- Создание голосового ассистента на Python, часть 1
- Пишем голосового ассистента на Python
- Введение
- Что умеет мой голосовой ассистент?
- Шаг 1. Обработка голосового ввода
- Шаг 2. Конфигурация голосового ассистента
- Шаг 3. Обработка команд
- 1 способ
- 2 способ
- Шаг 4. Добавление мультиязычности
- Шаг 5. Немного машинного обучения
- Заключение
- Как встроить голосового помощника в любое мобильное приложение. Разбираем на примере Habitica
- Что нужно для работы
- Порядок действий
Создание голосового ассистента на Python, часть 1
Добрый день. Наверное, все смотрели фильмы про железного человека и хотели себе голосового помощника, похожего на Джарвиса. В этом посте я расскажу, как сделать такого ассистента с нуля. Моя программа будет написана на python 3 в операционной системе windows. Итак, поехали!
Работать наш ассистент будет по такому принципу:
- Постоянно «слушать» микрофон
- Распознавать слова в google
- Выполнять команду, либо отвечать
1) Синтез речи
Для начала мы установим в систему windows русские голоса. Для этого переходим по ссылке и скачиваем голоса в разделе SAPI 5 -> Russian. Там есть 4 голоса, можно выбрать любой, какой вам понравится. Устанавливаем и идём дальше.
Нам нужно поставить библиотеку pyttsx3 для синтеза речи:
Затем можно запустить тестовую программу и проверить правильность её выполнения.
2) Распознавание речи
Существует много инструментов для распознавания речи, но они все платные. Поэтому я пытался найти бесплатное решение для моего проекта и нашёл её! Это библиотека speech_recognition.
Также для работы с микрофоном нам необходима библиотека PyAudio.
У некоторых людей возникает проблема с установкой PyAudio, поэтому следует перейти по этой ссылке и скачать нужную вам версию PyAudio. Затем ввести в консоль:
Затем запускаете тестовую программу. Но перед этим вы должны исправить в ней device_index=1 на своё значение индекса микрофона. Узнать индекс микрофона можно с помощью этой программы:
Тест распознавания речи:
Если всё отлично, переходим дальше.
Если вы хотите, чтобы ассистент просто общался с вами (без ИИ), то это можно сделать с помощью бесплатного инструмента DialogFlow от Google. После того, как вы залогинетесь, вы увидите экран, где уже можно создать своего первого бота. Нажмите Create agent. Придумайте боту имя (Agent name), выберете язык (Default Language) и нажмите Create. Бот создан!
Чтобы добавить новые варианты ответов на разные вопросы, нужно создать новый intent. Для этого в разделе intents нажмите Create intent. Заполните поля «Название» и Training phrases, а затем ответы. Нажмите Save. Вот и всё.
Чтобы управлять ботом на python, нужно написать такой код. В моей программе бот озвучивает все ответы.
На сегодня всё. В следующей части я расскажу как сделать умного бота, т.е. чтобы он мог не только отвечать, но и что-либо делать.
Источник
Пишем голосового ассистента на Python
Введение
Технологии в области машинного обучения за последний год развиваются с потрясающей скоростью. Всё больше компаний делятся своими наработками, тем самым открывая новые возможности для создания умных цифровых помощников.
В рамках данной статьи я хочу поделиться своим опытом реализации голосового ассистента и предложить вам несколько идей для того, чтобы сделать его ещё умнее и полезнее.

Что умеет мой голосовой ассистент?
| Описание умения | Работа в offline-режиме | Требуемые зависимости |
| Распознавать и синтезировать речь | Поддерживается | pip install PyAudio (использование микрофона) |
pip install pyttsx3 (синтез речи)
Для распознавания речи можно выбрать одну или взять обе:
- pip install SpeechRecognition (высокое качество online-распознавания, множество языков)
- pip install vosk (высокое качество offline-распознавания, меньше языков)
Шаг 1. Обработка голосового ввода
Начнём с того, что научимся обрабатывать голосовой ввод. Нам потребуется микрофон и пара установленных библиотек: PyAudio и SpeechRecognition.
Подготовим основные инструменты для распознавания речи:
Теперь создадим функцию для записи и распознавания речи. Для онлайн-распознавания нам потребуется Google, поскольку он имеет высокое качество распознавания на большом количестве языков.
А что делать, если нет доступа в Интернет? Можно воспользоваться решениями для offline-распознавания. Мне лично безумно понравился проект Vosk.
На самом деле, необязательно внедрять offline-вариант, если он вам не нужен. Мне просто хотелось показать оба способа в рамках статьи, а вы уже выбирайте, исходя из своих требований к системе (например, по количеству доступных языков распознавания бесспорно лидирует Google).
Теперь, внедрив offline-решение и добавив в проект нужные языковые модели, при отсутствии доступа к сети у нас автоматически будет выполняться переключение на offline-распознавание.
Замечу, что для того, чтобы не нужно было два раза повторять одну и ту же фразу, я решила записывать аудио с микрофона во временный wav-файл, который будет удаляться после каждого распознавания.
Таким образом, полученный код выглядит следующим образом:
Возможно, вы спросите «А зачем поддерживать offline-возможности?»
Я считаю, что всегда стоит учитывать, что пользователь может быть отрезан от сети. В таком случае, голосовой ассистент всё еще может быть полезным, если использовать его как разговорного бота или для решения ряда простых задач, например, посчитать что-то, порекомендовать фильм, помочь сделать выбор кухни, сыграть в игру и т.д.
Шаг 2. Конфигурация голосового ассистента
Поскольку наш голосовой ассистент может иметь пол, язык речи, ну и по классике, имя, то давайте выделим под эти данные отдельный класс, с которым будем работать в дальнейшем.
Для того, чтобы задать нашему ассистенту голос, мы воспользуемся библиотекой для offline-синтеза речи pyttsx3. Она автоматически найдет голоса, доступные для синтеза на нашем компьютере в зависимости от настроек операционной системы (поэтому, возможно, что у вас могут быть доступны другие голоса и вам нужны будут другие индексы).
Также добавим в в main-функцию инициализацию синтеза речи и отдельную функцию для её проигрывания. Чтобы убедиться, что всё работает, сделаем небольшую проверку на то, что пользователь с нами поздоровался, и выдадим ему обратное приветствие от ассистента:
На самом деле, здесь бы хотелось самостоятельно научиться писать синтезатор речи, однако моих знаний здесь не будет достаточно. Если вы можете подсказать хорошую литературу, курс или интересное документированное решение, которое поможет разобраться в этой теме глубоко — пожалуйста, напишите в комментариях.
Шаг 3. Обработка команд
Теперь, когда мы «научились» распознавать и синтезировать речь с помощью просто божественных разработок наших коллег, можно начать изобретать свой велосипед для обработки речевых команд пользователя 😀
В моём случае я использую мультиязычные варианты хранения команд, поскольку у меня в демонстрационном проекте не так много событий, и меня устраивает точность определения той или иной команды. Однако, для больших проектов я рекомендую разделить конфигурации по языкам.
Для хранения команд я могу предложить два способа.
1 способ
Можно использовать прекрасный JSON-подобный объект, в котором хранить намерения, сценарии развития, ответы при неудавшихся попытках (такие часто используются для чат-ботов). Выглядит это примерно вот так:
Такой вариант подойдёт тем, кто хочет натренировать ассистента на то, чтобы он отвечал на сложные фразы. Более того, здесь можно применить NLU-подход и создать возможность предугадывать намерение пользователя, сверяя их с теми, что уже есть в конфигурации.
Подробно этот способ мы его рассмотрим на 5 шаге данной статьи. А пока обращу ваше внимание на более простой вариант
2 способ
Можно взять упрощенный словарь, у которого в качестве ключей будет hashable-тип tuple (поскольку словари используют хэши для быстрого хранения и извлечения элементов), а в виде значений будут названия функций, которые будут выполняться. Для коротких команд подойдёт вот такой вариант:
Для его обработки нам потребуется дополнить код следующим образом:
В функции будут передаваться дополнительные аргументы, сказанные после командного слова. То есть, если сказать фразу «видео милые котики«, команда «видео» вызовет функцию search_for_video_on_youtube() с аргументом «милые котики» и выдаст вот такой результат:

Пример такой функции с обработкой входящих аргументов:
Ну вот и всё! Основной функционал бота готов. Далее вы можете до бесконечности улучшать его различными способами. Моя реализация с подробными комментариями доступна на моём GitHub.
Ниже мы рассмотрим ряд улучшений, чтобы сделать нашего ассистента ещё умнее.
Шаг 4. Добавление мультиязычности
Чтобы научить нашего ассистента работать с несколькими языковыми моделями, будет удобнее всего организовать небольшой JSON-файл с простой структурой:
В моём случае я использую переключение между русским и английским языком, поскольку мне для этого доступны модели для распознавания речи и голоса для синтеза речи. Язык будет выбран в зависимости от языка речи самого голосового ассистента.
Для того, чтобы получать перевод мы можем создать отдельный класс с методом, который будет возвращать нам строку с переводом:
В main-функции до цикла объявим наш переводчик таким образом: translator = Translation()
Теперь при проигрывании речи ассистента мы сможем получить перевод следующим образом:
Как видно из примера выше, это работает даже для тех строк, которые требуют вставки дополнительных аргументов. Таким образом можно переводить «стандартные» наборы фраз для ваших ассистентов.
Шаг 5. Немного машинного обучения
А теперь вернёмся к характерному для большинства чат-ботов варианту с JSON-объектом для хранения команд из нескольких слов, о котором я упоминала в пункте 3. Он подойдёт для тех, кто не хочет использовать строгие команды и планирует расширить понимание намерений пользователя, используя NLU-методы.
Грубо говоря, в таком случае фразы «добрый день«, «добрый вечер» и «доброе утро» будут считаться равнозначными. Ассистент будет понимать, что во всех трёх случаях намерением пользователя было поприветствовать своего голосового помощника.
С помощью данного способа вы также сможете создать разговорного бота для чатов либо разговорный режим для вашего голосового ассистента (на случаи, когда вам нужен будет собеседник).
Для реализации такой возможности нам нужно будет добавить пару функций:
А также немного модифицировать main-функцию, добавив инициализацию переменных для подготовки модели и изменив цикл на версию, соответствующую новой конфигурации:
Однако, такой способ сложнее контролировать: он требует постоянной проверки того, что та или иная фраза всё ещё верно определяется системой как часть того или иного намерения. Поэтому данным способом стоит пользоваться с аккуратностью (либо экспериментировать с самой моделью).
Заключение
На этом мой небольшой туториал подошёл к концу.
Мне будет приятно, если вы поделитесь со мной в комментариях известными вам open-source решениями, которые можно внедрить в данный проект, а также вашими идеями касательно того, какие ещё online и offline-функции можно реализовать.
Документированные исходники моего голосового ассистента в двух вариантах можно найти здесь.
P.S: решение работает на Windows, Linux и MacOS с незначительными различиями при установке библиотек PyAudio и Google.
Кстати, тех, кто планирует строить карьеру в IT, я буду рада видеть на своём YouTube-канале IT DIVA. Там вы сможете найти видео по тому, как оформлять GitHub, проходить собеседования, получать повышение, справляться с профессиональным выгоранием, управлять разработкой и т.д.
Источник
Как встроить голосового помощника в любое мобильное приложение. Разбираем на примере Habitica
Вам не кажется, что многие мобильные приложения стали бы куда удобнее, будь в них голосовое управление? Нет, речь не о том, чтобы вести беседы с банковским ассистентом в чате техподдержки. В основном было бы достаточно голосовой навигации по приложению или form-filling в режиме диалога.
На примере Habitica (опенсорсный app для закрепления привычек и достижения целей, написан на Kotlin) Виталя Горбачёв, архитектор решений в Just AI, показывает, как быстро и бесшовно встроить голосовой интерфейс в функционал любого приложения.
Но для начала давайте обсудим, почему голосовое управление мобильным приложением — это удобно? Начнем с очевидных вещей.
- Нам часто нужно воспользоваться приложением в момент, когда заняты руки: готовка, управление транспортным средством, тащим чемоданы, во время механической работы и так далее.
- Голос — важнейший инструмент для людей с нарушениями зрения.
Кейсы и так прозрачные, но на самом деле всё еще проще: в некоторых случаях набор голосом просто быстрее! Представьте — заказ авиабилета одной фразой «Купи мне билет на завтра на двоих в Самару» вместо долгого заполнения формы. При этом с возможностью задавать пользователю уточняющие вопросы: вечером или днем? с багажом или без?
Голос полезен при прохождении нами сценария «form-filling» и удобен для заполнения почти любых длинных форм, требующих от пользователя определенного объема информации. И такие формы присутствуют в большинстве мобильных приложений.
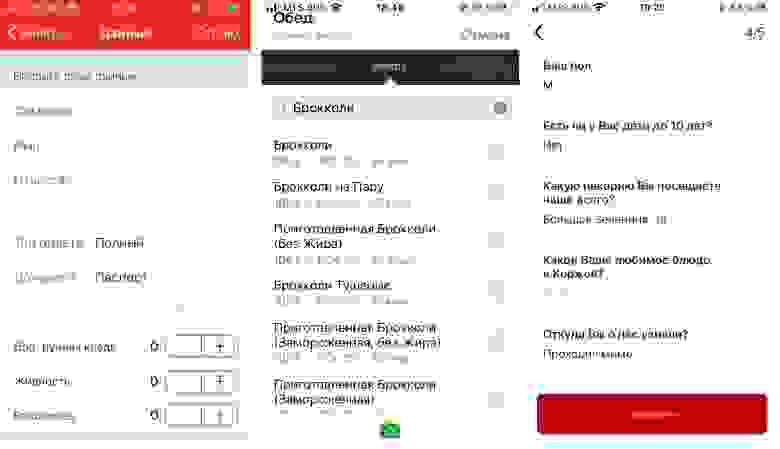
Слева направо: приложение РЖД «Пригород», дневник питания FatSecret (пользователям приходится заполнять форму несколько раз в день, выбирая из сотен продуктов), приложение пекарни «Коржов».
Из-за того, что сегодня голосовых ассистентов часто внедряют в чат поддержки и развиваются они именно оттуда, большинство компаний пытается запихнуть функционал приложения в чат. Пополнить баланс, узнать что-то о товаре или услуге… Это далеко не всегда удобно реализовано, а в случае с голосовым вводом и вовсе контрпродуктивно, хотя бы потому, что рапознавание речи часто работает совсем не идеально.
Правильный подход — встраивать ассистента бесшовно в уже существующий функционал приложения, в интерфейсе которого будет происходить заполнение формы, чтобы человек мог просто проверить, что он все правильно сказал, и нажать ОК.
Мы решили показать, как это можно сделать, на примере Habitica — это опенсорсное приложение, написаное почти на чистом Котлине. «Хабитика» отлично подходит под кейс с голосовым ассистентом — тут тоже для того, чтобы завести новую задачу, требуется заполнить довольно объемную форму. Попробуем заменить этот муторный процесс одной фразой с наводящими вопросами?
Я разбил туториал на две части. В этой статье мы разберемся, как добавить голосового ассистента в мобильное приложение и реализовать базовый сценарий (в нашем случае это готовый сценарий по уточнению прогноза погоды и времени — один из самых популярных в мире запросов к голосовым ассистентам). Во второй статье — а она выйдет уже скоро — мы научимся вызывать голосом определенные экраны и реализовывать сложные запросы внутри приложения.
Что нужно для работы
SDK. Мы взяли Aimybox как SDK для построения диалоговых интерфейсов. Из коробки Aimybox дает SDK ассистента и лаконичный и кастомизируемый UI (который при желании можно и вовсе переделать). При этом в качестве движков распознавания, синтеза и NLP можно выбрать из уже имеющихся или создать свой модуль.
По сути, Aimybox реализует архитектуру голосового помощника, стандартизируя интерфейсы всех этих модулей и правильным образом организуя их взаимодействие. Таким образом, внедряя это решение, можно значительно сократить время на разработку голосового интерфейса внутри своего приложения. Подробнее про Aimybox можно прочитать тут или тут.
Инструмент для создания сценария. Сценарий будем писать на JAICF (это опенсорсный и совершенно бесплатный фреймворк для разработки голосовых приложений от Just AI), а интенты распознавать с помощью Caila (NLU-сервис) в JAICP (Just AI Conversational Platform). Про них подробнее расскажу в следующей части туториала — когда дойдем до их использования.
Смартфон. Для тестов нам понадобится смартфон на Android, на котором мы будем запускать и тестить «Хабитику».
Порядок действий
Для начала форкаем «Хабитику» (ветку Release) и ищем самые важные для нас файлы. Я пользовался IDE Android Studio:
Находим MainActivity.kt — туда мы будем встраивать логику.
HabiticaBaseApplication.kt — там будем инициализировать Aimybox.
Activity_main.xml — туда встроим элемент интерфейса.
AndroidManifest.xml — там хранится вся структура приложения и его разрешения.
Согласно инструкции в репе «Хабитики» переименовываем habitica.properties.example и habitica.resources.example, убирая из них example, заводим проект в firebase под приложение и копируем в корень файл google-services.json.
Запускаем приложение, чтобы проверить, что сборка рабочая. Вуаля!
Для начала добавим зависимости Aimybox.
в dependencies и
И добавим сразу после compileOptions следующую строку, чтобы все работало корректно
Убираем флаги с разрешений RECORD_AUDIO и MODIFY_AUDIO_SETTINGS в AndroidManifest.xml, чтобы опции выглядели следующим образом.
Теперь инициализурем Aimybox в BaseApplication.
Добавляем AimyboxProvider при инициализации класса.

И делаем собственно инициализацию.
Вместо YOUR_KEY впоследствии будет ваш код от Aimybox Console.
Теперь встраиваем фрагмент в mainActivity.kt. Предварительно вставляем ФреймЛэйаут в activity_main.xml, прямо под фреймлэйаутом с id bottom_navigation
В сам MainActivity сначала добавляем эксплицитный запрос разрешений в OnCreate
И при их получении добавляем фрагмент в указанный выше фрейм.
Не забываем добавить в OnBackPressed возможности выйти из ассистента после захода в него.
Кроме этого, добавим в стили (styles.xml) в AppTheme
И отдельные стили чуть ниже:
Давайте проверим, добавился ли микрофончик. Запускаем приложение.
У нас посыпалась куча ошибок о неправильном синтаксисе. Исправляем все, как советует IDE.
Но микрофончик наползает на нижнюю навигацию. Давайте чуть поднимем. Добавим в стили выше в CustomAssistantButtonTheme:
Теперь подключим туда асисстента и проверим, нормально ли он отвечает. Для этого нам понадобится консоль Aimybox.
Начнем с того, что зайдем в app.aimybox.com под нашим акком гитхаба, сделаем новый проект, подключим пару навыков (я подключил DateTime для теста) и попробуем задать соответсвующие вопросы в асисстенте. Здесь же в настройках, в правом верхнем углу, берем apiKey, который вставляем в createAimybox вместо YOUR KEY.

Только надпись на английском, давайте поменяем приветственное сообщение в strings.constants.xml.

Вот ссылка на репозиторий с кодом.
В следующей статье про ассистента для «Хабитики» расскажу, как с помощью голоса не только узнавать погоду, а управлять непосредственно приложением — переходить по страничкам и добавлять привычки и задания.
Источник



