. Возникает вопрос: что же сейчас использовать? И однозначного ответа на него пока что нет.
Лично я за использование Kotlin, так как не очень хочу только лишь ради build-системы изучать ещё один язык — Groovy. Наверно, для всего Android сообщества DSL на Kotlin существенно понижает порог вхождения в Gradle. Кроме того, у build-скриптов на Kotlin лучше поддержка в IDE с автокомплитом, но, тем не менее, она все еще далека от идеала.
В качестве минуса Kotlin я бы выделил то, что могут встретиться какие-то старые плагины, которые изначально были заточены только под Groovy, и для их подключения придется потратить больше времени.
Если у вас старый большой проект с build-скриптами на Groovy, то могу посоветовать частично попробовать какие-то скрипты перевести на Kotlin, если вам понравится, то можно будет постепенно делать рефакторинг и переписывать все скрипты на Kotlin, не обязательно делать это единовременно.
#4 Как прописывать зависимости в многомодульных проектах
Возьмем небольшой пример проекта со следующей структурой:
Основной модуль, из которого собирается apk, зависит от feature-модулей, а также в нём прописаны какие-то внешние зависимости. feature-модули, в свою очередь, содержат транзитивные зависимости, которые могут пересекаться с зависимостями в других модулях.
В чем проблема такого проекта? Здесь будет тяжело глобально обновлять зависимости в каждом из файлов. Очень легко забыть поднять версию в одном из скриптов, и тогда возникнут конфликты. По умолчанию Gradle умеет разрешать такие конфликты, выбирая максимальную версию, так что, скорее всего, сборка будет успешной (поведение можно менять через resolution strategy).
Но, конечно же, сознательно допускать конфликты версий не стоит, и для решения этой проблемы есть официальный способ, описанный в документации Gradle, использование которого я никогда не встречал на практике. Вместо него сообщество придумало достаточно простой трюк: прописывать строки с зависимостями где-то глобально и обращаться к ним из build-скриптов. Тут я хочу рассмотреть эти способы чуть подробнее.
Java platform plugin
Разработчики Gradle предлагают для описания зависимостей создать отдельный специальный модуль, где будут описаны только зависимости с конкретными версиями. К этому модулю надо применить java platform plugin. Далее подключаем этот модуль в остальные модули и при указании каких-то внешних зависимостей не пишем конкретную версию:
Такие platform-проекты можно даже публиковать на внешние maven репозитории и переиспользовать. В качестве минуса подхода можно назвать то, что при мажорных обновлениях библиотек часто меняются не только версии, но и названия модулей, и тогда все равно придется вносить изменения сразу в нескольких скриптах.
Перейду к общепринятым в сообществе способам описания зависимостей.
Описание зависимостей в extra properties
Достаточно часто можно увидеть практику, когда строки с зависимостями хранят в extra properties корневого проекта, по сути это словарь, доступный всем дочерним модулям. Пример использования можно встретить в некоторых библиотеках от Google.
В корневом проекте описываем зависимости. Вот кусок build-скрипта из библиотеки Google, где зависимость возвращается функцией compatibility :
И обращаемся к ним из дочерних модулей:
Описание зависимостей в скриптовом плагине
Описанный способ с extra properties можно немного модифицировать и вынести описание зависимостей в скриптовый плагин, чтобы не засорять корневой проект. А уже скриптовый плагин можно применить или к корневому, или ко всем дочерним проектам сразу (через allprojects <> ), или к отдельным. Такой способ я тоже встречал.
Описание зависимостей в buildSrc
В buildSrc можно писать любой код, который будет компилироваться и добавляться в classpath build-скриптов. В последнее время стало популярно использовать buildSrc для описания там зависимостей. Например, в библиотеке Insetter Chris Banes так и делает.
Все, что нужно, — это добавить синглтон со строками в buildSrc, и он станет виден всем модулям в проекте:
Использовать buildSrc для зависимостей очень удобно, так как будут статические проверки и автокомплит в IDE:
Но у этого решения есть один недостаток: любое изменение в buildSrc будет инвалидировать весь кэш сборки, что может быть несущественно для средних и маленьких проектов, но выливаться в серьезные проблемы для больших команд.
Композитные сборки
Можно достичь похожего результата со статическими проверками и автокомплитом, используя композитные сборки, при этом избавившись от проблемы инвалидации всего кэша. Я расскажу про него лишь кратко, а подробный гайд по миграции с buildSrc можно прочитать в статье из блога Badoo или статье от Josef Raska.
В композитных сборках мы создаем так называемые «включенные сборки» (included build), в которых можно писать плагины и подключать их в своих модулях. Включенные сборки описываются в файле settings.gradle .
Если мы хотим всего лишь подсунуть в classpath build-скриптов строки с зависимостями, то достаточно создать пустой плагин, а рядом с ним положить тот же файл с зависимостями, который мы использовали раньше в buildSrc:
Все, что осталось сделать, — применить плагин к корневому проекту:
И мы получим практически тот же результат, как и с использованием buildSrc.
Выглядит так, что способ с композитными сборками самый подходящий и его можно сразу начинать использовать со старта проекта.
#5 Как обновлять зависимости
В любом активном проекте надо постоянно следить за обновлением библиотек. IDE умеет подсвечивать для каждого модуля, описанного в блоке dependencies <> , наличие новых стабильных версий в репозиториях:
Но этот инструмент работает только для зависимостей, описанных строковыми литералами в build-скриптах, а если мы попытаемся использовать способ с композитными сборками, buildSrc или extra properties, то IDE перестанет нам помогать. Кроме того, визуально просматривать build-скрипты в модулях, для того чтобы сделать обновление библиотек, на мой взгляд, не очень удобно.
Но есть решение — использовать gradle-versions-plugin. Для этого просто применяем плагин к корневому проекту и регистрируем task для проверки новых версий зависимостей. Этот task надо настроить, передав ему лямбду для определения нестабильных версий:
Теперь запуск команды ./gradlew dependencyUpdates выведет список зависимостей, для которых есть новые версии:
#6 Старайтесь не использовать feature-флаги в build config
Во многих проектах release, debug и другие сборки отличаются по функциональности. Например, в отладочных сборках могут быть включены какие-то логи, мониторинг сетевого трафика через прокси, debug menu для смены окружений и т.д. И часто для реализации такого используют флаги, прописанные в build config, например:
А дальше такие флаги используются в коде приложения:
И у такого решения есть недостатки. Довольно легко перепутать значения флагов и ветки if/else: if (enabled) <> else <> или if (disabled) <> else <> . Именно так однажды, во время рефакторинга, я случайно отправил в релиз то, что должно было включаться только в сборках для QA-отдела (думаю, у многих были похожие истории). Тогда проблему обнаружили оперативно, мы перевыпустили сборку в маркет. Кроме того, недостижимый код может быть скомпилирован и попасть в релиз (здесь я не буду рассуждать о том, что «мертвый» код может вырезаться из итогового приложения). Ну и многим известно, что любые операторы ветвления лучше заменять полиморфизмом. И в Gradle есть статический полиморфизм.
Вместо флагов можно использовать разные source set для различных build variant («src/release/java . «, «src/debug/java . «). А если такой код хочется вынести в отдельные модули, то можно использовать специальные конфигурации: debugImplementation , releaseImplementation и т.д. Тогда мы сможем написать код с одним и тем же интерфейсом, но разной реализацией для различных типов сборок.
Например, мы можем выделить debug menu в отдельный модуль и подключать его только для debug и QA-сборок:
А stub реализацию для релизной сборки можно реализовать через source set.
#7 Несколько слов про базовую структуру проекта
Совет немного не по теме, но я решил добавить его как часть своего опыта, так как модуляризация напрямую связана с Gradle.
Если для крупных проектов модуляризация кажется вполне очевидным решением, то не совсем понятно, как стоит поступать при старте небольших проектов или когда невозможно предсказать дальнейшее развитие кодовой базы продукта. Нужно ли выделять какие-то модули или достаточно начать с монолита? Я бы, помимо app модуля с основным приложением, всегда выделял как минимум два отдельных модуля:
- UI kit: стили, кастомные элементы управления, виджеты и т.д. Обычно элементы управления на всех экранах приложения делаются консистентно в одном стиле (а возможно, у вас целая дизайн-система), и если в какой-то момент захочется выделить feature-модуль, то он также будет опираться на единый UI kit. Заранее подготовленный модуль с элементами управления и стилями упростит задачу и не потребует значительного рефакторинга приложения.
- Common / utils: все утилитные классы и любые решения, которые не только потребуются в нескольких модулях, но и могут даже копироваться из проекта в проект. Особенно в контексте аутсорса такой модуль будет удобным при старте новых проектов. При вынесении классов в отдельный модуль, а не пакет, можно быть уверенным, что в его коде не окажется каких-либо бизнес сущностей конкретного приложения. Потенциально такой модуль может стать полноценной библиотекой, опубликованной в репозиторий.
#8 Не забывайте про matchingFallbacks
Часто, помимо debug и release , мы создаем и другие типы сборок, например, qa для тестов. И при создании модулей в приложении необязательно их прописывать в каждом build-скрипте. Достаточно при создании своего build type указать в модуле основного приложения те build type, которые следует выбирать при отсутствии каких-то конкретных:
#9 Убирайте ненужные build variant
Build variant формируются из всех возможных сочетаний product flavor и build type. Возьмем небольшой синтетический пример: создадим три build type – debug (отладочная сборка), release (сборка в маркет) и qa (сборка для тестирования), а во flavor вынесем разные сервера, на которые может смотреть сборка, – production и staging (тестовое окружение). Возможные build variant будут выглядеть так:
Очевидно, что сборка в маркет, которая будет смотреть на тестовое окружение, совершенно бессмысленна и не нужна ( stagingRelease ). И чтобы исключить ее, можно добавить variant filter:
#10 В некоторых модулях, завязанных на Android Framework, можно не использовать Android Gradle Plugin
Если какой-то из ваших модулей завязан на классы из Android Framework, то вовсе не обязательно сразу применять к нему Android Gradle Plugin и писать там файл манифеста. Модули с AGP — более тяжеловесные, чем чистые java/kotlin модули, так как при сборке будут объединяться манифесты, ресурсы и т.д. Когда вам всего лишь требуется для компиляции модуля что-то вроде классов Activity , Context и т.д., то можно просто добавить Android Framework как зависимость:
#11 Как написать Gradle-плагин для CI на примере gitlab
Настройка CI — отдельная большая тема, которая потянет на целую увесистую статью. Но я решил немного коснуться её и рассказать, как при помощи написания Gradle-плагина настроить версионирование сборок. Возможно, этот совет поможет тем, кто только поднимает CI, но не знает, как лучше это сделать.
Задача — сделать так, чтобы в сборках на CI versionCode ставился автоматически и представлял из себя последовательные номера 1, 2, 3 и т.д. Я встречал в своей практике, когда в качестве versionCode брался CI job id или каким-то образом использовался timestamp. В таких случаях versionCode с каждой новой версией повышался и был уникальным, но семантически такие версии выглядели достаточно странно.
Основная идея проста — нужно хранить номер будущего релиза где-то во внешнем источнике, куда имеет доступ только сборка, выполняемая на CI. А после каждой успешной публикации нужно инкрементировать этот номер и перезаписывать (нам важно, чтобы сборка не просто успешно выполнилась, но и полученные артефакты распространились для тестировщиков). Стоит оговориться, что такое решение не позволит корректно делать одновременно несколько сборок. Всю эту логику достаточно просто оформить в Gradle-плагин. Как мы уже выяснили, плагины лучше писать, используя композитные сборки.
В случае использования Gitlab CI подставляемый versionCode можно хранить в переменной окружения Gitlab. В его API есть метод для обновления переменных окружения: PUT /projects/:id/variables/:key . Для авторизации используем или project access token, или personal access token для старых версий gitlab.
Расписал добавление такого плагина по шагам, чтобы показать, насколько это просто.
Шаг 1: в настройках проекта на gitlab создать переменные окружения
Нам понадобятся переменные VERSION_CODE_NEXT для хранения номера версии и токен для доступа к API gitlab:
Шаг 2: создать композитную сборку
Добавим в корне проекта директорию ./includedBuilds/ci , а в ней файл build.gradle.kts :
Рядом создадим пустой файл ./includedBuilds/ci/settings.gradle.kts , если этого не сделать, то у вас сломается clean проекта.
В корневом проекте в файл settings.gradle.kts добавим строку includeBuild(«includedBuilds/ci») .
Шаг 3: написать плагин
Так будет выглядеть метод для получения versionCode , его можно будет использовать в build-скрипте (можно добавить в любой файл: при применении плагина код будет скомпилирован и добавлен в classpath build-скрипта):
Примерно так можно написать метод для обновления переменной на gitlab:
Далее пишем task, который при выполнении будет инкрементировать версию:
И напишем плагин, который добавит task в проект:
Шаг 4: подключить плагин
В build-скрипте проекта, из которого собирается apk, добавим следующие строки:
Теперь команда ./gradlew assembleRelease appDistributionUploadRelease incrementVersionCode будет делать новую сборку, публиковать ее и инкрементировать версию. Остается добавить эту команду на нужный триггер в ваш скрипт в .gitlab-ci.yml .
В заключение
Думаю, что у многих есть свои best practices по работе с Gradle, которыми вы бы могли поделиться с сообществом. Или что-то описанное в этой статье можно сделать лучше. Так что буду рад увидеть ваши советы в комментариях.
Что ещё посмотреть
Мне очень помогли доклады про работу с Gradle, которые делал Степан Гончаров в разные годы. Ссылки на них, если кому-то интересна эта тема:
Источник



