- Регулярные выражения
- Регулярные выражения для android
- split
- Соответствие строки. matches
- Класс Pattern
- Класс Matcher
- Замена в строке
- Разделение строки на лексемы
- Java RegEx: использование регулярных выражений на практике
- Авторизуйтесь
- Java RegEx: использование регулярных выражений на практике
- Основы регулярных выражений
- Определение
- Синтаксис RegEx
- Квантификаторы
- Обработка строк в Java. Часть II: Pattern, Matcher
- Вступление
- Регулярные выражения
- Механизм
- Подход к обработке
- Реализация
- Pattern
- Matcher и MatchResult
Регулярные выражения
Пакет java.util.regex поддерживает обработку регулярных выражений (regular expression).
Регулярные выражения используются некоторыми текстовыми редакторами и утилитами для поиска и подстановки текста. Например, при помощи регулярных выражений можно задать шаблоны, позволяющие:
найти все последовательности символов «кот» в любом контексте, как то: «кот», «котлета», «терракотовый»;
найти отдельно стоящее слово «кот» и заменить его на «кошка»;
найти слово «кот», которому предшествует слово «персидский» или «чеширский»;
убрать из текста все предложения, в которых упоминается слово кот или кошка.
Последнее предложение мне не нравится, кто-нибудь может отредактировать эту страницу?
В Java могут использоваться нестандартные приёмы использования регулярных выражений по синтаксису. Например, во многих языках выражение \\ означает, что ищется символ обратного слеша, который идёт за специальным мета-символом регулярного выражения. В Java придётся использовать для этой цели \\\\. Но таких различий немного.
Пакет содержит два класса — Pattern и Matcher, которые работают вместе. Класс Patern применяется для задания регулярного выражения. Класс Matcher сопоставляет шаблон с последовательностью символов.
Регулярное выражение состоит из обычных символов, наборов символов и групповых символов. Обычные символы используются как есть. Если в шаблоне указать символы «кот», то эти символы и будут искаться в строке.
Символы новой строки, табуляции и др. определяются при помощи стандартных управляющих последовательностей, которые начинаются с обратного слеша (\). Например, символ новой строки можно задать как \n.
Наборы символов заключаются в квадратные скобки. Например, [cat] совпадает с символами c, a, t. Если поставить символ ^ перед набором символов — [^cat], то ищутся совпадения всех символов, кроме c, a, t.
Чтобы задать диапазон символов, используется дефис. Например, диапазон от 1 до 9 можно задать как 8.
Символ точки является групповым символом, который совпадает с любым символом вообще.
Также можно задать, сколько раз совпадает выражение.
- + — совпадает один или более раз
- * — совпадает нуль или более раз
- ? — совпадает нуль или один раз
| Конструкция Regex | Что считается совпадением |
|---|---|
| . | Любой символ |
| ? | Ноль (0) или одно (1)повторение предшествующего |
| * | Ноль (0) или более повторений предшествующего |
| + | Одно (1) или более повторений предшествующего |
| [] | Диапазон символов или цифр |
| ^ | Отрицание последующего (то есть, «не что-то«) |
| \d | Любая цифра (иначе, 8 ) |
| \D | Любой нецифровой символ (иначе, [^0-9] ) |
| \s | Любой символ-разделитель (иначе, [\n\t\f\r] ) |
| \S | Любой символ, отличный от разделителей (иначе, [^\n\t\f\r] ) |
| \w | Любая буква или цифра (иначе, [A-Za-Z_0-9] ) |
| \W | Любой знак, отличный от буквы или цифры (иначе, [^\w] ) |
Например, выражение -?\\d+ будет искать число, у которого может быть минус (а может и нет).
Выражение c.t позволит найти слова cat, cot, но не cart.
Регулярные выражения встречаются в методах класса String.
Первые два выражения подходят под составленное выражение — либо число с минусом, либо число без знака. Со знаком плюс число не проходит проверку. Чтобы и этот вариант проходил, нужно видоизменить выражение (четвёртый вариант).
Нужно включить условие «может начинаться с + или -» с помощью вертикальной черты | (ИЛИ). Круглые скобки используются для группировки. Знак вопроса позволяет указать, что допустимо отсутствие знака. Знак плюса экранируется, так как является мета-символом.
Если вы зададите неверное выражение, то будет создано исключение PatternSyntaxException.
Источник
Регулярные выражения для android

Регулярные выражения представляют мощный инструмент для обработки строк. Регулярные выражения позволяют задать шаблон, которому должна соответствовать строка или подстрока.
Некоторые методы класса String принимают регулярные выражения и используют их для выполнения операций над строками.
split
Для разделения строки на подстроки применяется метод split() . В качестве параметра он может принимать регулярное выражение, которое представляет критерий разделения строки.
Например, разделим предложение на слова:
Для разделения применяется регулярное выражение «\\s*(\\s|,|!|\\.)\\s*». Подвыражние «\\s» по сути представляет пробел. Звездочка указывает, что символ может присутствовать от 0 до бесконечного количества раз. То есть добавляем звездочку и мы получаем неопределенное количество идущих подряд пробелов — «\\s*» (то есть неважно, сколько пробелов между словами). Причем пробелы может вообще не быть. В скобках указывает группа выражений, которая может идти после неопределенного количества пробелов. Группа позволяет нам определить набо значений через вертикальную черту, и подстрока должна соответствовать одному из этих значений. То есть в группе «\\s|,|!|\\.» подстрока может соответствовать пробелу, запятой, восклицательному знаку или точке. Причем поскольку точка представляет специальную последовательность, то, чтобы указать, что мы имеем в виду имеено знак точки, а не специальную последовательность, перед точкой ставим слеши.
Соответствие строки. matches
Еще один метод класса String — matches() принимает регулярное выражение и возвращает true, если строка соответствует этому выражению. Иначе возвращает false.
Например, проверим, соответствует ли строка номеру телефона:
В данном случае в регулярном выражение сначала определяется группа «(\\+*)». То есть вначале может идти знак плюса, но также он может отсутствовать. Далее смотрим, соответствуют ли последующие 11 символов цифрам. Выражение «\\d» представляет цифровой символ, а число в фигурных скобках — <11>— сколько раз данный тип символов должен повторяться. То есть мы ищем строку, где вначале может идти знак плюс (или он может отсутствовать), а потом идет 11 цифровых символов.
Класс Pattern
Большая часть функциональности по работе с регулярными выражениями в Java сосредоточена в пакете java.util.regex .
Само регулярное выражение представляет шаблон для поиска совпадений в строке. Для задания подобного шаблона и поиска подстрок в строке, которые удовлетворяют данному шаблону, в Java определены классы Pattern и Matcher .
Для простого поиска соответствий в классе Pattern определен статический метод boolean matches(String pattern, CharSequence input) . Данный метод возвращает true, если последовательность символов input полностью соответствует шаблону строки pattern:
Но, как правило, для поиска соответствий применяется другой способ — использование класса Matcher.
Класс Matcher
Рассмотрим основные методы класса Matcher:
boolean matches() : возвращает true, если вся строка совпадает с шаблоном
boolean find() : возвращает true, если в строке есть подстрока, которая совпадает с шаблоном, и переходит к этой подстроке
String group() : возвращает подстроку, которая совпала с шаблоном в результате вызова метода find. Если совпадение отсутствует, то метод генерирует исключение IllegalStateException .
int start() : возвращает индекс текущего совпадения
int end() : возвращает индекс следующего совпадения после текущего
String replaceAll(String str) : заменяет все найденные совпадения подстрокой str и возвращает измененную строку с учетом замен
Используем класс Matcher. Для этого вначале надо создать объект Pattern с помощью статического метода compile() , который позволяет установить шаблон:
В качестве шаблона выступает строка «Hello». Метод compile() возвращает объект Pattern, который мы затем можем использовать в программе.
В классе Pattern также определен метод matcher(String input) , который в качестве параметра принимает строку, где надо проводить поиск, и возвращает объект Matcher :
Затем у объекта Matcher вызывается метод matches() для поиска соответствий шаблону в тексте:
Рассмотрим более функциональный пример с нахождением не полного соответствия, а отдельных совпадений в строке:
Допустим, мы хотим найти в строке все вхождения слова Java. В исходной строке это три слова: «Java», «JavaScript» и «JavaSE». Для этого применим шаблон «Java(\\w*)». Данный шаблон использует синтаксис регулярных выражений. Слово «Java» в начале говорит о том, что все совпадения в строке должны начинаться на Java. Выражение (\\w*) означает, что после «Java» в совпадении может находиться любое количество алфавитно-цифровых символов. Выражение \w означает алфавитно-цифровой символ, а звездочка после выражения указывает на неопределенное их количество — их может быть один, два, три или вообще не быть. И чтобы java не рассматривала \w как эскейп-последовательность, как \n, то выражение экранируется еще одним слешем.
Далее применяется метод find() класса Matcher, который позволяет переходить к следующему совпадению в строке. То есть первый вызов этого метода найдет первое совпадение в строке, второй вызов найдет второе совпадение и т.д. То есть с помощью цикла while(matcher.find()) мы можем пройтись по всем совпадениям. Каждое совпадение мы можем получить с помощью метода matcher.group() . В итоге программа выдаст следующий результат:
Замена в строке
Теперь сделаем замену всех совпадений с помощью метода replaceAll() :
Также надо отметить, что в классе String также имеется метод replaceAll() с подобным действием:
Разделение строки на лексемы
С помощью метода String[] split(CharSequence input) класса Pattern можно разделить строку на массив подстрок по определенному разделителю. Например, мы хотим выделить из строки отдельные слова:
И консоль выведет набор слов:
При этом все символы-разделители удаляются. Однако, данный способ разбивки не идеален: у нас остаются некоторые пробелы, которые расцениваются как лексемы, а не как разделители. Для более точной и изощренной разбивки нам следует применять элементы регулярных выражений. Так, заменим шаблон на следующий:
Теперь у нас останутся только слова:
Далее мы подробнее рассмотрим синтаксис регулярных выражений и из каких элементов мы можем создавать шаблоны.
Источник
Java RegEx: использование регулярных выражений на практике
Авторизуйтесь
Java RegEx: использование регулярных выражений на практике
Рассмотрим регулярные выражения в Java, затронув синтаксис и наиболее популярные конструкции, а также продемонстрируем работу RegEx на примерах.
Основы регулярных выражений
Мы подробно разобрали базис в статье Регулярные выражения для новичков, поэтому здесь пробежимся по основам лишь вскользь.
Определение
Регулярные выражения представляют собой формальный язык поиска и редактирования подстрок в тексте. Допустим, нужно проверить на валидность e-mail адрес. Это проверка на наличие имени адреса, символа @ , домена, точки после него и доменной зоны.
Вот самая простая регулярка для такой проверки:
В коде регулярные выражения обычно обозначается как regex, regexp или RE.
Синтаксис RegEx
Символы могут быть буквами, цифрами и метасимволами, которые задают шаблон:

Есть и другие конструкции, с помощью которых можно сокращать регулярки:
- \d — соответствует любой одной цифре и заменяет собой выражение 4;
- \D — исключает все цифры и заменяет [^0-9];
- \w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- \W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- \s — поиск символов пробела;
- \S — поиск любого непробельного символа.
Квантификаторы
Это специальные ограничители, с помощью которых определяется частота появления элемента — символа, группы символов, etc:
- ? — делает символ необязательным, означает 0 или 1 . То же самое, что и <0,1>.
- * — 0 или более, <0,>.
- + — 1 или более, <1,>.
— означает число в фигурных скобках. - *? — символ ? после квантификатора делает его ленивым, чтобы найти наименьшее количество совпадений.
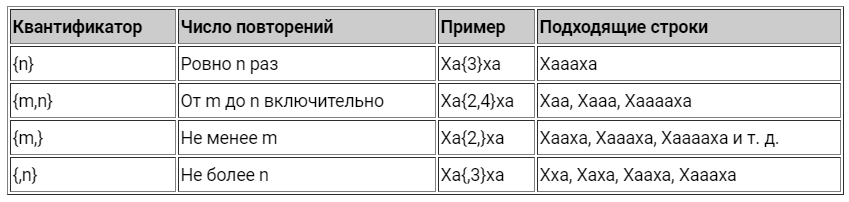
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Также квантификаторов есть три режима:
По умолчанию квантификатор всегда работает в жадном режиме. Подробнее о квантификаторах в Java вы можете почитать здесь.
Источник
Обработка строк в Java. Часть II: Pattern, Matcher
Вступление
Что Вы знаете о обработке строк в Java? Как много этих знаний и насколько они углублены и актуальны? Давайте попробуем вместе со мной разобрать все вопросы, связанные с этой важной, фундаментальной и часто используемой частью языка. Наш маленький гайд будет разбит на две публикации:
- String, StringBuffer, StringBuilder (реализация строк)
- Pattern, Matcher (регулярные выражения)
Сегодня поговорим о регулярных выражениях в Java, рассмотрим их механизм и подход к обработке. Также рассмотрим функциональные возможности пакета java.util.regex.
Регулярные выражения

Большинство современных языков программирования поддерживают РВ, Java не является исключением.
Механизм
Существует две базовые технологии, на основе которых строятся механизмы РВ:
- Недетерминированный конечный автомат (НКА) — «механизм, управляемый регулярным выражением»
- Детерминированный конечный автомат (ДКА) — «механизм, управляемый текстом»
НКА — механизм, в котором управление внутри РВ передается от компонента к компоненту. НКА просматривает РВ по одному компоненту и проверяет, совпадает ли компонент с текстом. Если совпадает — проверятся следующий компонент. Процедура повторяется до тех пор, пока не будет найдено совпадение для всех компонентов РВ (пока не получим общее совпадение).
ДКА — механизм, который анализирует строку и следит за всеми «возможными совпадениями». Его работа зависит от каждого просканированного символа текста (то есть ДКА «управляется текстом»). Даний механизм сканирует символ текста, обновляет «потенциальное совпадение» и резервирует его. Если следующий символ аннулирует «потенциальное совпадение», то ДКА возвращается к резерву. Нет резерва — нет совпадений.
Логично, что ДКА должен работать быстрее чем НКА (ДКА проверяет каждый символ текста не более одного раза, НКА — сколько угодно раз пока не закончит разбор РВ). Но НКА предоставляет возможность определять ход дальнейших событий. Мы можем в значительной степени управлять процессом за счет правильного написания РВ.
Регулярные выражения в Java используют механизм НКА.
Эти виды конечных автоматов более детально рассмотрены в статье «Регулярные выражения изнутри».
Подход к обработке
В языках программирования существует три подхода к обработке РВ:
- интегрированный
- процедурный
- объектно-ориентированный
Интегрированный подход — встраивание РВ в низкоуровневый синтаксис языка. Этот подход скрывает всю механику, настройку и, как следствие, упрощает работу программиста.
Функциональность РВ при процедурном и объектно-ориентированном подходе обеспечивают функции и методы соответственно. Вместо специальных конструкций языка, функции и методы принимают в качестве параметров строки и интерпретируют их как РВ.
Для обработки регулярных выражений в Java используют объектно-ориентированный подход.
Реализация
Pattern
Класс Pattern представляет собой скомпилированное представление РВ. Класс не имеет публичных конструкторов, поэтому для создания объекта данного класса необходимо вызвать статический метод compile и передать в качестве первого аргумента строку с РВ:
Также в качестве второго параметра в метод compile можно передать флаг в виде статической константы класса Pattern, например:
Таблица всех доступных констант и эквивалентных им флагов:
| № | Constant | Equivalent Embedded Flag Expression |
|---|---|---|
| 1 | Pattern.CANON_EQ | — |
| 2 | Pattern.CASE_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | Pattern.MULTILINE | (?m) |
| 5 | Pattern.DOTALL | (?s) |
| 6 | Pattern.LITERAL | — |
| 7 | Pattern.UNICODE_CASE | (?u) |
| 8 | Pattern.UNIX_LINES | (?d) |
Иногда нам необходимо просто проверить есть ли в строке подстрока, что удовлетворяет заданному РВ. Для этого используют статический метод matches, например:
Также иногда возникает необходимость разбить строку на массив подстрок используя РВ. В этом нам поможет метод split:
Matcher и MatchResult
Matcher — класс, который представляет строку, реализует механизм согласования (matching) с РВ и хранит результаты этого согласования (используя реализацию методов интерфейса MatchResult). Не имеет публичных конструкторов, поэтому для создания объекта этого класса нужно использовать метод matcher класса Pattern:
Но результатов у нас еще нет. Чтобы их получить нужно воспользоваться методом find. Можно использовать matches — этот метод вернет true только тогда, когда вся строка соответствует заданному РВ, в отличии от find, который пытается найти подстроку, которая удовлетворяет РВ. Для более детальной информации о результатах согласования можно использовать реализацию методов интерфейса MatchResult, например:
Источник



