- Apple анонсировала M1 Pro и M1 Max: гигантские новые SoC на архитектуре ARM с полной производительностью
- Почему процессоры Apple M1 для ноутбуков превосходят последние модели Intel Core и AMD Ryzen? Разбираемся в деталях.
- Ударный старт
- Продажи подскочили
- В чем тайна?
- Общие характеристики
- RISC vs. CISC
- RISC — Reduced Instruction Set Computer
- CISC — Complex Instruction Set Compute
- Декодер и буфер команд в Apple M1
- GPU и UMA-архитектура памяти
- SoC Intel и AMD и интегрированная графика
- UMA от Apple
- Ремарка. Деловые причины.
Apple анонсировала M1 Pro и M1 Max: гигантские новые SoC на архитектуре ARM с полной производительностью

Сегодняшний основной доклад Apple Mac был очень насыщенным — компания анонсировала новую линейку устройств MacBook Pro на базе двух различных новых SoC в линейке Apple Silicon: M1 Pro и M1 Max.
M1 Pro и Max представляют собой продолжение прошлогоднего M1, процессора Mac первого поколения Apple, который стал первым этапом для Apple в реализации планов по замене процессоров на архитектуре x86 чипами собственного дизайна. M1 был успешным для Apple, продемонстрировав фантастическую производительность при невиданной доселе энергоэффективности на рынке ноутбуков. Хотя M1 достаточно быстрый, это все еще был небольшой SoC. Он предназначался, в первую очередь, для таких устройств, как iPad Pro. Соответственно, у него более низкий TDP, уступающий более производительным и мощным чипам от конкурентов.
Сегодняшние два новых чипа стремятся изменить эту ситуацию. При этом Apple делает все возможное для повышения производительности, увеличивая количество ядер процессора и графического процессора, плюс инвестируя в разработку электронных компонентов. Компания вкладывает в это направление весьма немалые средства.
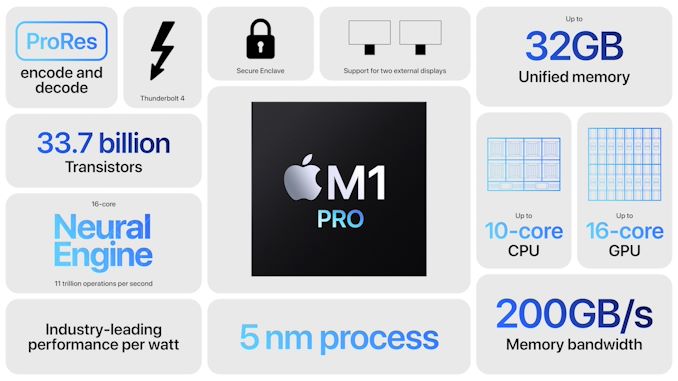
M1 Pro: 10-ядерный процессор, 16-ядерный графический процессор, 33,7 млрд транзисторов в 245 мм 2
Первым из двух чипов, которые были анонсированы, был M1 Pro. Он стал основой для того, что Apple называет бескомпромиссными SoC для ноутбуков.
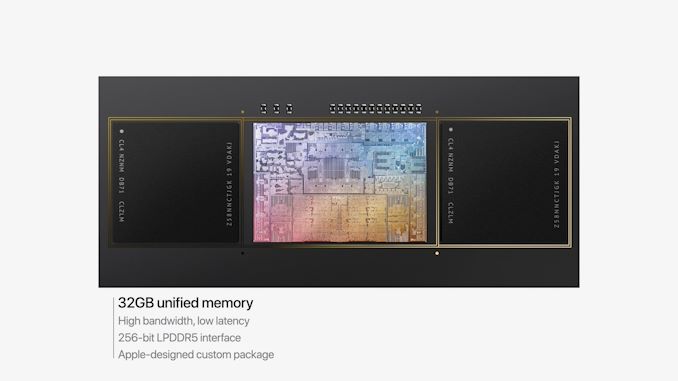
Apple начала презентацию с показа корпусировки SoC, M1 Pro сохраняет собственный дизайн корпусировки. Apple корпусирует чип SoC вместе с чипами памяти на одной органической печатной плате, что контрастирует с другими традиционными чипами, такими как AMD или Intel, где используются отдельные модули для DRAM. Подход Apple, вероятно, значительно повышает энергоэффективность и компактность.
Компания рассказала о том, что она удвоила пропускную способность шины памяти для M1 Pro по сравнению с M1. Тем самым завершен переход от 128-битного интерфейса LPDDR4X к новому 256-битному интерфейсу LPDDR5, с заявленной пропускной способностью памяти до 200 ГБ/с. Мы не знаем, является ли эта цифра точной или приблизительной, но стандарт LPDDR5-6400 как раз соответствует 204,8 ГБ/с.

В презентации Apple продемонстрировала снимки как M1 Pro, так и M1 Max, чтобы мы увидели макет чипа и деление на блоки. Начнем с контроллеров памяти, которые теперь в углах SoC, а не по краям, как на M1. Из-за увеличенной ширины интерфейса контроллеры памяти стали занимать довольно большую часть SoC. Еще более интересным является тот факт, что Apple теперь, по-видимому, использует два блока кэша системного уровня (SLC) непосредственно за контроллерами памяти.
Блоки кэша на системном уровне Apple отличаются тем, что обслуживают весь SoC, и способны увеличить пропускную способность, уменьшить задержку или просто сэкономить электроэнергию, избегая транзакций с памятью вне кристалла, что значительно повышает общую энергоэффективность. Этот блок SLC нового поколения выглядит совсем иначе, чем у M1. Ячеек SRAM больше, чем в M1, поэтому, хотя мы не можем точно подтвердить это прямо сейчас, это может означать, что в каждом блоке SLC 16 МБ кэша — для M1 Pro это будет 32 МБ общего кэша SLC.

Что касается процессора, Apple сократила количество энергоэффективных ядер с 4 до 2. Мы не знаем, будут ли эти ядра похожи на ядра M1 по эффективности или Apple приняла IP нового поколения от A15 SoC — но ясно, что новый iPhone SoC имеет некоторые более крупные микроархитектурные изменения.
Что касается производительных ядер, Apple удвоила их количество до 8. Производительные ядра Apple были чрезвычайно впечатляющими на M1, однако отставали от других 8-ядерных SoC с точки зрения общей многопоточной производительности. Удвоение ядер должно продемонстрировать огромное повышение производительности в многопотоке.
На снимке мы видим, что Apple зеркалирует два 4-ядерных блока, кэши L2 также зеркалируются. Хотя Apple пишет 24 МБ L2, я думаю, что это скорее конфигурация 2×12 МБ аналогично конфигурациям AMD. В таком случае синхронизация двух кластеров производительных ядер будет проходить через внутреннюю шину и SLC. Здесь можно лишь предполагать, но это предположение имеет смысл, учитывая показанный макет.
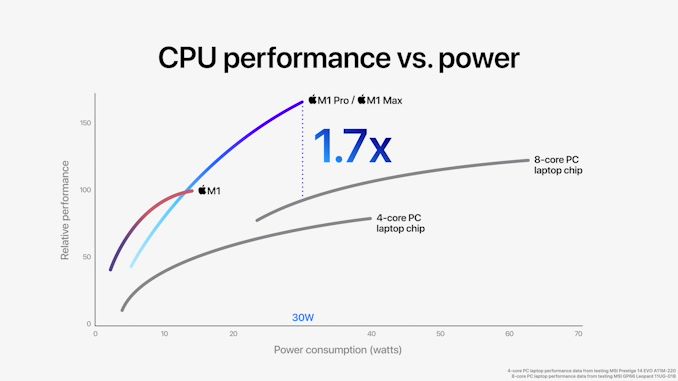
Что касается производительности процессора, Apple провела некоторые сравнения с конкурентами. В частности, сравниваемые здесь SKU Core i7-1185G7 от Intel и Core i7-11800H, 4-ядерные и 8-ядерные варианты новейших процессоров Intel Tiger Lake по техпроцессу 10nm ‘SuperFin’.
Apple утверждает, что в многопоточной производительности новые чипы значительно превосходят любые конкурентные чипы от Intel, причем при более низком энергопотреблении. Представленные кривые производительности и мощности показывают: при равном энергопотреблении в 30 Вт новые M1 Pro и Max в 1,7 раза быстрее по пропускной способности процессора, чем 11800H, кривая мощности которого чрезвычайно крутая. В то же время при равных уровнях производительности — пиковой у 11800H — новый M1 Pro/Max достигает тех же показателей при энергопотреблении ниже на 70%. Эти результаты на голову выше того, что есть у Intel.

Наряду с мощными процессорными блоками Apple также радикально масштабирует свою кастомную архитектуру GPU. M1 Pro теперь оснащен 16-ядерным графическим процессором с заявленной вычислительной способностью 5,2 терафлопс. Он идет в паре с гораздо более широкой шиной памяти и, предположительно, 32 МБ SLC. Это аналогично подходу AMD с их GPU Infinite Cache.
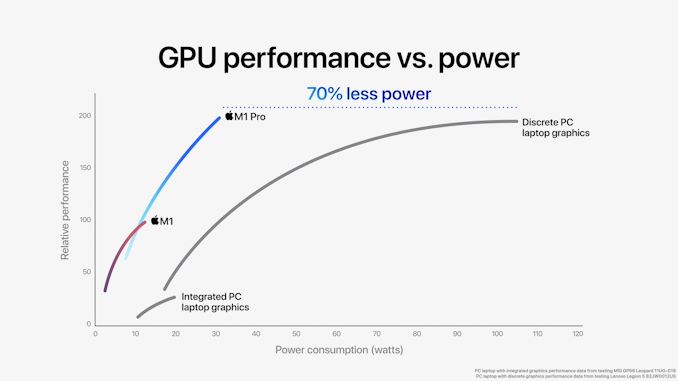
Производительность графического процессора Apple, как утверждается, значительно превосходит производительность интегрированной графики конкурентов предыдущего поколения. По этой причине компания решила провести прямые сравнения с дискретной графикой ноутбуков среднего класса — GeForce RTX 3050 Ti 4 ГБ. По результатам тестов чип от Apple показал аналогичную производительность, используя на 70% меньшую мощность. Правда, неясно что такое 30 Вт — является ли это общей мощностью SoC или системы. Возможно, Apple просто сравнивает сам блок графического процессора.

Наряду с GPU и CPU, Apple также отметила значительно улучшенный медиадвижок, который теперь может аппаратно ускорять декодирование и кодирование ProRes и ProRes RAW, что пригодится создателям контента и профессиональным видеографам. Apple Mac традиционно хороши для работы с видео, но аппаратно ускоренные движки для форматов RAW были бы киллер-фичей, которая станет решающей для этой аудитории.
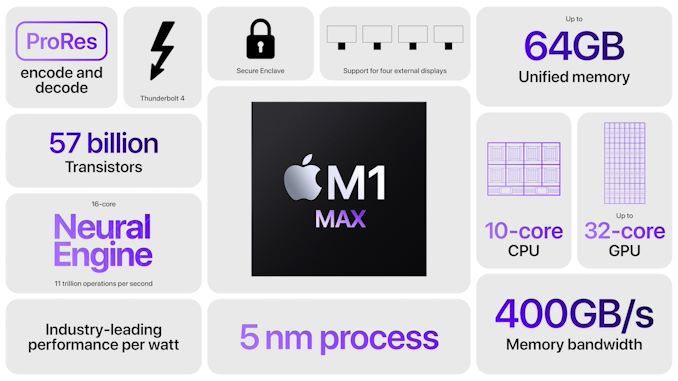
M1 Max: 32-ядерное GPU чудовище на 57 миллиардов транзисторов и 432 мм 2 .
Кроме M1 Pro, Apple также рассказала о «большем брате» — M1 Max. В то время как M1 Pro догоняет и опережает конкурентные ноутбуки с точки зрения производительности, M1 Max предоставляет то, чего раньше еще не было: графический процессор «с турбонаддувом» на 32 ядра. По сути, это больше не SoC со встроенным графическим процессором, а GPU с встроенным SoC.

Корпусировка для M1 Max тоже отличается — чипы DRAM увеличились с 2 до 4, что соответствует увеличению ширины интерфейса памяти с 256-бит до 512-бит. Apple рассказывает о впечатляющей пропускной способности в 400 ГБ/с. Если это LPDDR5-6400, было бы более точным указать 409,6 ГБ/с. Такая пропускная способность неслыханна в SoC, но является нормой для производительных графических чипов.

M1 Max выглядит довольно своеобразно — во-первых, вся верхняя часть чипа над графическим процессором очень похожа на M1 Pro, указывая на то, что Apple повторно используют большую часть дизайна, и что вариант Max просто растет вниз.
Добавлены два 128-битных блока LPDDR5, причем количество блоков SLC растет вместе с ними. Если бы было 16 МБ на блок, то это представляло бы собой 64 МБ общего кэша для всего SoC. Помимо очевидного использования в GPU, мне интересно, чего могут достичь процессоры с помощью такой гигантской пропускной способности памяти.
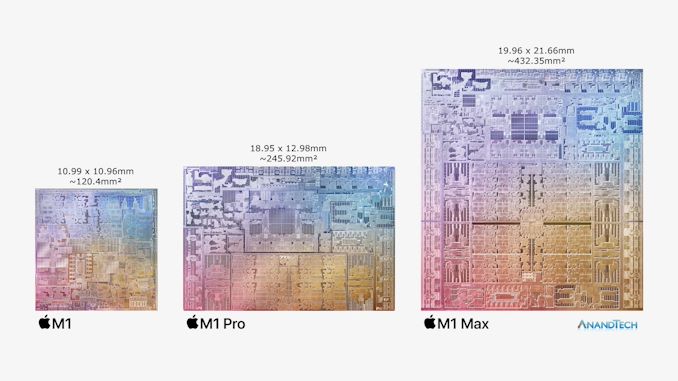
M1 Max впечатляет количеством транзисторов. Так, Apple сообщила, что у M1 Pro их количество достигает 33,7 млрд, в то время как M1 Max включает уже около 57 млрд транзисторов. AMD, в то же время, с гордостью рассказывает о 26,8 млрд транзисторов в 7-нм графическом чипе Navi 21 на 520 мм 2 . У Apple здесь в два раза больше транзисторов при меньшем размере чипа благодаря использованию передового 5-нм техпроцесса от TSMC. Даже по сравнению с самым большим 7-нанометровым чипом NVIDIA с 54 млрд транзисторов в серверных GA100 — M1 Max имеет большее количество транзисторов.
Что касается размеров чипов, Apple разместила на одном из слайдов M1, M1 Pro и M1 Max рядом друг с другом, и они, похоже, имеют масштаб 1:1. В этом случае M1, который мы уже знаем, составляет 120 мм 2 , соответственно M1 Pro 245 мм 2 , а M1 Max около 432 мм 2 .

Большая часть чипа занята 32-ядерным графическим процессором, для которого Apple заявляет производительность в 10,4 терафлопс. Похоже, что Apple зеркалировала их 16-ядерный GPU. Первое, что приходит на ум — это 2 графических процессора, работающих в унисон, и какая-то общая логика между двумя половинами графического процессора. Мы сможем рассказать больше, как только проверим поведение системы на программном уровне.
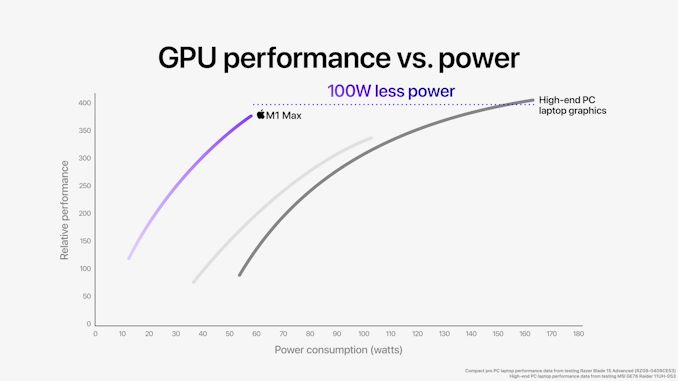
С точки зрения производительности Apple успешно может конкурировать с лучшими предложениями на рынке, сравнивая производительность M1 Max с производительностью мобильного GeForce RTX 3080 при меньшей мощности на 100 Вт (60 Вт против 160 Вт). M1 Max и тут превосходит дискретный GPU NVIDIA, при этом потребляя на 40% меньше энергии.
Презентация нового поколения Apple Silicon стала тем, чего мы ждали больше года. Я думаю, что Apple удалось не только оправдать ожидания, но и значительно превзойти их. Как M1 Pro, так и M1 Max кардинально отличаются от всего, что мы когда-либо видели в области ноутбуков. Если M1 был неким признаком успеха Apple в их кремниевых начинаниях, то два новых чипа превосходят любые варианты, что мы видели у конкурирующих компаний.
Источник
Почему процессоры Apple M1 для ноутбуков превосходят последние модели Intel Core и AMD Ryzen? Разбираемся в деталях.
Ударный старт
Когда компания Apple летом 2020 года впервые анонсировала переход Mac-ов на собственные процессоры с архитектурой ARM многие отнеслись к этому скептически.
“Нельзя делать начинку для ПК из комплектующих для iPhone” — волновались профессиональные пользователи “тяжелых” приложений, любители ПК-игр и юзеры, привыкшие открывать в браузере одновременно по 50 вкладок.
И первые же тесты повергли индустрию в шок: ноутбуки не только не уступали мобильным собратьям на базе архитектуры # x86, но и превосходили их в одних тестах за другим. И по общей производительности на синтетических тестах и по реальной на широчайшем спектре приложений.
В некоторых результатах перфоманс достигал уровня среднего десктопа с внешней видеокартой младшего класса.
Причем это касалось как индивидуальных приложений, так и работы в мультизадачном режиме.
“. Одновременный запуск сразу 50 приложений прошёл на # MacBook Pro с процессором M1 без каких-либо заметных лагов, тогда как ноутбуку на Intel потребовалось куда больше времени… Кроме того, модель на M1 даже не включила активное охлаждение, в то время как вариант на Intel будто начал «готовиться ко взлёту. ”
“. Запуск приложений тоже происходит на новом MacBook Pro быстрее, чем на версии с процессором Intel. ”
“. Открытие большого числа вкладок в Safari никак не нагрузило ноутбук на M1, тогда как вариант на Intel изрядно начал “лагать” уже на 30-й вкладке. ”
“. Самым большим сюрпризом стала скорость работы в видеоредакторах. Обработка видео 1080р длительностью 30-40 минут в DaVinci Resolve на старом MacBook занимала около 40 минут. Модель на M1 справляется за 4 минуты — столько же требуется времени моему стационарному ПК с видеокартой GeForce GTX 1060. ”
Фактически, впервые в истории “маководы” заговорили об играх на MacBook — а эта сторона никогда не была козырем “фруктовых” компьютеров.
Удивительно, но даже MacOS-приложения скомпилированные под x86, исполняемые в режиме динамической перекомпиляции под специальным системным ПО Rosetta 2 — показывали недурные результаты. Дело в том, что само по себе исполнение не родных программ “на лету” очень серьезно отъедает ресурсы.
(Анекдот в том, что ПО Rosetta первой версии в далеком 2006 году было предназначено для перевода приложений под RISC-процессоры IBM PowerPC на CISC-архитектуру Intel x86. Сегодня, по прошествии неполных 15 лет, Rosetta 2 помогает вернуть экосистему Mac в обратном направлении: от x86 к RISC-процессорам ARM.)
Продажи подскочили
В результате пользователи совершенно забыли о былых опасениях.
Новые MacBook стали товаром “черной пятницы” 2020-го пандемийного года. Продажи MacBook достигли уровней, ранее этими дорогостоящими ноутбуками ни разу не достигнутых. В том числе и у нас в России.
Так, весной этого года MacBook Air Late 2020 на M1 впервые оказался в десятке самых продаваемых продуктов на отечественном рынке. И это при том, что средняя цена “яблочного” устройства превосходит большинство соседей по хит-параду раза этак в три.
В чем тайна?
Так в чем же великая тайна процессоров, изначально разрабатывавшихся для iPhone и iPad? Как так получилось, что гранды микропроцессорной индустрии эпохи ПК — Intel и AMD — проигрывают # ARM-чипу именно по скорости.
То что они проигрывают ему по энергоэффективности, времени автономной работы и т. п. — как бы понятно. В этом-то никто и не сомневался.
Но Photoshop и Premiere, Java и Python-разработка, Maya и 3ds Max. Это потрясающе!
Не будем томить читателя, не желающего погружаться в детали. По большому счету преимущества видны в следующих направлениях:
- Особенностях RISC-архитектуры CPU и ее применения для оптимизации процесса выполнения кода; главным образом, по части внеочередного исполнения.
- Относительно небольшие по общей площади занимаемой на кристалле ядра CPU ARM-архитектуры, плюс продвинутый технологический процесс 5-нанометров позволяют отдать больше места на кристалле дополнительным блокам, в особенности GPU — графической подсистеме.
- Особенность работы с памятью — UMA,также важная для GPU и других периферийных процессов.
А теперь разберемся подробнее, что же имеется в виду.
Общие характеристики
Итак, с чем мы имеем дело по части базовых характеристик. (Сразу скажем: ничего поражающего воображение мы по ним не увидим.)
8-ми или 7-ми ядерный процессор M1 имеет на борту 4 высокопроизводительных ядра FireStorm и 4 энергосберегающих Icestorm.
Частоты меняются здесь в очень широких пределах, в зависимости от нагрузки: “старший” FireStorm имеет диапазон от 0,6 до 3,2 ГГц, частоты Icestorm – от 0,6 до 2,1 ГГц. (В пиковом режиме — не много, вообще-то, в сравнении с последними поколениями логики Intel/AMD, где в режиме турбо частоты могут составлять 4,5-5 ГГц.)
Однако при максимальных частотах четыре ядра Firestorm рассеивают, все вместе, до 14 Вт, а четыре ядра Icestorm – до 1,3 Вт. Будем считать, что общий TDP Apple M1 – в районе 15 Вт. У мобильных конкурентов x86, конечно, значительно выше — 35-45 Вт.
Плюс на кристалле здесь присутствует GPU, блок тензорики (нейропроцессоры), цифровой сигнальный процессор (ISP), блок аппаратной акселерации шифрования, ну и понятно, всяческие контроллеры периферийных систем.
Отдельно важно отметить, что микросхемы памяти ОЗУ конструктивно совмещены с интегральной схемой процессора. Они выполнены в едином физическом блоке. (system-n-package).
Максимальный размер ОЗУ при этом конечно фиксирован — 16 Гб. Но память реально быстрая: LPDDR4X SDRAM 4266 Mегатранзакций/с.
По всему вышесказанному — мы вроде бы имеем просто качественный энергосберегающий чип, чрезвычайно гибко обращающийся с энергопотреблением. Что абсолютно понятно для процессора из сферы гаджетов, в сравнении с процессором для ПК.
Но откуда же взялись победные реляции в плане скорости?
RISC vs. CISC
Традиционно выделяют два типа процессорной архитектуры, иначе говоря два типа системы команд (ISA- Instruction Set Architecture) — RISC и CISC.
Чтобы понять принципиальное различие между ними, освежим, как вообще работает компьютер. ЛЮБОЙ компьютер.
Есть команда в программе: “просуммировать два значения из ячеек M1 и M2, результат положить в M3”: SUM M1, M2, M3.
Команда поступает на декодер команд . Декодер расшифровывает что же, собственно, написано в команде и переводит это на язык микроинструкций. Они размещаются в буфере микроинструкций. Он же буфер исполнения или буфер переупорядочивания (ROB — Re-Order Buffer) .
(Оба этих блока будут крайне важны для нас для понимания преимуществ архитектуры RISC вообще и ARM-процессоров Apple Silicon в частности. Поэтому запомним эти слова: декодирование и переупорядочивание.)
Последовательность микроинструкций и указывает всем исполнительским блокам, что делать и в каком порядке.
В нашем случае нужно:
- Достать из Памяти данные из ячеек M1 и M2 (GET M1; GET M2;); за это отвечает контроллер памяти (или контроллер шины памяти как это часто обозначают).
- Разместить их во внутренних регистрах блока АЛУ R1 и R2 (PUT R1; GET R2;), соответственно; (АЛУ — Арифметико-Логическое Устройство).
- Указать АЛУ что данные из нужных регистров надо сложить, а результат положить во внутренний регистр R3 (SUM R1, R2; PUT R3;).
- Забрать результат из R3 и положить в ячейку памяти M3 (GET R3; PUT M3).
RISC — Reduced Instruction Set Computer
В прямом переводе “процессор с сокращенным набором команд”.
Но лучше сказать: “коротких”, “простых”, “фиксированных” команд. Именно это важно.
Что важно — длина команды здесь фиксирована. Число операндов — по сути ячеек памяти с которым идет обращение в процессе исполнения — постоянно.
Поэтому декодировать эту команду очень просто — блок декодера команд способен во-первых работать очень быстро, а во-вторых прост по своей внутренней конструкции.
А за счет простоты мы можем поставить параллельно большее число таких блоков — это даст возможность загружать все блоки АЛУ нашего процессора параллельно — чтобы они не ждали пока декодируются следующие команды.
Представим. Если у нас, например, 8 АЛУ, и все операции фиксированы по размеру и скорости исполнения, мы можем спокойно параллельно исполнить 8 операций, естественно, если они не перебивают друг друга — выполнение следующей не зависит от результатов предыдущей.
Кстати, чем быстрее мы декодируем команды, тем быстрее поймем — как можно их распараллелить: проанализировать алгоритм и разложить микроинструкции в буфере таким образом, чтобы логика вычислений не нарушалась, но при этом у всех иcполнительных блоков была работа. Поэтому его и называют буфером переупорядочивания (ROB).
Таким образом ISA типа RISC открывают более широкие возможности для так называемого внеочередного исполнения, следовательно распараллеливания кода.
Типичными представителями RISC-процессоров являются ARM (ныне принадл. Nvidia), IBM POWER, Oracle (Sun) SPARC, MIPS, RISC-V.
CISC — Complex Instruction Set Compute
Здесь длина инструкции, число операндов в ней, изменчиво.
Дешифрация таких команд — сложная задача. Таких блоков много в процессор не поставишь.
По сути в одну CISC команду “запихнуто” сразу несколько RISC-команд. И изначально, до декодирования, неизвестно сколько именно. CISC-команда может исполняться за несколько тактов, циклов обращения к памяти.
И пока конкретный блок АЛУ не выполнит всю эту последовательность, он не может перейти к выполнению другой команды. Это снижает возможности внеочередного исполнения и распараллеливания выполнения кода.
Есть еще одно важное отличие — регистры АЛУ в RISC неспециализированные, однотипные и их в АЛУ много. А вот в CISC они предназначены для хранения данных определенной длины. Они зависят от типа обрабатываемых данных, можно сказать. И регистров каждого из типов в АЛУ мало. (В определенных случаях данные могут вообще обходить регистры АЛУ и непосредственно поступать на вычислитель из кэш-памяти, но не будем углубляться в это.)
Классическим примером ISA типа CISC и является Intel x86, то есть классические процессоры для ПК от Intel и AMD.
Декодер и буфер команд в Apple M1
М1 — как RISC-процессор использует простые и эффективные блоки декодирования. И их здесь больше, чем у x86 процессоров — very wide instruction decoders. Существенно больше: 8 штук на ядро. И работают они быстрее.
В то время как в самых мощных чипах Intel — максимум по 4 декодера. Понятное дело: блок декодирования CISC — сложная штуковина, в отличии от простейшей конструкции в RISC.
Для Apple это открыло возможность для увеличения буфера внеочередного исполнения инструкций (ROB). Ведь со столь мощным блоком декодирования его есть чем загрузить.
Производители не указывают точный размер буфера, но по оценкам экспертов в старших ядрах Apple M1 Firestorm он составляет до 630 инструкций; и даже в младших Icestorm Icestorm оценивается до 560.
В то время как современные ядра процессоров Intel Willow Cove (для ноутбуков Core 11Gen Tiger Lake) глубина буфера достигает лишь 352. В AMD Zen 3 (Ryzen Cezanne-H) и вовсе 256.
То есть M1 тут обставляет конкурентов до 2 раз по размеру буфера. А это кратно увеличивает возможность внеочередного исполнения.
В конечном счете это мощно сказывается на итоговой производительности.
GPU и UMA-архитектура памяти
А теперь поднимемся на уровень выше — уйдем от внутреннего устройства CPU и рассмотрим чип M1 как SoC — систему на чипе включающую также интегрированные блоки GPU.
SoC Intel и AMD и интегрированная графика
Прежде чем понять в чем достижение Apple, надо понять суть опыта производителей x86-процессоров в направлении интегрированной графики.
Да, конечно, процессоры Intel и AMD для массовых устройств на сегодня — также вполне полноценные SoC. Они используют интегрированную графику. Причем в случае AMD Radeon она традиционно считается достаточно сильной. (В сопоставлении с Intel.) Да и Intel не стоит тут на месте, скажем начиная с последнего поколения Core компания предложила новый дизайн GPU Intel Xe; чипы этой архитектуры использованы и в фирменных дискретных адаптерах “синих”.
Но интегрированная графика Intel и AMD — все равно слишком слаба. В целом в архитектуре чипа она играет роль как бы “неродного ребенка”. Фактически оба производителя заявляют — хотите настоящей производительности на “тяжелых” графических приложениях и играх — берите дискретную видеокарту.
Все в системе рассчитано на то, чтобы обеспечить работу ядер CPU, а GPU здесь как бы на вторых ролях. И особенно это заметно по организации работы с ОЗУ.
Любая интегрированная графика использует область оперативной памяти для хранения данных графической подсистемы. Скажем, в обычном случае 1-2 Гб из объема ОЗУ выделяется под область GPU.
Но фактически за управление загрузкой этой области памяти отвечает CPU. Он перебрасывает нужные данные из области основной памяти (“своей”) в выделенную “графическую”. А GPU уже выбирает оттуда.
Естественно это замедляет процесс обработки видеопотока.
Дополнительно? есть такая общая установка, очень грубая, но тем не менее…
Ядра CPU обыкновенно пересылают из ОЗУ и обратно небольшие блоки данных, но часто. Назовем этот пункт, условно, “процессорным” типом работы с памятью. Видеопамять же дискретных адаптеров — “графический” тип — как правило забирает из памяти огромные куски едиными блоками.
Соответственно контроллеры памяти, скажем, чипов Nvidia GeForce и Intel Core имеют разную организацию, адаптированную к своему типу потребления данных — передача больших объемов по широкому каналу или более узкий, но высокочастотный канал. Под это заточена организация работы внутренних шин памяти и система управления ими.
Угадайте с одного раза, какой тип организации — “процессорный” или “графический” использован в SoC Core или Ryzen? Конечно “процессорный”. То есть вся общая работы внутренней шины памяти для встроенного GPU — она как бы “не родная”. То же касается и прочих периферийных устройств.
UMA от Apple
Apple меняет подход к UMA (Unified Memory Access). Здесь отдельной области ОЗУ для GPU не выделяется — графический чип может напрямую обращаться к ОЗУ и задействовать столько памяти, сколько ему реально нужно. (Вероятно, это касается прочих спецпроцессоров в составе чипа.)
Контроллер же памяти, шина, очевидно рассчитаны на этот момент и учитывают тип потребления данных, характерный именно для GPU.
Да и сами физические микросхемы памяти в целях снижения задержек и поддержки оптимальных частот, как мы помним, совмещены с SoC конструктивно. Все это дает возможность встроенному GPU проявить себя в полной мере, быть “на равных” с ядрами CPU в плане доступа к памяти.
Кроме того Apple и за счет использования 5-нанометровых ядер CPU, из каковых “больших” — максимум 4, и за счет относительно небольших областей кэш-памяти — элементарно получил возможность отдать на кристалле большую площадь под ядра GPU. В итоге, графика от Apple — это просто более продвинутый чип, чем Intel Xe и Radeon Vega.
Если же взглянуть на ситуацию с GPU в целом, можно заключить, что в сравнении с классической организацией интегрированных систем ПК, в Маках самому ресурсоемкому — графике — просто отдано больше места. И в физическом смысле — площади на кристалле, и в организационном — механизмы доступа к ОЗУ и проч.
Но за счет этого выигрывает не только сама графика, но и скорость работы компьютера в целом — ведь “тяжелая” часть имеет собственный канал доступа к системе. Следовательно, не отвлекает CPU от своих собственных задач.
Ремарка. Деловые причины.
В заключении хотелось бы напомнить о следующем. (Хотя это и банальность.)
Apple — производит чипы для себя. Он сам является единственным поставщиком конечных устройств Mac. Сам отвечает за, по простому говоря, разводку материнской платы. Сам решает сколько полосы пропускания отдавать на те или иные подсистемы.
Источник



