- Распознавание и генерация речи в Android
- Программируем распознавание речи в Android
- Генерация речи в Android
- Распознавание голоса java android
- Android Speech to Text Tutorial
- Сверхбыстрое распознавание речи без серверов на реальном примере
- С чего вдруг?
- Зачем нам что-то еще кроме Яндекса и Google?
- Что будем делать?
- Что такое Pocketsphinx
- Транскрипции
- Голосовая активация
- Запускаем распознование
- Как получить результат распознавания
- Как превратить распознанную строку в команды
- Как синтезировать речь
- И это все?
Распознавание и генерация речи в Android
 Последнее время большой интерес у пользователей вызывает возможность распознавания речи в телефонах. Огромная заслуга в популяризации этого направления принадлежит компании Aple, однако Google также располагает подобными технологиями. Собственно этой теме и будет посвящена данная статья. Мы разработаем приложение, которое будет распознавать речь пользователя и воспроизводить результат с помощью голосового движка «Text To Speech» (TTS). Отметим, что распознавание происходит на серверах Google, поэтому для работы приложению необходимо разрешить использовать коммуникационные возможности. Кроме того, распознавание речи не работает на эмуляторе. Тестировать программу необходимо на реальном устройстве.
Последнее время большой интерес у пользователей вызывает возможность распознавания речи в телефонах. Огромная заслуга в популяризации этого направления принадлежит компании Aple, однако Google также располагает подобными технологиями. Собственно этой теме и будет посвящена данная статья. Мы разработаем приложение, которое будет распознавать речь пользователя и воспроизводить результат с помощью голосового движка «Text To Speech» (TTS). Отметим, что распознавание происходит на серверах Google, поэтому для работы приложению необходимо разрешить использовать коммуникационные возможности. Кроме того, распознавание речи не работает на эмуляторе. Тестировать программу необходимо на реальном устройстве.
На самом деле работать с распознаванием и синтезом речи в Android очень просто. Все сложные вычисления скрыты от нас в довольно элегантную библиотеку с простым API. Вы сможете осилить этот урок, даже если имеете весьма поверхностные знания о программировании для Android.
Давайте создадим новый проект в Eclipse. Для наших нужд понадобится версия SDK не меньше 8. Опишем в общих чертах создаваемую программу. При запуске приложения пользователю будет показана кнопка, после нажатия на которую пользователю будет предложено надиктовать фразу. Затем будет осуществлено распознавание и будет показан список возможных вариантов. Поскольку технологии распознавания речи далеки от совершенства, программа не может ручаться за точность результата, именно поэтому будет предложено несколько вариантов. После того, как пользователь выберет один из них, будет запущен генератор голоса, который воспроизведет выбранную фразу.
Нам понадобится несколько текстовых строк, объявим их в фале «res/values/strings.xml»
Откроем файл «res/layout/main.xml» и зададим шаблон дизайна приложения. Для этого переключимся из графического в XML редактор и изменим содержимое файла
Добавим в Linear Layout элемент Text View
обратите внимание, TextView ссылается на строку intro, которую мы задали в файле strings.xml.
После Text View добавим кнопку
Пользователь будет нажимать эту кнопку, чтобы начать говорить. Кнопка имеет параметр id, через который ее можно вызвать из Java кода. После нажатия на кнопку пользователю показывается сообщение. Нам также понадобится TextView для вывода слов с предложениями
TextView будет использовать строковый ресурс. Нам также понадобится список для вариантов слов
ListView будет заполняться данными в процессе работы программы, поэтому для доступа к этому компоненту также требуется ID. Обратите также внимание на наличие ресурса drawable. Вы должны сохранить файл words_bg.xml в папке res
Ничего особенного. Вы можете настроить дизайн ListView по своему усмотрению. Нам осталось задать еще один элемент пользовательского интерфейса — шаблон для элемента ListView. Создайте новый файл res/layout/word.xml со следующим содержанием
Таким образом, каждый элемент списка представляет собой просто Text View.
Если Вы все сделали правильно, то при запуске должно получиться следующее
Программируем распознавание речи в Android
После того, как шаблон будущего приложения создан, можно перейти к кодированию. Откройте java файл главной Activity и добавьте в начало файла
Изменим немного декларацию главного класса
OnInitListener необходим для работы TTS движка. Внутри класса добавим объявления переменных перед методом onCreate
Внутри метода onCreate автоматически сгенерирован код, вызывающий метод родительского класса и устанавливающий главный контекст вывода.
Cоздадим переменные для работы с кнопкой и списком распознанных слов
Далее необходимо проверить поддерживается ли возможность распознавания голоса телефоном
Мы запрашиваем среду, поддерживается ли Recognizer Intent. Если поддерживается, мы говорим приложению, что нужно отслеживать щелчок пользователя по кнопке. Если интент не поддерживается, мы блокируем кнопку и выводим соответствующее сообщение пользователю.
Напишем код, обрабатывающий нажатие на кнопку. Внутри класса после метода OnCreate добавим метод OnClick.
Как видите, при нажатии на кнопку мы вызываем метод listenToSpeech().
Большая часть приведенного кода стандартна для программ, использующих распознавание голоса. Обратите внимание на параметр EXTRA_PROMPT. Он задает строку-приглашение для пользователя. Параметр EXTRA_MAX_RESULTS определяет максимальное число вариантов распознавания. В конце концов, мы вызываем startActivityForResult. Результат его работы будет передан в метод onActivityResult.
На следующем скриншоте показан экран в момент распознавания речи.
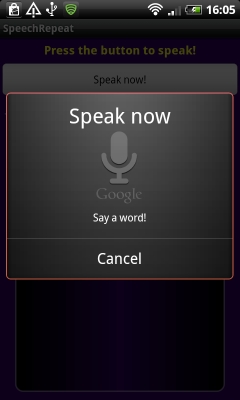
Определим метод onActivityResult
Обратите внимание, при проверке результата мы сравниваем переменную requestCode с константой VR_REQUEST, которую использовали ранее при вызове метода startActivityForResult. Таким образом, мы рассматриваем только результаты от нашего запроса. В метод возвращается 10 вариантов распознанных слов, которые мы записываем в список ArrayList. Этот список мы используем в ArrayAdapter компонента List View.
Если приложение справилось с задачей и смогло что-то распознать, вы увидите похожий н показанный на левом скриншоте результат. Если приложению не удалось распознать фразу, будет показано сообщение, как на правом скриншоте
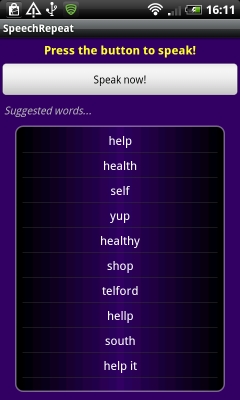
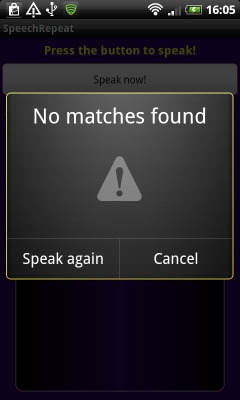
Вот, собственно и все. Распознавание голоса в Android — довольно простая задача. Мы вызываем интент RecognizerIntent с требуемыми нами параметрами. Результат возвращается в onActivityResult.
Генерация речи в Android
Перейдем ко второй части нашего приложения, связанного с генерацией речи. Мы хотим, чтобы телефон проговаривал фразу из списка результатов. Мы должны определить строку, на которую щелкнул пользователь. Вернемся к методу onCreate и добавим в конец этого метода код
Мы используем метод setOnItemClickListener чтобы установить отслеживание щелчков для каждой строки. Внутри нового объекта OnItemClickListener мы описали метод onItemClick, который вызывается в ответ на щелчок по строке списка. Выбранная строка передается, как View в этот метод. Поскольку при проектировании шаблона приложения мы указали, что наш список состоит из TextView, мы преобразуем полученное значение в объект TextView и достаем из него строковое значение. Мы записываем это слово в лог и показываем пользователю Toast сообщение.
Если Вас не интересует процесс генерации речи, Вы можете остановиться и протестировать приложение.
Для генерации речи необходимо настроить движок TTS. Добавим код в конец метода onCreate
Как и в случае распознавания, результат интента возвращается в метод onActivityResult. В этом методе перед строкой super.onActivityResult(requestCode, resultCode, data); добавьте
Таким образом, мы проверяем наличие TTS движка, и если он не установлен — предлагаем пользователю установить соответствующую программу.
Чтобы завершить настройку TTS, добавим метод onInit, который вызывается при успешной инициализации TTS.
Здесь мы устанавливаем язык генератора речи.
Для того, чтобы заставить движок проговорить строку, нужно вызвать метод repeatTTS.speak. Вернемся к методу onCreate. Внутри метода onItemClick после строки Toast.makeText(SpeechRepeatActivity.this, «You said: «+wordChosen, Toast.LENGTH_SHORT).show(); добавьте следующий код
Таким образом, одновременно с Toast сообщением пользователь услышит сгенерированную речь. Отметим еще раз, что эмулятор не поддерживает распознавание речи, поэтому тестировать программу необходимо на телефоне.
Источник
Распознавание голоса java android
В этом уроке мы научим свою программу слушать хозяина. Мы научимся использовать в Android приложении функцию speech to text, то есть преобразование голоса в текст, что будет происходить с использованием стандартных возможностей Android и Google через RecognizerIntent. Для успешной работы приложения нужно подключение к Интернет. Распознаватель речи будет запускаться при нажатии пользователя на кнопку, а произнесенные слова будут отображаться в отведенном для этого элементе TextView.
Создадим новый проект и начнем. Для начала оформим интерфейс приложения. Как уже только что упоминалось, оно будет иметь всего 2 элемента: кнопку Button и элемент TextView. Открываем файл activity_main.xml и добавляем туда эти элементы:
При нажатии на кнопку будет вызываться RecognizerIntent activity, которая будет производить распознавание голоса, входящего в устройство из микрофона, и преобразовывать его в текст. Для обработки полученных данных будет использоваться функция onActivityResult (), она используется всегда, если мы запускаем какое то другое activity и желаем получить из него назад (как ответ) некоторые данные.
По сути, вся работа в этом случае (и в подобных ему) выполняется в 2 основных шага:
— первый шаг — это выполнение activity на результат startActivityForResult, где мы задаем, какую activity хотим запустить и определяем подробности своего запроса;
— второй шаг — обработка функции onActivityResult (), которая проверяет оценку успешности результата запроса и обрабатывает полученные данные.
В результате своего запроса мы будем получать массив из слов и фраз, которые программе покажутся похожими на то, что пользователь промямлит при вызове действия ACTION_RECOGNIZE_SPEECH (говорить для распознавания и преобразования в текст), а далее эти слова мы отображаем в элементе TextView. Чтобы реализовать это все, открываем файл MainActivity.java и добавляем следующее:
Теперь запускаем приложение, нажимаем кнопку «Сказать слово» и рассказываем приложению обо всех своих бедах (простите за эти роскошные скриншоты):


Как видите, оно нас понимает.
Напомню также о уроке по функции чтения текста вслух Text To Speech.
Источник
Android Speech to Text Tutorial

In this article, we will learn how to implement speech to text functionality in android. To enable our app to use speech to text we have to use the SpeechRecognizer class.

Let’s see what is written in the official documentation:
This class provides access to the speech recognition service. This service allows access to the speech recognizer. Do not instantiate this class directly, instead, call SpeechRecognizer#createSpeechRecognizer(Context) . This class’s methods must be invoked only from the main application thread.
The implementation of this API is likely to stream audio to remote servers to perform speech recognition. As such this API is not intended to be used for continuous recognition, which would consume a significant amount of battery and bandwidth.
Let’s implement this to understand it better.
First of all, create a new Android Studio project and in the manifest file add the following user-permissions:
Now in the activity_main.xml file, we will add an EditText and an ImageView.I will not explain the layout file as I don’t want to waste anybody’s time who is here to learn the Speech to Text.You can see the code below.
Let’s dive into the MainActivity.java file.
First, we will check for the permissions:
If the permission is not granted then we will call the checkPermission method.
Now here comes the important part first which will initialize the SpeecRecognizer object and then create the intent for recognizing the speech.
As you can see we have added some extras let me explain what are they.
The constant ACTION_RECOGNIZE_SPEECH starts an activity that will prompt the user for speech and send it through a speech recognizer.
EXTRA_LANGUAGE_MODEL: Informs the recognizer which speech model to prefer when performing ACTION_RECOGNIZE_SPEECH.
LANGUAGE_MODEL_FREE_FORM: Use a language model based on free-form speech recognition.
EXTRA_LANGUAGE : Optional IETF language tag (as defined by BCP 47), for example, “en-US”.
Now we will set a speechRecognitionListener to our speechRecognizer object using the setRecognitionListener() method.
You can see after setting the listener we get several methods to implement. We will go the onResults method and add the following code
We get an ArrayList of String as a result and we use this ArrayList to update the UI (EditText here).
Build better voice apps. Get more articles & interviews from voice technology experts at voicetechpodcast.com
In the onBeginningOfSpeeh() method we will add the following code to tell the user that his voice is being recognized.
Now, lets set up the imageView. We will add a touchListener to the image view to know when the user has pressed the image.
When the user taps the imageView the listener starts listening and the imageView source image is also changed to update the user that his voice is being listened to.
You can find the full source code below:
Let’s run the app.
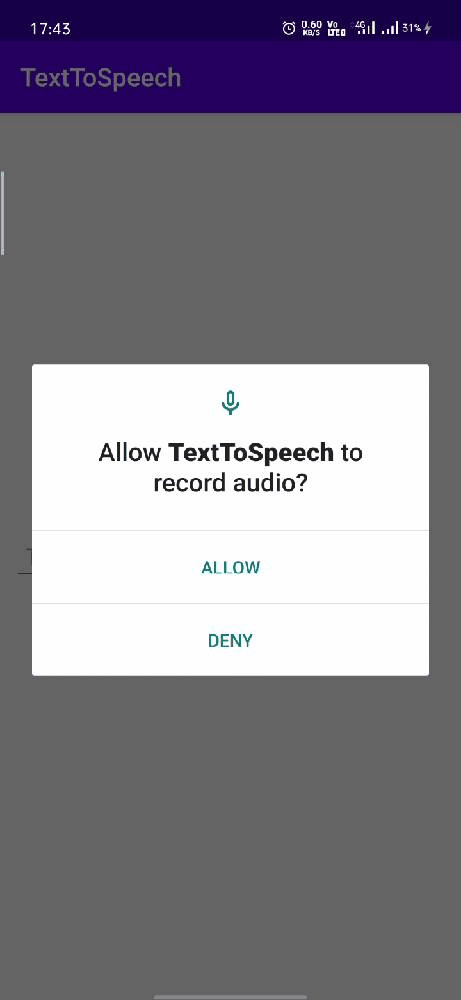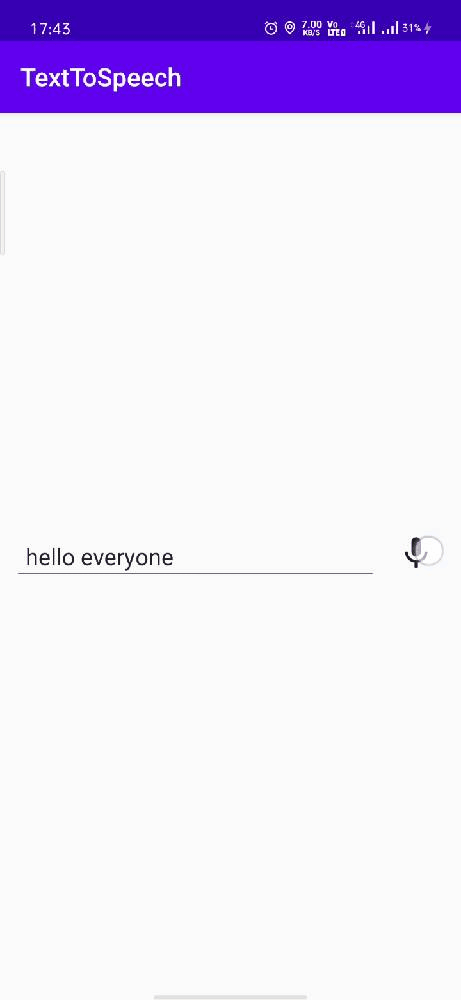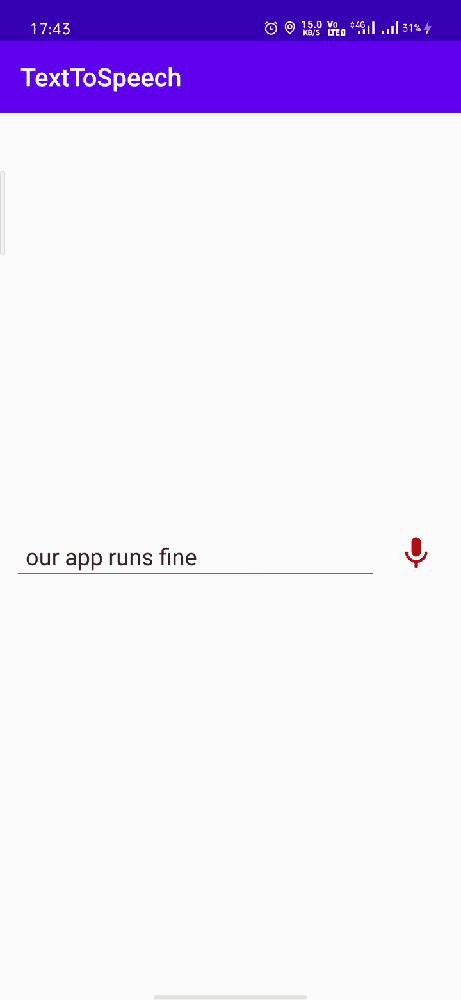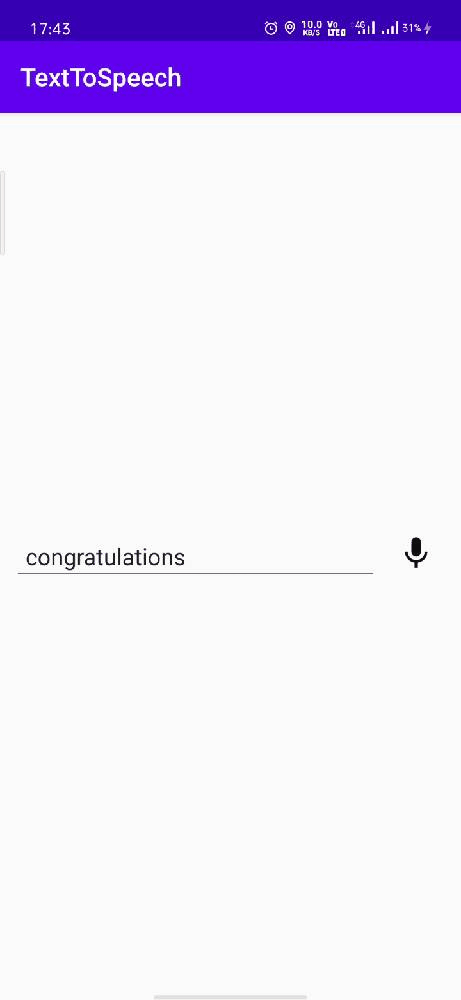
Now you are capable of adding a cool functionality to your app. What are you waiting for start coding…
You can get the full source code from my GitHub.
Источник
Сверхбыстрое распознавание речи без серверов на реальном примере
В этой статье я подробно расскажу и покажу, как правильно и быстро прикрутить распознавание русской речи на движке Pocketsphinx (для iOS порт OpenEars) на реальном Hello World примере управления домашней техникой.
Почему именно домашней техникой? Да потому что благодаря такому примеру можно оценить ту скорость и точность, которой можно добиться при использовании полностью локального распознавания речи без серверов типа Google ASR или Яндекс SpeechKit.
К статье я также прилагаю все исходники программы и саму сборку под Android.
С чего вдруг?
Наткнувшись недавно на статью о прикручивании Яндекс SpeechKit-а к iOS приложению, я задал вопрос автору, почему для своей программы он захотел использовать именно серверное распознавание речи (по моему мнению, это было излишним и приводило к некоторым проблемам). На что получил встречный вопрос о том, не мог бы я поподробней описать применение альтернативных способов для проектов, где нет необходимости распознавать что угодно, а словарь состоит из конечного набора слов. Да еще и с примером практического применения…
Зачем нам что-то еще кроме Яндекса и Google?
Так Android же умеет распознавать речь без интернета!
Да-да… Только на JellyBean. И только с полуметра, не более. И это распознавание — это та же диктовка, только с использованием гораздо меньшей модели. Так что управлять ею и настраивать ее мы тоже не можем. И что она вернет нам в следующий раз — неизвестно. Хотя для СМС-ок в самый раз!
Что будем делать?

Будем реализовывать голосовой пульт управления домашней техникой, который будет работать точно и быстро, с нескольких метров и даже на дешевом тормозном хламе очень недорогих Android смартфонах, планшетах и часах.
Логика будет простой, но очень практичной. Активируем микрофон и произносим одно или несколько названий устройств. Приложение их распознает и включает-выключает их в зависимости от текущего состояния. Либо получает от них состояние и произносит его приятным женским голосом. Например, текущая температура в комнате.
Микрофон будем активировать или голосом, или нажатием на иконку микрофона, или даже просто положив руку на экран. Экран в свою очередь может быть и полностью выключенным.
На видео показано, что получилось в итоге. Далее же речь пойдет о технической реализации с выдержками из реально работающего кода и немного теории.
Что такое Pocketsphinx

Pocketsphinx — это движок распознавания с открытым исходным кодом под Android. У него также имеется порт под iOS, WindowsPhone, и даже JavaScript.
Он позволит нам запустить распознавание речи прямо на устройстве и при этом настроить его именно под наши задачи. Также он предлагает функцию голосовой активации «из коробки» (см далее).
Мы сможем «скормить» движку распознавания русскую языковую модель (вы можете найти ее в исходниках) и грамматику пользовательских запросов. Это именно то, что будет распознавать наше приложение. Ничего другого оно распознать не сможет. А следовательно, практически никогда не выдаст что-то, чего мы не ожидаем.
Формат грамматики JSGF используется Pocketsphinx, как и многими другими подобными проектами. В нем можно с достаточной гибкостью описать те варианты фраз, которые будет произносить пользователь. В нашем случае грамматика будет строиться из названий устройств, которые есть в нашей сети, примерно так:
Pocketsphinx также может работать по статистической модели языка, что позволяет распознавать спонтанную речь, не описываемую контекстно-свободной грамматикой. Но для нашей задачи это как раз не нужно. Наша грамматика будет состоять только из названий устройств. После процесса распознавания Pocketsphinx вернет нам обычную строчку текста, где устройства будут идти один за другим.
Знак плюса обозначает, что пользователь может назвать не одно, а несколько устройств подряд.
Приложение получает список устройств от контроллера умного дома (см далее) и формирует такую грамматику в классе Grammar.
Транскрипции

Грамматика описывает то, что может говорить пользователь. Для того, чтобы Pocketsphinx знал, как он это будет произносить, необходимо для каждого слова из грамматики написать, как оно звучит в соответствующей языковой модели. То есть транскрипцию каждого слова. Это называется словарь.
Транскрипции описываются с помощью специального синтаксиса. Например:
В принципе, ничего сложного. Двойная гласная в транскрипции обозначает ударение. Двойная согласная — мягкую согласную, за которой идет гласная. Все возможные комбинации для всех звуков русского языка можно найти в самой языковой модели.
Понятно, что заранее описать все транскрипции в нашем приложении мы не можем, потому что мы не знаем заранее тех названий, которые пользователь даст своим устройствам. Поэтому мы будем гененрировать «на лету» такие транскрипции по некоторым правилам русской фонетики. Для этого можно реализовать вот такой класс PhonMapper, который сможет получать на вход строчку и генерировать для нее правильную транскрипцию.
Голосовая активация
Это возможность движка распознавания речи все время «слушать эфир» с целью реакции на заранее заданную фразу (или фразы). При этом все другие звуки и речь будут отбрасываться. Это не то же самое, что описать грамматику и просто включить микрофон. Приводить здесь теорию этой задачи и механику того, как это работает, я не буду. Скажу лишь только, что недавно программисты, работающие над Pocketsphinx, реализовали такую функцию, и теперь она доступна «из коробки» в API.
Одно стоит упомянуть обязательно. Для активационной фразы нужно не только указать транскрипцию, но и подобрать подходящее значение порога чувствительности. Слишком маленькое значение приведет к множеству ложных срабатываний (это когда вы не говорили активационную фразу, а система ее распознает). А слишком высокое — к невосприимчивости. Поэтому данная настройка имеет особую важность. Примерный диапазон значений — от 1e-1 до 1e-40 в зависимости от активационной фразы.
Запускаем распознование
Pocketsphinx предоставляет удобный API для конфигурирования и запуска процесса распознавания. Это классы SppechRecognizer и SpeechRecognizerSetup.
Вот как выглядит конфигурация и запуск распознавания:
Здесь мы сперва копируем все необходимые файлы на диск (Pocketpshinx требует наличия на диске аккустической модели, грамматики и словаря с транскрипциями). Затем конфигурируется сам движок распознавания. Указываются пути к файлам модели и словаря, а также некоторые параметры (порог чувствительности для активационной фразы). Далее конфигурируется путь к файлу с грамматикой, а также активационная фраза.
Как видно из этого кода, один движок конфигурируется сразу и для грамматики, и для распознавания активационной фразы. Зачем так делается? Для того, чтобы мы могли быстро переключаться между тем, что в данный момент нужно распознавать. Вот как выглядит запуск процесса распознавания активационной фразы:
А вот так — распозанвание речи по заданной грамматике:
Второй аргумент (необязательный) — количество миллисекунд, после которого распознавание будет автоматически завершаться, если никто ничего не говорит.
Как видите, можно использовать только один движок для решения обеих задач.
Как получить результат распознавания
Чтобы получить результат распознавания, нужно также указать слушателя событий, имплементирующего интерфейс RecognitionListener.
У него есть несколько методов, которые вызываются pocketsphinx-ом при наступлении одного из событий:
- onBeginningOfSpeech — движок услышал какой-то звук, может быть это речь (а может быть и нет)
- onEndOfSpeech — звук закончился
- onPartialResult — есть промежуточные результаты распознавания. Для активационной фразы это значит, что она сработала. Аргумент Hypothesis содержит данные о распознавании (строка и score)
- onResult — конечный результат распознавания. Этот метод будет вызыван после вызова метода stop у SpeechRecognizer. Аргумент Hypothesis содержит данные о распознавании (строка и score)
Реализуя тем или иным способом методы onPartialResult и onResult, можно изменять логику распознавания и получать окончательный результат. Вот как это сделано в случае с нашим приложением:
Когда мы получаем событие onEndOfSpeech, и если при этом мы распознаем команду для выполнения, то необходимо остановить распознавание, после чего сразу будет вызван onResult.
В onResult нужно проверить, что только что было распознано. Если это команда, то нужно запустить ее на выполнение и переключить движок на распознавание активационной фразы.
В onPartialResult нас интересует только распознавание активационной фразы. Если мы его обнаруживаем, то сразу запускаем процесс распознавания команды. Вот как он выглядит:
Здесь мы сперва играем небольшой сигнал для оповещения пользователя, что мы его услышали и готовы к его команде. На это время микрофон долже быть выключен. Поэтому мы запускаем распознавание после небольшого таймаута (чуть больше, чем длительность сигнала, чтобы не услышать его эха). Также запускается поток, который остановит распознавание принудительно, если пользователь говорит слишком долго. В данном случае это 3 секунды.
Как превратить распознанную строку в команды
Ну тут все уже специфично для конкретного приложения. В случае с нагим примером, мы просто вытаскиваем из строчки названия устройств, ищем по ним нужное устройство и либо меняем его состояние с помощью HTTP запроса на контроллер умного дома, либо сообщаем его текущее состояние (как в случае с термостатом). Эту логику можно увидеть в классе Controller.
Как синтезировать речь
Синтез речи — это операция, обратная распознаванию. Здесь наоборот — нужно превратить строку текста в речь, чтобы ее услышал пользователь.
В случае с термостатом мы должны заставить наше Android устройство произнести текущую температуру. С помощью API TextToSpeech это сделать довольно просто (спасибо гуглу за прекрасный женский TTS для русского языка):
Скажу наверное банальность, но перед процессом синтеза нужно обязательно отключить распознавание. На некоторых устройствах (например, все самсунги) вообще невозсожно одновременно и слушать микрофон, и что-то синтезировать.
Окончание синтеза речи (то есть окончание процесса говорения текста синтезатором) можно отследить в слушателе:
В нем мы просто проверяем, нет ли еще чего-то в очереди на синтез, и включаем распозанвание активационной фразы, если ничего больше нет.
И это все?
Да! Как видите, быстро и качественно распознать речь прямо на устройстве совсем несложно, благодаря наличию таких замечательных проектов, как Pocketsphinx. Он предоставляет очень удобный API, который можно использовать в решении задач, связанных с распознаванием голосовых команд.
В данном примере мы прикрутили распознавание к вполне кокрентной задаче — голосовому управлению устройствами умного дома. За счет локального распознавания мы добились очень высокой скорости работы и минимизировали ошибки.
Понятно, что тот же код можно использовать и для других задач, связанных с голосом. Это не обязательно должен быть именно умный дом.
Все исходники, а также саму сборку приложения вы можете найти в репозитории на GitHub.
Также на моем канале в YouTube вы можете увидеть некоторые другие реализации голосового управления, и не только системами умных домов.
Источник



