- BlindDroid
- Навигация
- Android and Samsung
- Категории
- Загрузка компонента для распознавания речи офлайн.
- 5 лучших приложений для превращения голоса в текст на Android
- Gboard
- Evernote
- Speechnotes
- Speechtexter
- Сверхбыстрое распознавание речи без серверов на реальном примере
- С чего вдруг?
- Зачем нам что-то еще кроме Яндекса и Google?
- Что будем делать?
- Что такое Pocketsphinx
- Транскрипции
- Голосовая активация
- Запускаем распознование
- Как получить результат распознавания
- Как превратить распознанную строку в команды
- Как синтезировать речь
- И это все?
BlindDroid
Навигация
Android and Samsung
- Октябрь (4)
- Август (2)
- Июль (7)
- Июнь (5)
- Май (5)
- Апрель (1)
- Март (2)
- Февраль (8)
- Январь (6)
Категории
Загрузка компонента для распознавания речи офлайн.
Чтобы распознавание речи работало офлайн, нужно на устройствах с версией Android 4.1 и выше, подгрузить русский голосовой офлайн пакет. Подчёркиваю, если версия Android ниже чем 4.1, то офлайн распознавание не было ещё Google предусмотрено, можете даже не стараться его искать.
Для загрузки компонента офлайн на ваше устройство, нужно пройти по пути:
- Для 4.1: Настройки тел\Язык и ввод\Голосовой поиск\Распознавание речи офлайн\Все,
- Для 4.3: Настройки тел\Моё устройство\Язык и ввод\Голосовой поиск\Распознавание речи офлайн\Все,
- Для 8.1: Настройки тел\Google\Поиск, Ассистент и голосовое управление\Голосовой поиск\Распознавание речи офлайн\Все,
В списке предлагаемых пакетов найти «русский (Россия)» и загрузить его. После этого действия, распознавание речи должно работать без подключения к интернету.
Внимание! Пути настроек были указаны на примере аппаратов Samsung, которые шли с версией ОС Android 4.1, 4.3, 8.1.
Ещё можно проверить настройку по пути:
- Для 4.1: Настройки тел\Язык и ввод\Распознавание голоса,
- Для 4.3: Настройки тел\Моё устройство\Язык и ввод\Распознавание голоса,
нужно чтобы там было отмечено «Google».
На некоторых устройствах иногда встречается так, что по указанному выше пути, вы можете не обнаружить раздел «Голосовой поиск». Связано это может быть с тем, что производители устройств не Предустановили сервис голосового поиска Google в операционную систему. Лечится это установкой приложения «Google поиск».
Если вдруг у кого-то, по какой либо причине не получается установить из play stor, тогда можно попробовать загрузить отсюда: Поиск Google (Google Search) — 4PDA.
Источник
5 лучших приложений для превращения голоса в текст на Android
Времена, когда для того, чтобы превратить свою устную речь в письменный текст, вам нужен был личный секретарь, уже давно прошли. У старого метода, безусловно, есть свои преимущества, но сегодня для преобразования речи в текст гораздо проще и дешевле будет воспользоваться своим самым обыкновенным смартфоном. В этом материале мы составили список лучших конвертеров аудио в текст для Android, так что вам будет намного проще подобрать какой-нибудь себе по душе.

Gboard
Конечно, мы не могли не включить фирменную клавиатуру Google в этот список. Возможно, вам даже не понадобится устанавливать на ваш телефон какие-либо дополнительное программы. На многих Android-устройствах клавиатура Google есть по умолчанию, а на те, где ее нет, Gboard можно загрузить из магазина Google Play.
Хотя приложение Gboard в первую очередь предназначено для физического ввода текста, оно также поддерживает транскрипцию речи в текст. Между прочим, эта функция в Gboard работает очень хорошо, так как задействует все мощности Google. Приложение также поддерживает множество языков и может быть загружено для использования офлайн и более быстрого голосового набора. Gboard также бесплатно и его должно быть более чем достаточно для ваших нужд. Это, безусловно, один из лучших конвертеров аудио в текст на Android.
Evernote
Вот еще одно приложение, возможности которого сложно переоценить. Evernote — одно из самых популярных приложений для создания заметок, которое, помимо прочего, поддерживает преобразование речи в текст. В этом приложении есть множество других функций и возможностей на все случаи жизни, поэтому всем, кто часто делает заметки, Evernote обязателен к ознакомлению. Базовые возможности Evernote бесплатны, но за остальные придётся платить 219 рублей в месяц или 1989 рублей в год.
Speechnotes
Разработчик Speechnotes утверждает, что это бесплатная альтернатива самым дорогим аудио-текстовым конвертерам на рынке. Speechnotes задействует для своей работы сервера Google, а поэтому распознаёт речь ничуть не хуже, чем тот же Gboard. Приложение умеет работать в режиме диктовки несколько часов подряд, а также позволяет отредактировать сгенерированный текст даже во время диктовки.
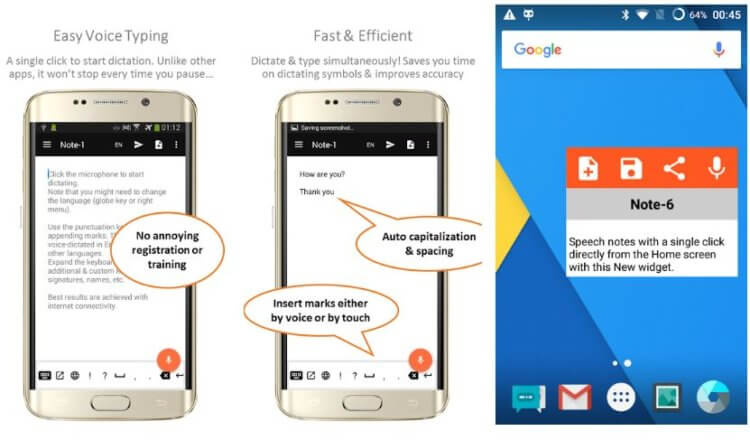
Speechnotes можно загрузить и использовать бесплатно, но в бесплатной версии есть реклама. Чтобы избавиться от рекламы и получить возможность кастомизировать интерфейс приложения, вам придётся купить Speechnotes за 499 рублей или оформить подписку за 69 рублей в месяц. Во втором случае предоставляется бесплатный тестовый период на 7 дней.
Speechtexter
Это приложение больше остальных зависит от подключения к сети, но оно также работает на основе данных от Google и прекрасно себя показывает, если все в порядке с вашим интернетом. Что делает Speechtexter особенным, так это его собственный словарь, в который можно занести какие-нибудь сокращения и расшифровки для них, а затем использовать во время диктовки. Speechtexter содержит рекламу, но благодаря этому оно абсолютно бесплатно.
Последнее в нашем списке, но не последнее по значимости, – T2S. Это приложение изначально предназначено для преобразования речи в текст. Оно также умеет экспортировать созданную голосовую заметку в аудиофайл и умеет читать вслух выделенный текст в браузере с любого сайта. T2S бесплатно, но содержит рекламу.
Мы надеемся, что хотя бы одно из этих приложений придётся вам по душе и поможет сэкономить в будущем много времени и сих, позволяя набирать текст голосом, а не руками.
Делитесь своим мнением в комментариях под этим материалом и в нашем Telegram-чате.

Новости, статьи и анонсы публикаций
Свободное общение и обсуждение материалов

На этой неделе Apple представила пакет услуг iCloud+ для подписчиков своего облачного сервиса. В его состав входят три инструмента безопасности: безлимит для видео с камер HomeKit, Private Relay для шифрования интернет-трафика и функция подмены адресов электронной почты. Несмотря на то что iCloud на Android работает вполне исправно в виде прогрессивного веб-приложения, получить доступ к iCloud+ можно только на iOS. Но если заменить Private Relay можно и обычным VPN, а видео с камер видеонаблюдения можно грузить на Яндекс.Диск, то вот где взять функцию, скрывающую настоящий адрес электронной почты?

YouTube уже давно перестал быть чем-то редким. Кроме того, что сейчас это самый посещаемый и популярный хостинг в мире, которые стал для многих средством заработка огромных денег, он является и источником информации. Огромная доля пользователей смотрит на YouTube хотя бы 1-2 ролика в день. При этом, у него появляются все новые инструменты для привлечения новых пользователей. Одним из них является не новый, но удобный инструмент ”Смотреть позже”. Часто просто нет времени смотреть все, что попадает в подборку. С этим инструментом можно просто отложить видео и посмотреть, когда будет время. Вот только там скапливается слишком много просмотренного мусора, который надо убирать. Расскажу, как это можно сделать.

Так уж получилось, что смартфон стал нашим неотъемлемым спутником. При этом он достаточно компактный для того, чтобы его потерять. Учитывая стоимость современных средств связи, это всегда неприятно. Но даже если вы не можете найти свой телефон, это не значит, что пора расстраиваться и готовиться к покупке нового. На самом деле проблема решается довольно легко и есть как минимум несколько путей для этого. Думаете, что эта статья пригодится тем, кто уже потерял телефон? А вот и нет. Тем, у кого все нормально, она окажется даже более полезной, так как им будет проще принять меры и подготовится к тому, что может случиться с каждым.
Источник
Сверхбыстрое распознавание речи без серверов на реальном примере
В этой статье я подробно расскажу и покажу, как правильно и быстро прикрутить распознавание русской речи на движке Pocketsphinx (для iOS порт OpenEars) на реальном Hello World примере управления домашней техникой.
Почему именно домашней техникой? Да потому что благодаря такому примеру можно оценить ту скорость и точность, которой можно добиться при использовании полностью локального распознавания речи без серверов типа Google ASR или Яндекс SpeechKit.
К статье я также прилагаю все исходники программы и саму сборку под Android.
С чего вдруг?
Наткнувшись недавно на статью о прикручивании Яндекс SpeechKit-а к iOS приложению, я задал вопрос автору, почему для своей программы он захотел использовать именно серверное распознавание речи (по моему мнению, это было излишним и приводило к некоторым проблемам). На что получил встречный вопрос о том, не мог бы я поподробней описать применение альтернативных способов для проектов, где нет необходимости распознавать что угодно, а словарь состоит из конечного набора слов. Да еще и с примером практического применения…
Зачем нам что-то еще кроме Яндекса и Google?
Так Android же умеет распознавать речь без интернета!
Да-да… Только на JellyBean. И только с полуметра, не более. И это распознавание — это та же диктовка, только с использованием гораздо меньшей модели. Так что управлять ею и настраивать ее мы тоже не можем. И что она вернет нам в следующий раз — неизвестно. Хотя для СМС-ок в самый раз!
Что будем делать?

Будем реализовывать голосовой пульт управления домашней техникой, который будет работать точно и быстро, с нескольких метров и даже на дешевом тормозном хламе очень недорогих Android смартфонах, планшетах и часах.
Логика будет простой, но очень практичной. Активируем микрофон и произносим одно или несколько названий устройств. Приложение их распознает и включает-выключает их в зависимости от текущего состояния. Либо получает от них состояние и произносит его приятным женским голосом. Например, текущая температура в комнате.
Микрофон будем активировать или голосом, или нажатием на иконку микрофона, или даже просто положив руку на экран. Экран в свою очередь может быть и полностью выключенным.
На видео показано, что получилось в итоге. Далее же речь пойдет о технической реализации с выдержками из реально работающего кода и немного теории.
Что такое Pocketsphinx

Pocketsphinx — это движок распознавания с открытым исходным кодом под Android. У него также имеется порт под iOS, WindowsPhone, и даже JavaScript.
Он позволит нам запустить распознавание речи прямо на устройстве и при этом настроить его именно под наши задачи. Также он предлагает функцию голосовой активации «из коробки» (см далее).
Мы сможем «скормить» движку распознавания русскую языковую модель (вы можете найти ее в исходниках) и грамматику пользовательских запросов. Это именно то, что будет распознавать наше приложение. Ничего другого оно распознать не сможет. А следовательно, практически никогда не выдаст что-то, чего мы не ожидаем.
Формат грамматики JSGF используется Pocketsphinx, как и многими другими подобными проектами. В нем можно с достаточной гибкостью описать те варианты фраз, которые будет произносить пользователь. В нашем случае грамматика будет строиться из названий устройств, которые есть в нашей сети, примерно так:
Pocketsphinx также может работать по статистической модели языка, что позволяет распознавать спонтанную речь, не описываемую контекстно-свободной грамматикой. Но для нашей задачи это как раз не нужно. Наша грамматика будет состоять только из названий устройств. После процесса распознавания Pocketsphinx вернет нам обычную строчку текста, где устройства будут идти один за другим.
Знак плюса обозначает, что пользователь может назвать не одно, а несколько устройств подряд.
Приложение получает список устройств от контроллера умного дома (см далее) и формирует такую грамматику в классе Grammar.
Транскрипции

Грамматика описывает то, что может говорить пользователь. Для того, чтобы Pocketsphinx знал, как он это будет произносить, необходимо для каждого слова из грамматики написать, как оно звучит в соответствующей языковой модели. То есть транскрипцию каждого слова. Это называется словарь.
Транскрипции описываются с помощью специального синтаксиса. Например:
В принципе, ничего сложного. Двойная гласная в транскрипции обозначает ударение. Двойная согласная — мягкую согласную, за которой идет гласная. Все возможные комбинации для всех звуков русского языка можно найти в самой языковой модели.
Понятно, что заранее описать все транскрипции в нашем приложении мы не можем, потому что мы не знаем заранее тех названий, которые пользователь даст своим устройствам. Поэтому мы будем гененрировать «на лету» такие транскрипции по некоторым правилам русской фонетики. Для этого можно реализовать вот такой класс PhonMapper, который сможет получать на вход строчку и генерировать для нее правильную транскрипцию.
Голосовая активация
Это возможность движка распознавания речи все время «слушать эфир» с целью реакции на заранее заданную фразу (или фразы). При этом все другие звуки и речь будут отбрасываться. Это не то же самое, что описать грамматику и просто включить микрофон. Приводить здесь теорию этой задачи и механику того, как это работает, я не буду. Скажу лишь только, что недавно программисты, работающие над Pocketsphinx, реализовали такую функцию, и теперь она доступна «из коробки» в API.
Одно стоит упомянуть обязательно. Для активационной фразы нужно не только указать транскрипцию, но и подобрать подходящее значение порога чувствительности. Слишком маленькое значение приведет к множеству ложных срабатываний (это когда вы не говорили активационную фразу, а система ее распознает). А слишком высокое — к невосприимчивости. Поэтому данная настройка имеет особую важность. Примерный диапазон значений — от 1e-1 до 1e-40 в зависимости от активационной фразы.
Запускаем распознование
Pocketsphinx предоставляет удобный API для конфигурирования и запуска процесса распознавания. Это классы SppechRecognizer и SpeechRecognizerSetup.
Вот как выглядит конфигурация и запуск распознавания:
Здесь мы сперва копируем все необходимые файлы на диск (Pocketpshinx требует наличия на диске аккустической модели, грамматики и словаря с транскрипциями). Затем конфигурируется сам движок распознавания. Указываются пути к файлам модели и словаря, а также некоторые параметры (порог чувствительности для активационной фразы). Далее конфигурируется путь к файлу с грамматикой, а также активационная фраза.
Как видно из этого кода, один движок конфигурируется сразу и для грамматики, и для распознавания активационной фразы. Зачем так делается? Для того, чтобы мы могли быстро переключаться между тем, что в данный момент нужно распознавать. Вот как выглядит запуск процесса распознавания активационной фразы:
А вот так — распозанвание речи по заданной грамматике:
Второй аргумент (необязательный) — количество миллисекунд, после которого распознавание будет автоматически завершаться, если никто ничего не говорит.
Как видите, можно использовать только один движок для решения обеих задач.
Как получить результат распознавания
Чтобы получить результат распознавания, нужно также указать слушателя событий, имплементирующего интерфейс RecognitionListener.
У него есть несколько методов, которые вызываются pocketsphinx-ом при наступлении одного из событий:
- onBeginningOfSpeech — движок услышал какой-то звук, может быть это речь (а может быть и нет)
- onEndOfSpeech — звук закончился
- onPartialResult — есть промежуточные результаты распознавания. Для активационной фразы это значит, что она сработала. Аргумент Hypothesis содержит данные о распознавании (строка и score)
- onResult — конечный результат распознавания. Этот метод будет вызыван после вызова метода stop у SpeechRecognizer. Аргумент Hypothesis содержит данные о распознавании (строка и score)
Реализуя тем или иным способом методы onPartialResult и onResult, можно изменять логику распознавания и получать окончательный результат. Вот как это сделано в случае с нашим приложением:
Когда мы получаем событие onEndOfSpeech, и если при этом мы распознаем команду для выполнения, то необходимо остановить распознавание, после чего сразу будет вызван onResult.
В onResult нужно проверить, что только что было распознано. Если это команда, то нужно запустить ее на выполнение и переключить движок на распознавание активационной фразы.
В onPartialResult нас интересует только распознавание активационной фразы. Если мы его обнаруживаем, то сразу запускаем процесс распознавания команды. Вот как он выглядит:
Здесь мы сперва играем небольшой сигнал для оповещения пользователя, что мы его услышали и готовы к его команде. На это время микрофон долже быть выключен. Поэтому мы запускаем распознавание после небольшого таймаута (чуть больше, чем длительность сигнала, чтобы не услышать его эха). Также запускается поток, который остановит распознавание принудительно, если пользователь говорит слишком долго. В данном случае это 3 секунды.
Как превратить распознанную строку в команды
Ну тут все уже специфично для конкретного приложения. В случае с нагим примером, мы просто вытаскиваем из строчки названия устройств, ищем по ним нужное устройство и либо меняем его состояние с помощью HTTP запроса на контроллер умного дома, либо сообщаем его текущее состояние (как в случае с термостатом). Эту логику можно увидеть в классе Controller.
Как синтезировать речь
Синтез речи — это операция, обратная распознаванию. Здесь наоборот — нужно превратить строку текста в речь, чтобы ее услышал пользователь.
В случае с термостатом мы должны заставить наше Android устройство произнести текущую температуру. С помощью API TextToSpeech это сделать довольно просто (спасибо гуглу за прекрасный женский TTS для русского языка):
Скажу наверное банальность, но перед процессом синтеза нужно обязательно отключить распознавание. На некоторых устройствах (например, все самсунги) вообще невозсожно одновременно и слушать микрофон, и что-то синтезировать.
Окончание синтеза речи (то есть окончание процесса говорения текста синтезатором) можно отследить в слушателе:
В нем мы просто проверяем, нет ли еще чего-то в очереди на синтез, и включаем распозанвание активационной фразы, если ничего больше нет.
И это все?
Да! Как видите, быстро и качественно распознать речь прямо на устройстве совсем несложно, благодаря наличию таких замечательных проектов, как Pocketsphinx. Он предоставляет очень удобный API, который можно использовать в решении задач, связанных с распознаванием голосовых команд.
В данном примере мы прикрутили распознавание к вполне кокрентной задаче — голосовому управлению устройствами умного дома. За счет локального распознавания мы добились очень высокой скорости работы и минимизировали ошибки.
Понятно, что тот же код можно использовать и для других задач, связанных с голосом. Это не обязательно должен быть именно умный дом.
Все исходники, а также саму сборку приложения вы можете найти в репозитории на GitHub.
Также на моем канале в YouTube вы можете увидеть некоторые другие реализации голосового управления, и не только системами умных домов.
Источник



