- Первичный ключ – GUID или автоинкремент?
- Тестирование
- Как правильно идентифицировать Android-устройства
- Зачем нужна идентификация
- Основные способы идентификации
- Использование аппаратных идентификаторов
- Генерация UUID с первым запуском
- Использование идентификаторов, предоставляемых системой
- Создание цифрового отпечатка (fingerprint) устройства
- Какой метод выбрать
- Евангелие от GUID
- Евангелие от GUID
- I. Всегда используй GUID для уникальной идентификации строки таблицы.
- 1) Мне не нужно совершать дополнительных выборок, а это — увеличение производительности!
- 2) Объединение данных настолько просто, что получается даже у Мак-разработчиков!
- 3) Типо-независимость
- 4) Удар, удар, еще удар. (с)
- Ну а есть ли недостатки у GUID?
Первичный ключ – GUID или автоинкремент?
Зачастую, когда разработчики сталкиваются с созданием модели данных, тип первичного ключа выбирается «по привычке», и чаще всего это автоинкрементное целочисленное поле. Но в реальности это не всегда является оптимальным решением, так как для некоторых ситуаций более предпочтительным может оказаться GUID. На практике возможны и другие, более редкие, типы ключа, но в данной статье мы их рассматривать не будем.
Ниже приведены преимущества каждого из вариантов.
Автоинкремент
- Занимает меньший объем
- Теоретически, более быстрая генерация нового значения
- Более быстрая десериализация
- Проще оперировать при отладке, поддержке, так как число гораздо легче запомнить
GUID
- При репликации между несколькими экземплярами базы, где добавление новых записей происходит более, чем в одну реплику, GUID гарантирует отсутствие коллизий
- Позволяет генерировать идентификатор записи на клиенте, до сохранения ее в базу
- Обобщение первого пункта — обеспечивает уникальность идентификаторов не только в пределах одной таблицы, что для некоторых решений может быть важно
- Делает практически невозможным «угадывание» ключа в случаях, когда запись можно получить, передав ее идентификатор в какой-нибудь публичный API
Фраза «теоретически, более быстрая генерация нового значения» звучит неубедительно. Подобные соображения всегда лучше подкреплять практическими примерами. Но прежде чем писать программу для тестирования, рассмотрим, какие варианты реализации первичного ключа есть с каждым из этих двух типов.
GUID можно генерировать как на клиенте, так и самой базой данных — уже два варианта. К тому же, в MS SQL есть две функции для получения уникального идентификатора — NEWID и NEWSEQUENTIALID. Давайте разберемся, в чем их отличие и может ли оно быть существенным на практике.
Привычная генерация уникальных идентификаторов в том же .NET через Guid.NewGuid() дает множество значений, не связанных друг с другом никакой закономерностью. Если ряд GUID-ов, полученных из этой функции, держать в отсортированном списке, то каждое новое добавляемое значение может «попадать» в любую его часть. Функция NEWID() в MS SQL работает аналогично — ряд ее значений весьма хаотичен. В свою очередь, NEWSEQUENTIALID() дает те же уникальные идентификаторы, только каждое новое значение этой функции больше предыдущего, при этом идентификатор остается «глобально уникальным».
Если использовать Entity Framework Code First, и объявить первичный ключ вот таким образом
в базе данных будет создана таблица с первичным кластерным ключом, который имеет значение по умолчанию NEWSEQUENTIALID(). Сделано это из соображений производительности. Опять же, в теории, вставлять новое значение в середину списка более накладно, чем добавление в конец. База данных, конечно же, не массив в памяти, и вставка новой записи в середину списка строк не приведет к физическому сдвигу всех последующих. Тем не менее, дополнительные накладные расходы будут — разделение страниц (page split). По итогу также будет сильная фрагментация индексов, которая может отразиться на производительности выборки данных. Неплохое объяснение того, как происходит вставка данных в кластеризованую таблицу, можно найти в ответах форума по этой ссылке.
Таким образом, для GUID мы имеем 4 варианта, которые стоит проанализировать в плане производительности: последовательный и непоследовательный GUID с генерацией на клиенте, и та же пара вариантов, но с генерацией на стороне базы. Остается вопрос, как получать последовательные GUID на клиенте? К сожалению, стандартной функции в .NET для этих целей нет, но ее можно сделать, воспользовавшись P/Invoke:
Обратите внимание на то, что без специальной перестановки байт, GUID нельзя отдавать. Идентификаторы получатся корректные, но с точки зрения SQL сервера — непоследовательные, поэтому никакого выигрыша по сравнению с «обычным» GUID даже теоретически не получится. К сожалению, ошибочный код приведен во многих источниках.
К списку остается добавить пятый вариант — автоинкрементный первичный ключ. Других вариантов у него нет, так как на клиенте его генерировать нормально не получится.
С вариантами определились, но есть еще один параметр, который следует учесть при написании теста — физический размер строк таблицы. Размер страницы данных в MS SQL — 8 килобайт. Записи близкого или даже большего размера могут показать более сильный разброс производительности для каждого из вариантов ключа, чем на порядок меньшие записи. Чтобы обеспечить возможность варьировать размер записи, достаточно добавить в каждую из тестовых таблиц NVARCHAR поле, которое затем заполнять нужным количеством символов (один символ в NVARCHAR поле занимает 2 байта).
Тестирование
По этой ссылке находится проект с программой, которая была разработана с учетом указанных выше соображений.
Ниже приведены результаты тестов, которые выполнялись по такой схеме:
- Всего три серии тестов с длиной текстового поля в записи 80, 800 и 8000 байт соответственно (количество символов в тестовой программе будет в два раза меньше в каждом из случаев, так как один символ в NVARCHAR занимает два байта).
- В каждой из серий — по 5 запусков, каждый из которых добавляет по 10000 записей в каждую из таблиц. По результатам каждого из запусков можно будет проследить зависимость времени вставки от количества строк, уже находящихся в таблице.
- Перед началом каждой из серий таблицы полностью очищаются.
Источник
Как правильно идентифицировать Android-устройства
Всем привет! Если вам нужно создать уникальный и стабильный идентификатор Android-устройства для использования внутри приложения, то вы наверняка заметили тот хаос, который присутствует в документации и в ответах на stackoverflow. Давайте рассмотрим, как решить эту задачу в 2020 году. О том, где взять идентификатор, стойкий к переустановкам вашего приложения, и какие могут быть сложности в будущем — в этом кратком обзоре. Поехали!
Зачем нужна идентификация
В последнее время обсуждения конфиденциальности пользовательских данных стремительно набирают популярность. Возможно, это спровоцировано ростом выручки рекламных гигантов. Возможно, под этими обсуждениями скрывается обеспокоенность монополиями, которые идентифицируют пользователей и их устройства. Так, Apple, борясь со слежкой и ограничивая всем разработчикам использование IDFA, в то же самое время нисколько не ограничивает его себе. Что можно сказать точно: процесс идентификации пользователя приложения для разработчиков усложнился.
В задачах, опирающихся на идентификацию, встречаются: аналитика возвратов, персонализация контента и рекламы, предотвращение мошенничества.
Среди последних можно выделить несколько актуальных проблем:
Общие аккаунты в сервисах с платной подпиской или уникальным платным контентом. Только представьте сколько теряют сервисы вроде Netflix или Coursera от того, что пользователи заводят один аккаунт на нескольких человек.
Обе проблемы ведут либо к потере выручки, либо к репутационным потерям. Надежность их решения напрямую зависит от надежности идентификации устройств.
Основные способы идентификации
Использование аппаратных идентификаторов
Устаревший и нежизнеспособный в настоящее время способ. Google хорошо поработала над тем, чтобы закрыть доступ к ним, поскольку они не меняются даже после сброса к заводским настройкам. Среди таких идентификаторов:
В настоящее время они недоступны без явного запроса разрешений. Более того, если приложению нужно ими пользоваться, оно может не попасть в Play Market. Оно должно основным функционалом опираться на эти разрешения, иначе будут трудности с прохождением ревью. Поэтому сейчас эта опция доступна приложениям для работы со звонками или голосовым ассистентам.
Такие идентификаторы не меняются после сброса к заводским настройкам, и здесь кроется неочевидный недостаток: люди могут продавать свои устройства, и в таком случае идентификатор будет указывать на другого человека.
Генерация UUID с первым запуском
Данный способ схож с использованием cookie: создаем файл со сгенерированной строкой, сохраняем его в песочнице нашего приложения (например с помощью SharedPreferences), и используем как идентификатор. Недостаток тот же, что и у cookie — вся песочница удаляется вместе с приложением. Еще она может быть очищена пользователем явно из настроек.
При наличии у приложения разрешений к хранилищу вне песочницы можно сохранить идентификатор где-то на устройстве и постараться поискать его после переустановки. Будет ли в тот момент нужное разрешение у приложения — неизвестно. Этот идентификатор можно использовать как идентификатор установки приложения (app instance ID).
Использование идентификаторов, предоставляемых системой
В документации для разработчиков представлен идентификатор ANDROID_ID. Он уникален для каждой комбинации устройства, пользователя, и ключа, которым подписано приложение. До Android 8.0 идентификатор был общим для всех приложений, после — уникален только в рамках ключа подписи. Этот вариант в целом годится для идентификации пользователей в своих приложениях (которые подписаны вашим сертификатом).
Существует и менее известный способ получить идентификатор общий для всех приложений, независимо от сертификата подписи. При первичной настройке устройства (или после сброса к заводским) сервисы Google генерируют идентификатор. Вы не найдете о нем никакой информации в документации, но тем не менее можете попробовать код ниже, он будет работать (по состоянию на конец 2020 года).
Добавляем строчку в файл манифеста нужного модуля:
И вот так достаем идентификатор:
В коде происходит следующее: мы делаем запрос к данным из определенного ContentProvider-a, что поставляется с сервисами Google. Вполне возможно, что Google закроет к нему доступ простым обновлением сервисов. И это даже не обновление самой операционки, а пакета внутри нее, т.е. доступ закроется с обычным обновлением приложений из Play Market.
Но это не самое плохое. Самый большой недостаток в том, что такие фреймворки, как Xposed, позволяют с помощью расширений в пару кликов подменить как ANDROID_ID, так и GSF_ID. Подменить локально сохраненный идентификатор из предыдущего способа сложнее, поскольку это предполагает как минимум базовое изучение работы приложения.
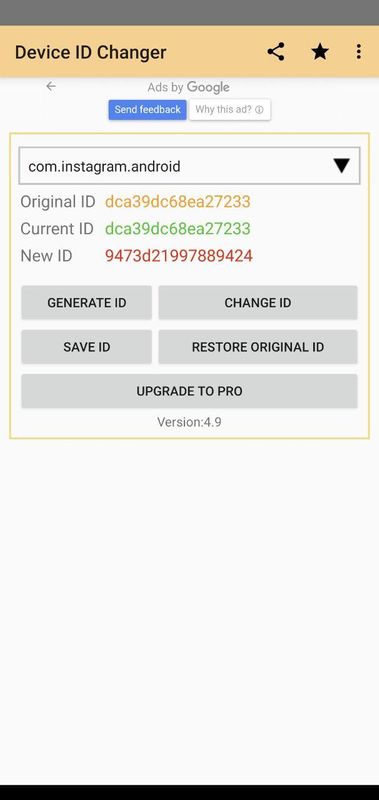 Приложение Device ID Changer в связке с Xposed позволяет подменять практически любой идентификатор. В бесплатной версии — только ANDROID_ID
Приложение Device ID Changer в связке с Xposed позволяет подменять практически любой идентификатор. В бесплатной версии — только ANDROID_ID
Создание цифрового отпечатка (fingerprint) устройства
Идея device-fingerprinting не новая, и активно используется в вебе. У самой популярной библиотеки для создания отпечатка — FingerprintJS — 13 тысяч звезд на GitHub. Она позволяет идентифицировать пользователя без использования cookie.
Рассмотрим идею на примере (цифры взяты приблизительные для иллюстрации).
Возьмем ежедневную аудиторию какого-нибудь Android-приложения. Допустим она составляет 4 миллиона. Сколько среди них устройств марки Samsung? Гораздо меньше, примерно 600 тысяч. А сколько среди устройств Samsung таких, что находятся под управлением Android 9? Уже около 150 тысяч. Выделим среди последних такие, что используют сканер отпечатков пальцев? Это множество устройств еще меньше, ведь у многих планшетов нет сканера отпечатков пальцев, а современные модели опираются на распознавание лица. Получим 25000 устройств. Добавляя больше условий и получая больше информации, можно добиться множеств малых размеров. В идеальном случае — с единственным элементом внутри, что и позволит идентифицировать пользователя. Чем больше пользователей можно различить, тем выше энтропия этой информации.
Среди основных источников информации в Android, доступных без пользовательских разрешений, можно выделить аппаратное обеспечение, прошивку, некоторые настройки устройства, установленные приложения и другие.
Обычно всю добытую информацию хешируют, получая цифровой отпечаток. Его и можно использовать в качестве идентификатора.
Из достоинств метода — его независимость от приложения (в отличие от ANDROID_ID), поскольку при одинаковых показаниях с источников отпечатки будут одинаковыми. Отсюда же вытекает первый недостаток — разные устройства с некоторой вероятностью могут иметь одинаковый отпечаток.
Еще одна особенность отпечатка — не все источники информации стабильны. Например, установленные приложения дадут много энтропии. Возьмите устройство друга, и проверьте, одинаков ли у вас набор приложений. Скорее всего — нет, к тому же приложения могут устанавливаться и удаляться почти каждый день.
Таким образом, метод будет работать при правильном соотношении стабильности и уникальности источников энтропии.
Какой метод выбрать
Итак, мы рассмотрели доступные способы идентификации. Какой же выбрать? Как и в большинстве инженерных задач, единственного правильного решения не существует. Все зависит от ваших требований к идентификатору и от требований к безопасности приложения.
Разумный вариант — использовать сторонние решения с открытыми исходниками. В этом случае за изменениями в политике конфиденциальности будет следить сообщество, вовремя поставляя нужные изменения. За столько лет существования проблемы до сих пор нет популярной библиотеки для ее решения, как это есть для веба. Но среди того, что можно найти на android-arsenal, можно выделить две, обе с открытым исходным кодом.
Android-device-identification — библиотека для получения идентификатора. Судя по коду класса, ответственного за идентификацию, используются аппаратные идентификаторы, ANDROID_ID, и цифровой отпечаток полей из класса Build. Увы, проект уже 2 года как не поддерживается, и в настоящий момент скорее неактуален. Но, возможно, у него еще будет развитие.
Fingerprint-android — совсем новая библиотека. Предоставляет 2 метода: getDeviceId и getFingerprint. Первый опирается на GSF_ID и ANDROID_ID, а второй отдает отпечаток, основанный на информации с аппаратного обеспечения, прошивки и некоторых стабильных настроек устройства. Какая точность у метода getFingerprint — пока неясно. Несмотря на это библиотека начинает набирать популярность. Она проста в интеграции, написана на Kotlin, и не несет за собой никаких зависимостей.
В случае, когда импортирование сторонних зависимостей нежелательно, подойдет вариант с использованием ANDROID_ID и GSF_ID. Но стоит следить за изменениями в обновлениях Android, чтобы быть готовым к моменту, когда доступ к ним будет ограничен.
Если у вас есть вопросы или дополнения — делитесь ими в комментариях. А на этом все, спасибо за внимание!
Источник
Евангелие от GUID
Разбираясь с новым Visual C# 2008 (он настолько бесплатный для начинающих разработчиков, что я не удержался), нашел новое для себя слово в науке и технике — GUID.
Привожу пример интересной, как мне кажется, статьи, призывающей использовать глобально-уникальные идентификаторы во всех сферах народного хозяйства. Статья, в основном про .NET и прочий микрософт, но, думаю, будет полезна многим здесь, ибо реализации GUID есть почти во всех современных БД и языках (включая mySQL и PHP ;).
ПС: Если будет интересно, то выложу перевод второй части, где автор отвечает на комменты к первой статье.
Евангелие от GUID
В Евангелие от GUID есть только одна заповедь:
I. Всегда используй GUID для уникальной идентификации строки таблицы.
При приеме новых сотрудников в команду это — одно из первых правил, которым я их обучаю. Почти всегда поначалу они смотрят на меня с видом щенка с торчащими ушами и склоненной набок головой, как бы говоря «как это?»
Поэтому я показываю им, что в каждой таблице есть поле, являющееся уникальным идентификатором, а в большинстве случаев и первичным ключом и, обычно, кластеризованным индексом. Например, в таблице Employee у нас будет поле EmployeeGUID, уникальный идентификатор и кластеризованный первичный ключ. Тут обычно я получаю в ответ взгляд «опа, мой новый босс идиот, но я не хочу, чтобы он знал, что я так думаю». Потом приходят вопросы и комментарии вида «но я обычно делаю так»:
- Я использую int
- Я не пользуюсь GUID, потому что они такие большие
- Разве вы не понимаете, как трудно искать запись по такому id, в случае с int это гораздо проще
- Ну вы же не станете их использовать в таблице, реализующей отношение многие-ко-многим?
- Что произойдет, если GUID’Ы закончатся?
- Я не уверен, что они не будут повторяться
- Я никогда ни о чем подобном не слышал, поэтому, скорее всего это плохая мысль.
- А это не ухудшит производительность?
И начинается моя миссия по обращению. У меня хорошая статистика по обращению «думающих» людей, поэтому призываю вас прочитать эту статью и, возможно, вы тоже станете верующим в GUID!
1) Мне не нужно совершать дополнительных выборок, а это — увеличение производительности!
Существует множество причин для использования GUID в качестве первичного ключа. Главная для меня напрямую связана с тем, как я строю объектные модели. Я предпочитаю создавать «new» экземпляр объекта без совершения выборки. Так, создавая объект Order (заказ) я не буду обращаться к базе данных для получения OrderID (OrderGUID в моем мире), как я бы делал в случае с int OrderID. На этом уровне еще не слишком впечатляет, да? Подумайте вот о чем: я создаю объект Order с OrderGUID, потом объекты OrderLineItem (строки заказа) с OrderLineItemGUID без ЕДИНОГО разрыва обращения к БД. В случае с int я бы сделал 11 обращений.
2) Объединение данных настолько просто, что получается даже у Мак-разработчиков!
Следующая причина всегда использовать GUID — объединение данных (merging), оказывавшееся необходимым бессчетное количество раз. До того как я увидел свет, я тоже использовал int или что-то еще, чтобы сделать строку уникальной, но когда мне приходилось сливать данные из раных источников, я делел специальные преобразования.
DB1 (Клиент 1):
Order (таблица заказов)
OrderID = 1
CustomerID = 1
DB2 (Клиент 2):
Order
OrderID = 1
CustomerID = 1
Если Клиент 1 приобретает Клиента 2 и мне нужно слить их данные в единую БД, мне придется поменять чьи-то OrderID и CustomerID на какие-нибудь int значения, которые не используюся, после чего сделать update большому количеству записей, а, возможно и поплясать с бубном и с опорными значениями (seed values). Умножьте это на десятки таблиц, учтите миллионы строк данных, и у бедитесь, что передо мной стоит ДЕЙСТВИТЕЛЬНО сложная задача, которая потребует дофига тестирования после написания SQL и/или кода.
Однако, если я следую Евангелию от GUID:
В этом случае, все, что нужно сделать сводится к обычной вставке всех строк из одной БД в другую. Никаких преобразований, никаких замороченных тестов, просто, удобно и действенно. Недавно мне пришлось проделать эту операцию с БД двух моих клиентов AT&T и Cingular. Все «преобразование» заняло 45 минут.
Другой простой пример: представьте, что ваши клиенты часто работают удаленно в оффлайне, и вам приходится закачивать их данные в общую БД при подключении. Теперь это проще, чем у ребенка конфету отнять… © Если вы верите в GUID. Вы можете легко таскать данные между базами.
3) Типо-независимость
Третья причина, по которой я верю в GUID — это то, что я называю «типо-независимость» (Type Ignorance — это игра слов, построенная на Type Inference В .NET 3.5). Суть ее в том, что мне не важно, как хранятся данные в каждой таблице БД. Представьте, что у нас есть продукт, находящийся в коммерческом использовании уже некоторое время. В БД есть таблицы Customer, Order, OrderLineItem, Product (Товар) и Vendor (Поставщик). Теперь выяснилось, что нужно добавить «заметки» к каждому виду объекта. Для этього достаточно просто создать таблицу
| Notes | |
| NoteGUID | Unique Identifier |
| ParentGUID | Unique Identifier |
| Note | VarChar(500) |
Теперь можно вставлять заметки в эту таблицу, используя GUID самих объектов в ParentGUID. Для получения всех заметок по конкретному товару совершается простейшая выборка из notes по его GUID.
Например, чтобы получить все заметки по поставщику, достаточно создать простую связь (join) Note.ParentGUID к Vendor.VendorGUId. Не нужны никакие индикаторы типов, не нужно выдумывать, какие таблицы связывать, не нужно кучи ссылочных таблиц, чтобы понять с каким типом объекта связана строка.
Вы удивитесь, узнав насколько часто используется этот небольшой прием. Недавно мы добавили «аудит» к одному из наших приложений, в котором хотели выяснить кто что удалял, добавлял или изменял в БД. Мы просто добавили несколько строчек кода к методу DataContext SubmitChanges() (мы используем только LINQ в этом приложении) для создания соответствующей записи в таблице аудита. При создании нового объекта или типа в приложении запись в эту таблицу происходит автоматически, что позволяет нам не париться написанием специального «аудиторского» кода при добавлении новых типов данных в приложении.
4) Удар, удар, еще удар. (с)
Существует много менее очевидных причин для использования GUID, но есть одна, которую я не предвидел заранее и за которую я благодарю GUID, ибо он и только он спас миллионы долларов моему клиенту… да, я сказал МИЛЛИОНЫ!
Я разрабатывал систему управления автоматическими выплатами за размещение рекламы для крупного клиента. Они должны были иметь возможность по нажатию кнопки оплачивать счета общей суммой в миллионы долларов. В двух словах, по нажатию кнопки наша система генерирует файл с очередью и отправляет его их платежному серверу, который сгенерирует чеки… и денежки уйдут. Конечно, я использовал GUID, чтобы идентифицировать все и вся, поэтому когда платежный сервер генерировал файл сверки, я легко мог прогнать его по своей базе.
На нашем сайте была развернута рабочая БД клиента и тестовая БД, слегка устаревшая копия рабочей (на пару месяцев). В процессе тестирования кто-то на их стороне увидел один из наших тестовых файлов с очередью оплат и, не долго думая, скормил их платежному серверу. Ну, дальше вы поняли… Клиент заплатил куче действительных поставщиков контента дважды (один раз по реальному запросу, второй раз — по тестовому), а также еще и не совсем нормальным поставщикам (например тем, что уже не размещали рекламу, ведь тестовая БД устарела на пару месяцев). Вот так, без каких-либо косяков с моей стороны, я получил ужасную помойку в данных… ну по крайней мере так думал мой клиент. Однако, поскольку все мои записи о выплатах имели GUID, я мог легко выделить те записи, что пришли из тестовой базы, чтобы отменить платежи по ним. Представьте, если бы я использовал INT, у меня не было бы способа узнать из какой базы пришел запрос PaymentID = 1000, например.
Ну так как же это помогло спасти миллионы? Просто… умножьте тысячи запросов на штраф за отмену платежа ($20-30). И еще на три, поскольку такая ошибка повторилась три раза!
Ну а есть ли недостатки у GUID?
Если кратко, то да, есть. Однако они, настолько незначительны, что не могут изменить моего мнения. Наиболее очевидный из них — это написание SQL запросов вручную (кгда надо что-то найти).
SELECT * FROM ORDER WHERE ORDERID = 12
гораздо легче, чем
Еще один недостаток — небольшое снижение производительности у связей, построенных на базе gUID, по сравнению с INT. Но по моему опыту даже при использовании таблиц с многомиллионным количеством строк, это никогда не становилось проблемой. Несколько миллисикунд задержки — небольшая цена за все прелести GUIDа.
Опробуйте эту технику в каком-нибудь небольшом проекте, особенно если все еще настроены скептично. Думаю, она окажется более полезной чем вы могли мечтать.
Источник



