- Корутины Kotlin: как работать асинхронно в Android
- Сравним корутины с потоком
- Корутины легкие и супербыстрые
- Как же корутина приостанавливает свою работу?
- Корутины Kotlin: как работать асинхронно в Android
- Сравним корутины с потоком
- Корутины легкие и супербыстрые
- Как же корутина приостанавливает свою работу?
- Работа с сетью в Android с использованием корутин и Retrofit
Корутины Kotlin: как работать асинхронно в Android

Kotlin предоставляет корутины, которые помогают писать асинхронный код синхронно. Android — это однопоточная платформа, и по умолчанию все работает на основном потоке (потоке UI). Когда настает время запускать операции, несвязанные с UI (например, сетевой вызов, работа с БД, I/O операции или прием задачи в любой момент), мы распределяем задачи по различным потокам и, если нужно, передаем результат обратно в поток UI.
Android имеет свои механизмы для выполнения задач в другом потоке, такие как AsyncTask, Handler, Services и т.д. Эти механизмы включают обратные вызовы, методы post и другие приемы для передачи результата между потоками, но было бы лучше, если бы можно было писать асинхронный код так же, как синхронный.

С корутиной код выглядит легче. Нам не нужно использовать обратный вызов, и следующая строка будет выполнена, как только придет ответ. Можно подумать, что вызов функции из основного потока заблокирует её к тому времени, как ответ вернется, но с корутиной все иначе. Она не будет блокировать поток Main или любой другой, но все еще может выполнять код синхронно. Подробнее.
Сравним корутины с потоком
В примере выше допустим, что мы создаем новый поток, и после завершения задачи передаем результат в поток UI. Для того, чтобы сделать это правильно, нужно понять и решить несколько проблем. Вот список некоторых:
1. Передача данных из одного потока в другой — это головная боль. Так еще и грязная. Нам постоянно нужно использовать обратные вызовы или какой-нибудь механизм уведомления.
2. Потоки стоят дорого. Их создание и остановка обходится дорого, включает в себя создание собственного стека. Потоки управляются ОС. Планировщик потоков добавляет дополнительную нагрузку.
3. Потоки блокируются. Если вы выполняете такую простую задачу, как задержка выполнения на секунду (Sleep), поток будет заблокирован и не может быть использован для другой операции.
4. Потоки не знают о жизненном цикле. Они не знают о компонентах Lifecycle (Activity, Fragment, ViewModel). Поток будет работать, даже если компонент UI будет уничтожен, что требует от нас разобраться с очисткой и утечкой памяти.
Как будет выглядеть ваш код с большим количеством потоков, Async и т.д.? Мы можем столкнуться с большим количеством обратных вызовов, методов обработки жизненного цикла, передач данных из одного места в другое, что затруднит их чтение. В целом, мы потратили бы больше времени на устранение проблем, а не на логику программы.
Отметим, что это не просто другой способ асинхронного программирования , это другая парадигма.

Корутины легкие и супербыстрые
Пусть код скажет за себя.
Я создам 10к потоков, что вообще нереалистично, но для понимания эффекта корутин пример очень наглядный:
Здесь каждый поток ожидает 1 мс. Запуск этой функции занял около 12,6 секунд. Теперь давайте создадим 100к корутин (в 10 раз больше) и увеличим задержку до 10 секунд (в 10000 раз больше). Не волнуйтесь про “runBlocking” или “launch” (конструкторах Coroutine).
14 секунд. Сама задержка составляет 10 секунд. Это очень быстро. Создание 100 тысяч потоков может занять целую вечность.
Если вы посмотрите на метод creating_10k_Thread(), то увидите, что существует задержка в 1 мс. Во время нее он заблокирован, т.е. ничего не может делать. Вы можете создать только определенное количество потоков в зависимости от количества ядер. Допустим, возможно создать до 8 потоков в системе. В примере мы запускаем цикл на 10000 раз. Первые 8 раз будут созданы 8 потоков, который будут работать параллельно. На 9-й итерации следующий поток не сможет быть создан, пока не будет доступного. На 1 мс поток блокируется. Затем создастся новый поток и по итогу блокировка на 1мс создает задержку. Общее время блокировки для метода составит 10000/ мс. А также будет использоваться планировщик потоков, что добавит дополнительной нагрузки.
Для creatingCoroutines() мы установили задержку в 10 сек. Корутина приостанавливается, не блокируется. Пока метод ждет 10 секунд до завершения, он может взять задачу и выполнить ее после задержки. Корутины управляются пользователем, а не ОС, что делает их быстрее. В цифрах, каждый поток имеет свой собственный стек, обычно размером 1 Мбайт. 64 Кбайт — это наименьший объем пространства стека, разрешенный для каждого потока в JVM, в то время как простая корутина в Kotlin занимает всего несколько десятков байт heap памяти.
Еще пример для лучшего понимания:
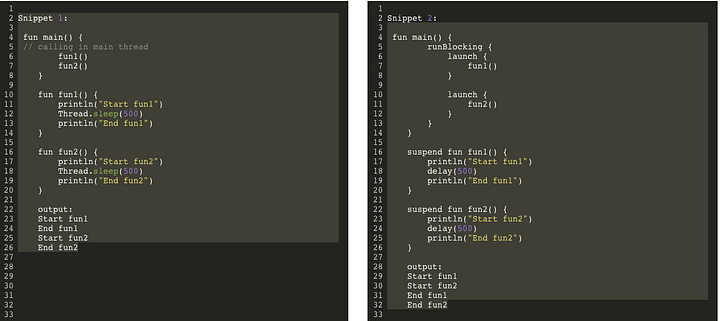
Во фрагменте 1 мы последовательно вызываем методы fun1 и fun2 в основном потоке. На 1 секунду поток будет заблокирован. Теперь рассмотрим пример с корутиной.
Во фрагменте 2 это выглядит так, как будто они работают параллельно, но это невозможно, так как оба метода выполняются одним потоком. Эти методы выполняются одновременно потому, что функция задержки не блокирует поток, она приостанавливает его. И теперь, не теряя времени, этот же поток начинает выполнять следующую задачу и возвращается к ней, как только другая приостановленная функция (задержки) вернется к нему.
Корутина может обеспечить высокий уровень параллелизма с небольшими нагрузками. Несколько потоков также могут обеспечить параллелизм, но у них есть блокировка и переключение контекста. Корутина не блокирует, а приостанавливает поток для других задач. Большое количество корутин, выполняющих маленькие задачи, эффективнее, чем планировщик, поэтому тысячи корутин работают быстрее, чем десятки потоков.
Как же корутина приостанавливает свою работу?
Если вы посмотрите на выход, то увидите, что ‘completionHandler’ выполняется после завершения ‘asyncOperation’. ‘asyncOperation’ выполняется в фоновом потоке, а ‘completionHandler’ ожидает его завершения. В ‘completionHandler’ происходит обновление textview. Давайте рассмотрим байтовый код метода ‘asyncOperation’.
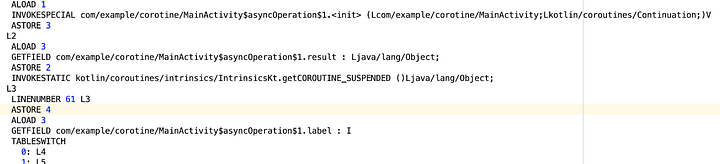
Во второй строке есть новый параметр под названием ‘continuation’, добавленный к методу asyncOperation. Continuation (продолжение) — это рабочий вариант для приостановки кода. Продолжение добавляется в качестве параметра к функции, если она имеет модификатор ‘suspend’. Также он сохраняет текущее состояние программы. Думайте о нем как о передаче остальной части кода (в данном случае метода completionHandler()) внутрь оболочки Continuation. После завершения текущей задачи выполнится блок продолжения. Поэтому каждый раз, когда вы создаете функцию suspend, вы добавляете в нее параметр продолжения, который обертывает остальную часть кода из той же корутины.
Источник
Корутины Kotlin: как работать асинхронно в Android
May 6, 2020 · 6 min read

Kotlin предоставляет корутины, которые помогают писать асинхронный код синхронно. Android — это однопоточная платформа, и по умолчанию все работает на основном потоке (потоке UI). Когда настает время запускать операции, несвязанные с UI (например, сетевой вызов, работа с БД, I/O операции или прием задачи в любой момент), мы распределяем задачи по различным потокам и, если нужно, передаем результат обратно в поток UI.
Android имеет свои механизмы для выполн е ния задач в другом потоке, такие как AsyncTask, Handler, Services и т.д. Эти механизмы включают обратные вызовы, методы post и другие приемы для передачи результата между потоками, но было бы лучше, если бы можно было писать асинхронный код так же, как синхронный.

С корутиной код выглядит легче. Нам не нужно использовать обратный вызов, и следующая строка будет выполнена, как только придет ответ. Можно подумать, что вызов функции из основного потока заблокирует её к тому времени, как ответ вернется, но с корутиной все иначе. Она не будет блокировать поток Main или любой другой, но все еще может выполнять код синхронно. Подробнее.
Сравним корутины с потоком
В примере выше допустим, что мы создаем новый поток, и после завершения задачи передаем результат в поток UI. Для того, чтобы сделать это правильно, нужно понять и решить несколько проблем. Вот список некоторых:
1. Передача данных из одного потока в другой — это головная боль. Так еще и грязная. Нам постоянно нужно использовать обратные вызовы или какой-нибудь механизм уведомления.
2. Потоки стоят дорого. Их создание и остановка обходится дорого, включает в себя создание собственного стека. Потоки управляются ОС. Планировщик потоков добавляет дополнительную нагрузку.
3. Потоки блокируются. Если вы выполняете такую простую задачу, как задержка выполнения на секунду (Sleep), поток будет заблокирован и не может быть использован для другой операции.
4. Потоки не знают о жизненном цикле. Они не знают о компонентах Lifecycle (Activity, Fragment, ViewModel). Поток будет работать, даже если компонент UI будет уничтожен, что требует от нас разобраться с очисткой и утечкой памяти.
Как будет выглядеть ваш код с большим количеством потоков, Async и т.д.? Мы можем столкнуться с большим количеством обратных вызовов, методов обработки жизненного цикла, передач данных из одного места в другое, что затруднит их чтение. В целом, мы потратили бы больше времени на устранение проблем, а не на логику программы.
Отметим , что это не просто другой способ асинхронного программирования , это другая парадигма.

Корутины легкие и супербыстрые
Пусть код скажет за себя.
Я создам 10к потоков, что вообще нереалистично, но для понимания эффекта корутин пример очень наглядный:
Здесь каждый поток ожидает 1 мс. Запуск этой функции занял около 12,6 секунд. Теперь давайте создадим 100к корутин (в 10 раз больше) и увеличим задержку до 10 секунд (в 10000 раз больше). Не волнуйтесь про “runBlocking” или “launch” (конструкторах Coroutine).
14 секунд. Сама задержка составляет 10 секунд. Это очень быстро. Создание 100 тысяч потоков может занять целую вечность.
Если вы посмотрите на метод creating_10k_Thread(), то увидите, что существует задержка в 1 мс. Во время нее он заблокирован, т.е. ничего не может делать. Вы можете создать только определенное количество потоков в зависимости от количества ядер. Допустим, возможно создать до 8 потоков в системе. В примере мы запускаем цикл на 10000 раз. Первые 8 раз будут созданы 8 потоков, который будут работать параллельно. На 9-й итерации следующий поток не сможет быть создан, пока не будет доступного. На 1 мс поток блокируется. Затем создастся новый поток и по итогу блокировка на 1мс создает задержку. Общее время блокировки для метода составит 10000/ мс. А также будет использоваться планировщик потоков, что добавит дополнительной нагрузки.
Для creatingCoroutines() мы установили задержку в 10 сек. Корутина приостанавливается, не блокируется. Пока метод ждет 10 секунд до завершения, он может взять задачу и выполнить ее после задержки. Корутины управляются пользователем, а не ОС, что делает их быстрее. В цифрах, каждый поток имеет свой собственный стек, обычно размером 1 Мбайт. 64 Кбайт — это наименьший объем пространства стека, разрешенный для каждого потока в JVM, в то время как простая корутина в Kotlin занимает всего несколько десятков байт heap памяти.
Еще пример для лучшего понимания:

Во фрагменте 1 мы последовательно вызываем методы fun1 и fun2 в основном потоке. На 1 секунду поток будет заблокирован. Теперь рассмотрим пример с корутиной.
Во фрагменте 2 это выглядит так, как будто они работают параллельно, но это невозможно, так как оба метода выполняются одним потоком. Эти методы выполняются одновременно потому, что функция задержки не блокирует поток, она приостанавливает его. И теперь, не теряя времени, этот же поток начинает выполнять следующую задачу и возвращается к ней, как только другая приостановленная функция (задержки) вернется к нему.
Корутина может обеспечить высокий уровень параллелизма с небольшими нагрузками. Несколько потоков также могут обеспечить параллелизм, но у них есть блокировка и переключение контекста. Корутина не блокирует, а приостанавливает поток для других задач. Большое количество корутин, выполняющих маленькие задачи, эффективнее, чем планировщик, поэтому тысячи корутин работают быстрее, чем десятки потоков.
Как же корутина приостанавливает свою работу?
Если вы посмотрите на выход, то увидите, что ‘completionHandler’ выполняется после завершения ‘asyncOperation’. ‘asyncOperation’ выполняется в фоновом потоке, а ‘completionHandler’ ожидает его завершения. В ‘completionHandler’ происходит обновление textview. Давайте рассмотрим байтовый код метода ‘asyncOperation’.

Во второй строке есть новый параметр под названием ‘continuation’, добавленный к методу asyncOperation. Continuation (продолжение) — это рабочий вариант для приостановки кода. Продолжение добавляется в качестве параметра к функции, если она имеет модификатор ‘suspend’. Также он сохраняет текущее состояние программы. Думайте о нем как о передаче остальной части кода (в данном случае метода completionHandler()) внутрь оболочки Continuation. После завершения текущей задачи выполнится блок продолжения. Поэтому каждый раз, когда вы создаете функцию suspend, вы добавляете в нее параметр продолжения, который обертывает остальную часть кода из той же корутины.
Coroutine очень хорошо работает с Livedata, Room, Retrofit и т.д. Еще один пример с корутиной:
Источник
Работа с сетью в Android с использованием корутин и Retrofit
Чем больше я читал и смотрел доклады про корутины в Kotlin, тем больше я восхищался этим средством языка. Недавно в Kotlin 1.3 вышел их стабильный релиз, а значит, настало время начать погружение и опробовать корутины в действии на примере моего существующего RxJava-кода. В этом посте мы сфокусируемся на том, как взять существующие запросы к сети и преобразовать их, заменив RxJava на корутины.

Откровенно говоря, перед тем как я попробовал корутины, я думал, что они сильно отличаются от того, что было раньше. Однако, основной принцип корутин включает те же понятия, к которым мы привыкли в реактивных потоках RxJava. Для примера давайте возьмем простую конфигурацию RxJava для создания запроса к сети из одного моего приложения:
- Определяем сетевой интерфейс для Ретрофита, используя Rx-адаптер (retrofit2:adapter-rxjava2). Функции будут возвращать объекты из Rx-фреймворка, такие как Single или Observable. (Здесь и далее используются функции, а не методы, так как предполагается, что старый код был также написан на Kotlin. Ну или сконвертирован из Java через Android Studio).
- Вызываем определенную функцию из другого класса (например репозитория, или активити).
- Определяем для потоков, на каком Scheduler-е они будут выполняться и возвращать результат (методы .subscribeOn() и .observeOn()).
- Сохраняем ссылку на объект для отписки (например в CompositeObservable).
- Подписываемся на поток эвентов.
- Отписываемся от потока в зависимости от событий жизненного цикла Activity.
Это основной алгоритм работы с Rx (не учитывая функции маппинга и детали других манипуляций с данными). Что касается корутин – принцип сильно не меняется. Та же концепция, меняется только терминология.
- Определяем сетевой интерфейс для Ретрофита, используя адаптер для корутин. Функции будут возвращать Deferred объекты из API корутин.
- Вызываем эти функции из другого класса (например репозитория, или активити). Единственное отличие: каждая функция должна быть помечен как отложенная (suspend).
- Определяем dispatcher, который будет использован для корутина.
- Сохраняем ссылку на Job-объект для отписки.
- Запускаем корутин любым доступным способом.
- Отменяем корутины в зависимости от событий жизненного цикла Activity.
Как можно заметить из приведенных выше последовательностей, процесс выполнения Rx и корутин очень похож. Если не учитывать детали реализации, это означает, что мы можем сохранить подход, который у нас есть – мы только заменяем некоторые вещи, чтобы сделать нашу реализацию coroutine-friendly.
Первый шаг, который мы должны сделать – позволить Ретрофиту возвращать Deferred-объекты. Объекты типа Deferred представляют собой неблокирующие future, которые могут быть отменены, если нужно. Эти объекты по сути представляют собой корутинную Job, которая содержит значение для соответствующей работы. Использование Deferred типа позволяет нам смешать ту же идею, что и Job, с добавлением возможности получить дополнительные состояния, такие как success или failure – что делает его идеальным для запросов к сети.
Если вы используете Ретрофит с RxJava, вероятно, вы используете RxJava Call Adapter Factory. К счастью, Джейк Вортон написал её эквивалент для корутин.
Мы можем использовать этот call adapter в билдере Ретрофита, и затем имплементировать наш Ретрофит-интерфейс так же, как было с RxJava:
Теперь посмотрим на интерфейс MyService, который использован выше. Мы должны заменить в Ретрофит-интерфейсе возвращаемые Observable-типы на Deferred. Если раньше было так:
То теперь заменяем на:
Каждый раз, когда мы вызовем getData() – нам вернется объект Deferred – аналог Job для запросов к сети. Раньше мы как-то так вызывали эту функцию с RxJava:
В этом RxJava потоке мы вызываем нашу служебную функцию, затем применяем map-операцию из RxJava API с последующим маппингом данных, вернувшихся из запроса, в что-то, используемое в UI слое. Это немного поменяется, когда мы используем реализацию с корутинами. Для начала, наша функция должна быть suspend (отложенной), для того, чтобы сделать ленивую операцию внутри тела функции. И для этого вызывающая функция должна быть также отложенной. Отложенная функция – неблокирующая, и ею можно управлять после того, как она будет первоначально вызвана. Можно ее стартануть, поставить на паузу, возобновить или отменить.
Теперь мы должны вызвать нашу служебную функцию. На первый взгляд, мы выполняем то же самое, но нужно помнить, что теперь мы получаем Deferred вместо Observable.
Из-за этого изменения мы не можем больше использовать цепочку map-операция из RxJava API. И даже в этой точке нам не доступны данные – мы только имеем Deferred-инстанс. Теперь мы должны использовать функцию await() для того, чтобы дождаться результата выполнения запроса и затем продолжить выполнение кода внутри функции:
В этой точке мы получаем завершенный запрос и данные из него, доступные для использования. Поэтому мы можем теперь совершать операции маппинга:
Мы взяли наш Ретрофит-интерфейс вместе с вызывающим классом и использовали корутины. Теперь же мы хотим вызвать этот код из наших Activity или фрагментов и использовать данные, которые мы достали из сети.
В нашей Activity начнем с создания ссылки на Job, в которую мы сможем присвоить нашу корутинную операцию и затем использовать для управления, например отмены запроса, во время вызова onDestroy().
Теперь мы можем присвоить что-то в переменную myJob. Давайте посмотрим на наш запрос с корутинами:
В этом посте я не хотел бы углубляться в Dispatchers или исполнение операций внутри корутинов, так как это тема для других постов. Вкратце, что здесь происходит:
- Создаем инстанс CoroutineScope, используя IO Dispatcher в качестве параметра. Этот диспатчер используется для совершения блокирующих операций ввода-вывода, таких как сетевые запросы.
- Запускаем наш корутин функцией launch – эта функция запускает новый корутин и возвращает ссылку в переменную типа Job.
- Затем мы используем ссылку на наш репозиторий для получения данных, выполняя сетевой запрос.
- В конце мы используем Main диспатчер для совершения работы на UI-потоке. Тут мы сможем показать полученные данные пользователям.
В следующем посте автор обещает копнуть поглубже в детали, но текущего материала должно быть достаточно для начала изучения корутинов.
В этом посте мы заменили RxJava-реализацию ответов Ретрофита на Deferred объекты из API корутин. Мы вызываем эти функции для получения данных из сети, и затем отображем их в нашем активити. Надеюсь, вы увидели, как мало изменений нужно сделать, чтобы начать работать с корутинами, и оценили простоту API, особенно в процессе чтения и написания кода.
В комментариях к оригинальному посту я нашел традиционную просьбу: покажите код целиком. Поэтому я сделал простое приложение, которое при старте получает расписание электричек с API Яндекс.Расписаний и отображает в RecyclerView. Ссылка: https://github.com/AndreySBer/RetrofitCoroutinesExample
Еще хотелось бы добавить, что корутины кажутся неполноценной заменой RxJava, так как не предлагают равноценного набора операций для синхронизации потоков. В этой связи стоит посмотреть на реализацию ReactiveX для Kotlin: RxKotlin.
Источник



