- Эффективное использование GPU
- Настроить параметры GPU визуализации
- Отладить показатель GPU overdraw
- Что такое GPU-ускорение на платформе Android
- Что такое GPU-ускорение на Android
- Включение и отключение
- Оптимизация рендера под Mobile, часть 2. Основные семейства современных мобильных GPU
- Унифицированные или специализированные шейдерные ядра
- Векторный (SIMD) или скалярный набор инструкций
- Mali Utgard
- Mali Midgard
- Mali Bifrost
- Из неофициального
- Adreno
- Adreno Tile Based Rendering
- Freedreno
- PowerVR от Imagination Technologies
- PowerVR SGX
- Lowp точность
- Зависимые текстурные выборки (dependent texture reads)
- PowerVR Rogue
- PowerVR TBDR
- Открытость Imagination Technologies
- Immediate mode mobile GPUs
- Распределение различных семейств мобильных GPU у наших игроков
Эффективное использование GPU
Разработчику следует научиться эффективно использовать графический процессор устройства (GPU), чтобы приложение не тормозило и не выполняло лишнюю работу.
Настроить параметры GPU визуализации
Если ваше приложение тормозит, значит часть или все кадры обновления экрана обновляются больше чем 16 миллисекунд. Чтобы визуально увидеть обновления кадров на экране, можно на устройстве включить специальную опцию Настроить параметры GPU визуализации (Profile GPU Rendering).
У вас появится возможность быстро увидеть, сколько времени занимает отрисовка кадров. Напомню, что нужно укладываться в 16 миллисекунд.
Опция доступна на устройствах, начиная с Android 4.1. На устройстве следует активировать режим разработчика. На устройствах с версией 4.2 и выше режим по умолчанию скрыт. Для активации идёт в Настройки | О телефоне и семь раз щёлкаем по строке Номер сборки.
После активации заходим в Опции разработчика и находим пункт Настроить параметры GPU визуализации (Profile GPU rendering), который следует включить. В всплывающим окне выберите опцию На экране в виде столбиков (On screen as bars). В этом случае график будет выводиться поверх запущенного приложения.
Вы можете протестировать не только своё приложение, но и другие. Запустите любое приложение и начинайте работать с ним. Во время работы в нижней части экрана вы увидите обновляемый график. Горизонтальная ось отвечает за прошедшее время. Вертикальная ось показывает время для каждого кадра в миллисекундах. При взаимодействии с приложением, вертикальные полосы рисуются на экране, появляясь слева направо, показывая производительность кадров в течение какого-то времени. Каждый такой столбец представляет собой один кадр для отрисовки экрана. Чем выше высота столбика, тем больше времени уходит на отрисовку. Тонкая зелёная линия является ориентиром и соответствует 16 миллисекундам за кадр. Таким образом, вам нужно стремиться к тому, чтобы при изучении вашего приложения график не выбивался за эту линию.
Рассмотрим увеличенную версию графика.

Зелёная линия отвечает за 16 миллисекунд. Чтобы уложиться в 60 кадров в секунду, каждый столбец графика должен рисоваться ниже этой линии. В каких-то моментах столбец окажется слишком большим и будет гораздо выше зелёной линии. Это означает торможение программы. Каждый столбец имеет голубой, фиолетовый (Lollipop и выше), красный и оранжевый цвета.
Голубой цвет отвечает за время, используемое на создание и обновление View.
Фиолетовая часть представляет собой время, затраченное на передачу ресурсов рендеринга потока.
Красный цвет представляет собой время для отрисовки.
Оранжевый цвет показывает, сколько времени понадобилось процессору для ожидания, когда GPU завершит свою работу. Он и является источником проблем при больших величинах.
Существуют специальные методики для уменьшения нагрузки на графический процессор.
Отладить показатель GPU overdraw
Другая настройка позволяет узнать, как часто перерисовывается один и тот же участок экрана (т.е. выполняется лишняя работа). Опять идём в Опции разработчика и находим пункт Отладить показатель GPU overdraw (Debug GPU Overdraw), который следует включить. В всплывающим окне выберите опцию Показывать зоны наложения (Show overdraw areas). Не пугайтесь! Нкоторые элементы на экране изменят свой цвет.
Вернитесь в любое приложение и понаблюдайте за его работой. Цвет подскажет проблемные участки вашего приложения.

Если цвет в приложении не изменился, значит всё отлично. Нет наложения одного цвета поверх другого.
Голубой цвет показывает, что один слой рисуется поверх нижнего слоя. Хорошо.
Зелёный цвет — перерисовывается дважды. Нужно задуматься об оптимизации.
Розовый цвет — перерисовывается трижды. Всё очень плохо.
Красный цвет — перерисовывается много раз. Что-то пошло не так.
Вы можете самостоятельно проверить своё приложение для поиска проблемных мест. Создайте активность и поместите на неё компонент TextView. Присвойте корневому элементу и текстовой метке какой-нибудь фон в атрибуте android:background. У вас получится следующее: сначала вы закрасили одним цветом самый нижний слой активности. Затем поверх неё рисуется новый слой от TextView. Кстати, на самом TextView рисуется ещё и текст.
В каких-то моментах наложения цветов не избежать. Но представьте себе, что вы таким же образом установили фон для списка ListView, который занимает все площадь активности. Система будет выполнять двойную работу, хотя нижний слой активности пользователь никогда не увидит. А если вдобавок вы создадите ещё и собственную разметку для каждого элемента списка со своим фоном, то вообще получите перебор.
Маленький совет. Поместите после метода setContentView() вызов метода, который уберёт перирисовку экрана цветом темы. Это поможет убрать одно лишнее наложение цвета:
Источник
Что такое GPU-ускорение на платформе Android

Одной из многочисленных возможностей, присутствующих на современных Android-устройствах, выступает GPU-ускорение, доступное в специальном системном разделе. По ходу статьи мы расскажем о том, что это за функция и в каких случаях может повлиять на работу смартфона.
Что такое GPU-ускорение на Android
Сама аббревиатура GPU на смартфонах расшифровывается точно так же, как и на других устройствах, включая компьютеры, и означает «Графический процессор». Поэтому при активации ускорения вся нагрузка телефона переходит с ЦПУ на видеокарту, едва ли задействованную в повседневных задачах.
Примечание: Во время работы описываемого режима может значительно повыситься нагрев телефона, но, как правило, без вреда для компонентов.

Главное назначение GPU-ускорения заключается в принудительном переносе рендеринга с процессора устройства на GPU с целью повышения производительности. Как правило, особенно если брать в расчет современные мощные смартфоны или планшеты и весьма требовательные игры, подобная возможность положительно повлияет на скорость обработки информации. Кроме того, на некоторых телефонах можно получить доступ к дополнительным настройкам рендера.
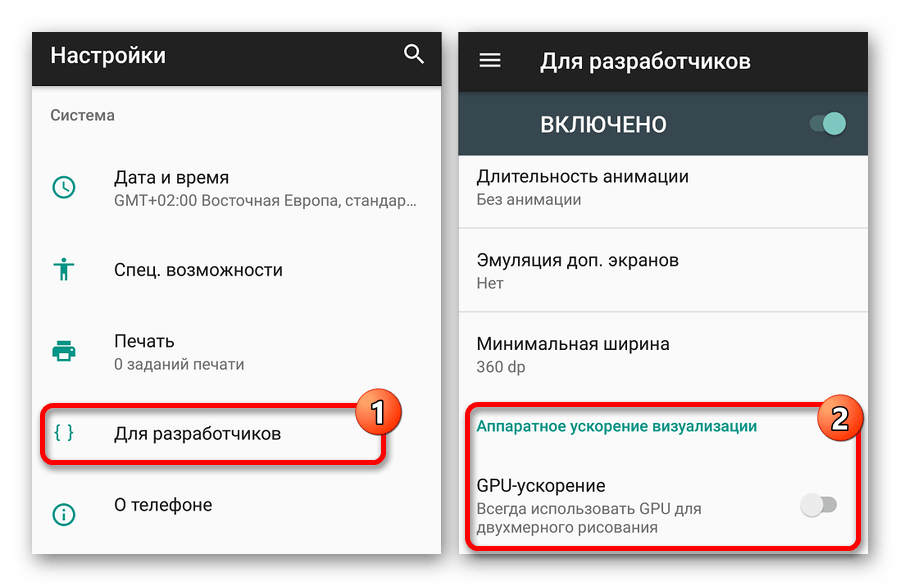
Иногда ситуация может быть полностью противоположной, в связи с чем включение принудительного рендеринга двухмерного рисования может стать причиной невозможности запуска того или иного приложения. Так или иначе, функцию можно включать и отключать без ограничений, что делает большинство проблем легко разрешимыми. К тому же, как можно понять по вышесказанному, большинство приложений все же отлично работают при включенном GPU-ускорении, позволяя использовать ресурсы устройства на максимум.
Включение и отключение
GPU-ускорение можно контролировать в определенном разделе с настройками. Однако для доступа к данной странице потребуется выполнить ряд действий. Более подробно процедура была нами разобрана в отдельной статье на сайте по следующей ссылке.
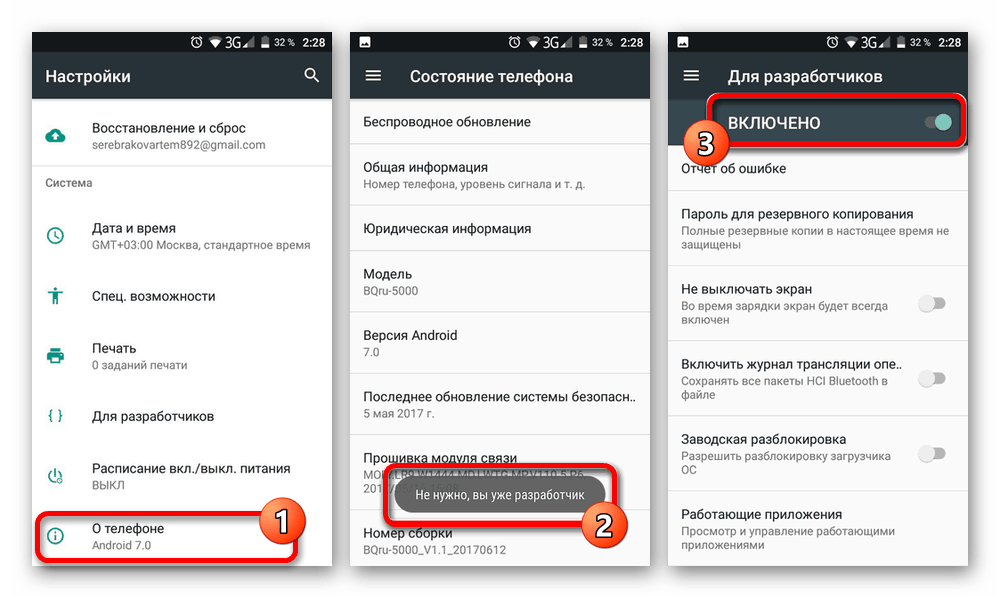
После перехода к странице «Для разработчиков» в системном приложении «Настройки» воспользуйтесь свайпом вверх и найдите пункт «GPU-ускорение» в блоке «Аппаратное ускорение визуализации». В некоторых случаях функция может иметь другое название, например, «Рендеринг принудительно», но практически всегда остается неизменным описание. Ориентируйтесь именно по нему, обратив внимание на представленный ниже скриншот.
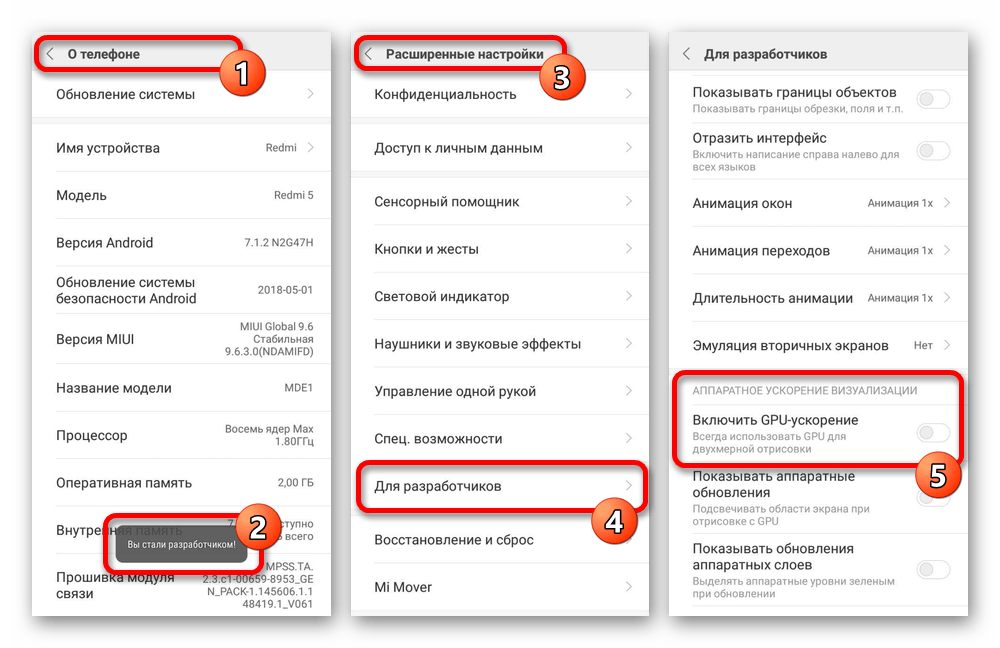
Эта процедура не станет проблемой, так как все действия легко обратимы. Таким образом, чтобы отключить принудительный рендеринг, деактивируйте пункт, указанный выше. Кроме того, данная тема напрямую связана с ускорением Android-устройства, детально рассмотренным нами также в отдельной инструкции.
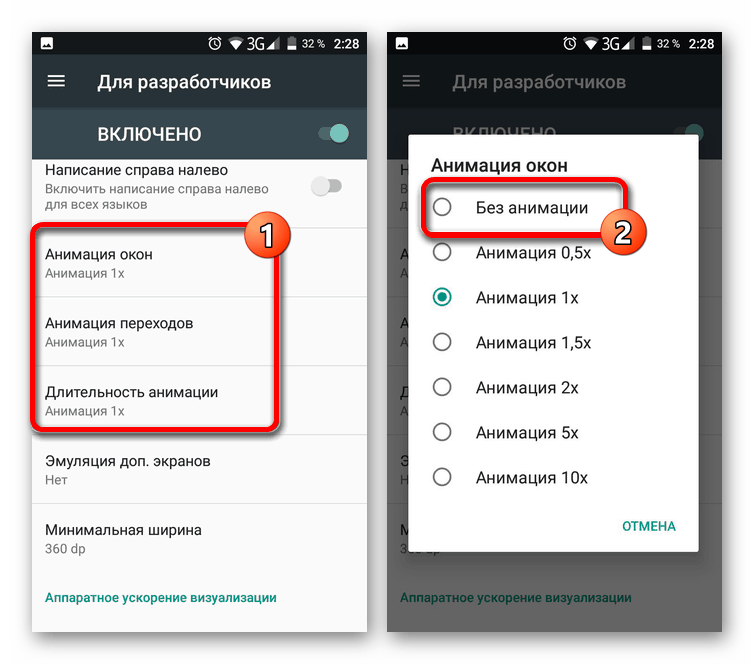
Как видно из представленной в статье информации, GPU-ускорение на Android-устройствах можно включать и отключать в зависимости от конкретной ситуации, будь то запуск требовательных игр или приложений. С этим не должно возникнуть проблем из-за отсутствия ограничений на работу функции, не считая ситуаций, когда телефон по умолчанию не предоставляет нужных настроек.
Помимо этой статьи, на сайте еще 12473 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Источник
Оптимизация рендера под Mobile, часть 2. Основные семейства современных мобильных GPU
Приветствую, дорогие любители и профессионалы, программисты графики! Приступаем ко второй части нашего цикла статей про оптимизацию рендера под Mobile. В этой части мы будем рассматривать основные семейства GPU, представленные у игроков на Mobile.

Унифицированные или специализированные шейдерные ядра
В эпоху ранних мобильных видеокарт, до распространения комплексных эффектов, существовала точка зрения, что для фрагментных шейдеров достаточно поддержки вычислений на пониженной точности. Ведь в типичном режиме дисплея применяется 8, а то и меньше бит на каждый канал цвета. Такая точка зрения привела к использованию специализированных шейдерных ядер. Для вершин использовались ядра, оптимизированные для матричных преобразований на повышенной точности FP24/FP32(highp). Для пикселей — ядра, более эффективно работающие с пониженной точностью FP16 (mediump). При этом highp на них не поддерживался. На первый взгляд, такая специализация позволяет добится более рационального распределения транзисторов на чипе. Однако, на практике это приводит к трудностям при разработке комплексных эффектов, а также при использовании текстур большого разрешения. Кроме того, специализация ядер может приводить к vertex/fragment bottleneck. Таким термином называют ситуацию, когда из-за несимметричной нагрузки на вершинные и пиксельные ядра часть ядер «простаивала».
Поэтому в современных архитектурах применяются унифицированные ядра. Такие ядра могут брать на себя вершинные, пиксельные и другие вычислительные задачи в зависимости от нагрузки.
Векторный (SIMD) или скалярный набор инструкций
В духе описанного выше стремления экономить на транзисторах, специализируя ядра, происходил и дизайн набора шейдерных инструкций. Большинство типичных преобразований для трехмерной графики оперируют 4-х компонентными векторами. Поэтому ранние GPU работали именно с такими операндами. Если же в коде шейдера содержались разнородные скалярные операции, которые не удавалось упаковать в векторные операции оптимизатором, часть вычислительных мощностей не задействовалась. Это явление можно проиллюстрировать так:
Имеется шейдер, осуществляющий распространенную операцию Multiply Add: умножить 2 операнда, а затем добавить третий. При компиляции на условной векторной архитектуре (Vector ISA = Vector Instruction Set Architecture) мы получаем одну векторную инструкцию vMADD, выполняющуюся 1 такт. На условной скалярной архитектуре мы получаем 4 скалярные инструкции, которые благодаря усовершенствованному конвейеру также выполняются за 1 такт. Теперь рассмотрим усложненный шейдер, выполняющий 2 операции, но над 2-х компонентными операндами.
В случае векторной архитектуры получаем уже 2 инструкции, требующие 2 такта на выполнение. При этом над компонентами .zw действия не производятся, и вычислительные мощности простаивают. В случае скалярной архитектуры эти же операции можно упаковать в 4 скалярных sMADD, выполняющихся за тот же 1 такт. Таким образом на скалярной архитектуре за счет усовершенствования конвейера достигается большая плотность вычислений. Тем не менее, как будет показано ниже, векторная ISA по-прежнему актуальна. А значит, есть смысл применять техники векторизации шейдерного кода. Они позволяют добиться повышенной производительности на видеокартах с векторными ISA. В то же время, как правило, это не вредит быстродействию на более современных скалярных ISA.
Опираясь на приведенные характеристики, рассмотрим распространенные в наше время семейства мобильных GPU. Начнем с наиболее часто встречающегося семейства. Многие знают, что речь идет о видеокартах Mali от британской компании ARM. Непосредственно производством чипов ARM не занимается, предлагая вместо этого интеллектуальную собственность. Как и другие мобильные видеокарты, Mali является составной частью System on Chip(SoC), т.е. работает с общей для CPU и GPU памятью и шиной.
Mali Utgard
В 2008 году на свет появились первые представители архитектуры Mali Utgard, актуальной вплоть до сегодняшнего дня. Эти видеокарты именуются по схеме Mali-4xx MPn, где xx — номер модельного ряда, а n — количество фрагментных ядер. В Mali Utgard шейдерные ядра специализированные, и во всех моделях устанавливалось только 1 вершинное ядро.
Другие особенности архитектуры Mali Utgard:
- OpenGL ES 2.0
- Отсутствие поддержки highp во фрагментных ядрах
- Векторный набор инструкций (есть смысл векторизировать вычисления)
Невзирая на спецификацию OpenGL ES, драйвера видеокарт Mali Utgard успешно компилируют фрагментные шейдеры, где используется точность highp (например, точность задана по умолчанию при помощи precision highp float). Но фактически используется точность mediump. Поэтому, все шейдеры для мобильных игр желательно дополнительно тестировать на таких видеокартах. По данным, собираемым Unity, на конец 2019 года Mali Utgard работала на девайсах у около 10% игроков. А если выставить соответствующие фильтры на market.yandex.ru, то можно увидеть, что в 2019 году было анонсировано более 10 новых телефонов с видеокартами этой архитектуры.
Если имеется готовность отказаться от этой аудитории, достаточно установить требование поддержки OpenGL ES 3.0 в AndroidManifest.xml:
Кроме Mali Utgard, распространенных мобильных GPU без поддержки OpenGL ES 3.0 на данный момент нету.
Отдельного внимания заслуживает использование текстур большого разрешения на Mali Utgard. Десять бит мантиссы при точности mediump не хватает для качественного текстурирования с разрешением текстур более 1024 на одну из сторон. Однако, несмотря на поддержку только mediump точности вычислений во фрагментных ядрах Mali Utgard, можно получить fp24 точность текстурных координат при использовании varying напрямую.
В качестве бонуса на некоторых архитектурах такой подход позволяет осуществлять prefetch текстурного содержимого до выполнения fragment shader, что минимизирует stalls при ожидании результатов текстурных выборок.
Mali Midgard
На смену Mali Utgard пришла архитектура Mali Midgard. Существует несколько поколений этой архитектуры с названиями вида Mali-6xx, Mali-7xx и Mali-8xx. Несмотря на 8-летний возраст, Mali Midgard можно назвать современной архитектурой, обеспечивающей поддержку большинства новых фич:
- унифицированные шейдерные ядра
- OpenGL ES 3.2 (compute & geometry shaders, tesselation. )
Однако в Mali Midgard сохранена векторная ISA. Учитывая широкое распространение Mali Midgard (около 25% нашей аудитории), становится целесообразной векторизация вычислений.
Еще одной особенностью Mali Midgard является технология Forward Pixel Kill. Расчет каждого пикселя производится в отдельном потоке фрагментного ядра. Если во время выполнения потока становится известно, что результирующий пиксель будет перекрыт непрозрачным пикселем другого примитива, поток завершается преждевременно и освободившиеся ресурсы используются для других вычислений.
Mali Bifrost
Следующая за Midgard архитектура Bifrost выделяется переходом к скалярной ISA. По сравнению с предыдущей архитектурой увеличено максимальное количество ядер (с 16 до 32), а также поддерживается улучшенный интерфейс с CPU, позволяющий осуществлять когерентный доступ к общей памяти: изменения содержимого памяти CPU/GPU сразу становятся «видны» друг другу несмотря на кэши, что позволяет упростить синхронизацию.
Из неофициального
Предпринято немало попыток обратного инжиниринга видеокарт Mali с целью создания Open Source драйверов под Linux. Труды самоотверженных ребят, пытающихся это осуществить, позволяют взглянуть на недокументированные особенности видеокарт Mali. Так, в проекте PanFrost есть disassembler для Mali Midgard/Bifrost, при помощи которого можно познакомится с набором шейдерных инструкций (открытой официальной информации на эту тему нет).
Adreno
Вторым по распространенности семейством мобильных GPU является Adreno. Эта видеокарта устанавливается на SoC, известный под брендом Snapdragon, от американской компании Qualcomm. Snapdragon устанавливается в топовых смартфонах современности от Samsung, Sony и др.
Актуальными видеокартами Adreno являются семейства cерий 3xx — 6xx. Все эти серии объединяют следующие особенности:
- унифицированные шейдерные ядра
- Pseudo TBR (большие размеры тайлов, размещающиеся в традиционной dedicated GPU memory)
- Автоматическое переключение в Immediate Mode Rendering в зависимости от характера сцены (FlexRender)
- Скалярный набор инструкций
Начиная с Adreno 4xx появляется поддержка OpenGL ES 3.1, а с Adreno 5xx — Vulkan и OpenGL ES 3.2.
Adreno Tile Based Rendering
На видеокарты Adreno установлена «традиционная» GPU память, называемая GMEM. Применяются объемы от 128kb до 1536kb. Это позволяет использовать больший размер тайлов по сравнению с архитектурами других разработчиков мобильных GPU. На Adreno размер тайлов динамический и зависит от используемого формата цвета, буфера глубины и трафарета. При работе в режиме Immediate Mode рендер происходит в системную память.Существует GL ES расширение, позволяющее указать предпочтительный режим: QCOM_binning_control. Однако, последние рекомендации от Qualcomm предлагают полностью полагаться на драйвера GPU, которые сами определяют наиболее предпочтительный режим для сформированного приложением командного буфера.
При работе в режиме TBR Adreno делает 2 вершинных прохода:
- Binning pass — распределение примитивов по бинам (bins, синоним тайлов)
- Полноценный vertex pass для отрисовки только тех примитивов, которые попадают в текущий Bin
Во время Binning pass Adreno рассчитывает только позиции вершин. Другие атрибуты не вычисляются, а ненужный код удаляется оптимизатором. В официальной документации (9.2 Optimize vertex processing) существует рекомендация хранить вершинную информацию, необходимую для вычисления позиций, отдельно от остальных данных. Это делает кеширование вершинных данных более эффективным.
Freedreno
В отличие от ARM и Imagination Technologies, Qualcomm неохотно делится подробностями внутреннего устройства своих GPU. Однако, благодаря усилиям «обратного инженера» Роба Кларка, многое можно узнать из проекта Freedreno, open source драйвера Adreno для Linux.
Rob Clark, автор Freedreno
PowerVR от Imagination Technologies
Imagination Technologies — британская fabless компания, знаменитая разработкой GPU для продукции Apple. Эту роль компания выполняла вплоть до появления iPhone 8/X, в которых используются внутренние разработки Apple. Хотя по оставшимся без изменений рекомендациям по оптимизациям для этих чипов, а также по наличию патентных исков к Apple от Imagination можно предполагать, что Apple продолжила развивать архитектуру PowerVR — оригинальную разработку от Imagination. В начале 2020 года Apple вернулась к практике лицензирования у Imagination Technologies. Кроме устройств с iOS/iPadOS, видеокарты PowerVR устанавливаются в большое количество смартфонов и планшетов на базе Android.
Рассмотрим семейства видеокарт PowerVR, которые до сих пор можно встретить у пользователей.
PowerVR SGX
Первые видеокарты PowerVR SGX появились в далеком 2009-м году. Существует несколько поколений этой архитектуры: Series5, Series5XT и Series5XE. Apple использовала эти GPU вплоть до iPAD 4/iPhone 5/iPOD Touch 5. Можно привести такие особенности SGX:
- унифицированные шейдерные ядра
- OpenGL ES 2.0
- векторный набор инструкций
- поддержка 10-битной точности lowp в шейдерах
- низкая производительность зависимых текстурных выборок (dependent texture reads)
Остановимся на некоторых из них подробнее.
Lowp точность
PowerVR SGX — единственные актуальные мобильные GPU с аппаратной поддержкой
lowp. Более новые модели PowerVR, а также все современные GPU других вендоров фактически используют точность mediump. Использование
lowp на PowerVR SXG позволяет добиться более высокой плотности вычислений (больше операций за такт). При этом операция swizzle (перестановка компонент вектора) для lowp, в отличие от других точностей, не является бесплатной. Эта особенность, а также узкий диапазон значений, который предоставляет lowp ([-2,2]) ограничивает сферу ее применения. При этом неудачно поставленный lowp, приводящий к артефактам на семействе SGX, не будет замечен на всех остальных видеокартах, где фактически будет использоваться точность mediump. По этой причине стоит рассмотреть отказ от использования lowp в шейдерах.
Зависимые текстурные выборки (dependent texture reads)
Как известно, операции сэмплирования текстур являются наиболее медленными из-за необходимости ожидания результатов чтения памяти. В случае мобильных SoС речь идет об общей системной памяти с CPU. Для уменьшения количества обращений к медленной памяти используются текстурные кеши. Чтобы не было простоя в начале растеризации с использованием текстуры, есть смысл закешировать используемые участки заранее. Если фрагментный шейдер использует текстурную координату, передаваемую из вершинного шейдера без изменений, то необходимый для кэширования участок текстуры можно определить до выполнения фрагментного шейдера. Если же фрагментный шейдер меняет текстурную координату либо вычисляет ее, используя данные из другой текстуры, то сделать это не всегда возможно. В результате выполнение фрагментного шейдера может замедлиться. Видеокарты PowerVR SGX особенно «болезненно» реагируют на такой сценарий. При этом даже использование перестановки компонент текстурной координаты (swizzle) приводит к dependent texture read. Приведем пример shader program без dependent texture read.
vertex program
fragment program
fragment program
PowerVR Rogue
Дальнейшее развитие видеокарты PowerVR получили в архитектуре Rogue.Существует несколько поколений этой архитектуры: от Series6 до Series9. У всех PowerVR Rogue есть такие особенности:
- унифицированные шейдерные ядра
- скалярная архитектура инструкций
- поддержка OpenGL ES 3.0+ (вплоть до 3.2, а также Vulkan API у свежих линеек)
PowerVR TBDR
Как и во всех распространенных мобильных GPU, в PowerVR используется тайловый конвейер. Но в отличие от конкурентов, Imagination пошла дальше и реализовала отложенную растеризацию примитивов, позволяющую пропускать шейдинг невидимых пикселей независимо от порядка отрисовки. Такой подход получил название Tile Based Deferred Rendering,а процесс устранения невидимых пикселей — Hidden Surface Removal (HSR).

Hidden Surface Removal
Рекомендуется рисовать непрозрачную геометрию до прозрачной и не использовать Z Prepass, который в случае видеокарт PowerVR в большинстве сценариев приведет к лишней работе. Однако несколько подряд идущих прозрачных пикселей, перекрывающих друг друга, полностью шейдятся для получения корректного цвета с учетом смешивания. Последний же прозрачный пиксель может быть отброшен, если за ним следует непрозрачный пиксель.
Открытость Imagination Technologies
Создатели PowerVR предоставили в открытый доступ больше документации по сравнению с другими разработчиками GPU. Детально описана архитектура графического конвейера, а также набор инструкций для архитектуры Rogue. Существует удобный инструмент PVRShaderEditor, позволяющий на лету получать профилировочную информацию по шейдеру, а также его дизассемблерный листинг для Rogue.
Несмотря на ограниченное присутствие видеокарт PowerVR в среде устройств на базе Android, есть смысл изучать их архитектуры для грамотного программирования графики под iOS.
Immediate mode mobile GPUs
Мы рассмотрели наиболее распространенные семейства мобильных видеокарт. Во всех этих семействах применялась тайловая архитектура рендера. Однако существуют мобильные видеокарты, в которых используется и традиционный immediate mode подход. Приведем некоторые из них:
- nVIdia (Tegra SoC)
- Все семейство Intel, кроме последних Gen 11
- Vivante GCxxxx (+Arcturus GC8000)
Особенностью мобильных видеокарт, работающих в immediate mode, является дорогая операция очистки FBO. Напомним, что на тайловой архитектуре полноэкранная очистка ускоряет рендер, позволяя драйверу не добавлять Load операцию старого содержимого в тайловую память. На мобильных immediate mode GPU полноэкранная очистка — ощутимая по времени операция, позволяющая, кроме прочего, такие GPU «вычислить». Если добавление очистки не ускоряет, а замедляет рендер, то, скорее всего, мы работаем с immediate mode GPU. Ну и, конечно, не забудем упомянуть о том, что на immediate mode GPUs смена таргета — «условно бесплатная» процедура.
Распределение различных семейств мобильных GPU у наших игроков
Приведем статистику по мобильным GPU, собранную у наших игроков на конец 2019 года:
Ниже раскроем сегмент «Others»
Исходя из этих данных, посмотрим на распределение GPU с точки зрения их основных особенностей.
Векторные ALU (arithmetic logic unit) устаревают и заменяются скалярными. На сегодня основная масса мобильных GPU с векторным набором инструкций — это Mali Midgard, который можно считать средним по производительности. Т.к. векторизация, как правило, не замедляет выполнение на скалярных ALU, стоит рассматривать векторизацию как актуальный прием оптимизации шейдеров под mobile.
Специализированные шейдерные ядра устарели и заменяются унифицированными. Vertex Bottleneck на скелетном меше более не страшен. Специализированные ядра используются только на семействе Mali-4xx (Utgard). Напомним, что эти GPU поддерживают только OpenGL ES 2.0. У нашей аудитории их около 3.5%.
И наконец, подавляющее количество мобильных GPU используют тайловый подход. Immediate Mode стал маргинальным и быстро вытесняется вместе с видеокартами, его применяющими. Доля immediate mode GPUs у наших игроков составляет около 0.7%.
Источник



