- Управление голосом в приложениях на Android
- Сверхбыстрое распознавание речи без серверов на реальном примере
- С чего вдруг?
- Зачем нам что-то еще кроме Яндекса и Google?
- Что будем делать?
- Что такое Pocketsphinx
- Транскрипции
- Голосовая активация
- Запускаем распознование
- Как получить результат распознавания
- Как превратить распознанную строку в команды
- Как синтезировать речь
- И это все?
Управление голосом в приложениях на Android
Началось все с того, что я посмотрел неплохой обзор (сравнение) Siri и Google Now. Кто из них лучше, спорить не буду, однако у меня лично планшет на Андроиде. Я подумал, а что если написать калькулятор полностью на голосовом управлении (удобно ли будет?). Но для начала пришлось немного разобраться с самим голосовым управление, точнее говоря с голосовым вводом (управления еще добиться надо). Кроме того, я только что скачал Android Studio, и мне не терпелось скорей опробовать ее на практике (ну на минипроекте). Что ж, начнем.
Кидаем на активность ListView и Button. В ЛистВью будем сохранять сами команды, точнее варианты одной команды, а кнопка будет вежливо спрашивать, чего мы желаем. Да, программа логикой не будет обладать, с ее помощью просто посмотрим саму реализацию.

Добавим так же в Манифест одно разрешение
И все, теперь можно переходить непосредственно к программированию. «Находим необходимые компоненты»:
Прописываем обработчик нажатия для кнопки, который вызовет метод startSpeak(), о котором мы поговорим далее:
Ну наконец закончилась «вода». Начинаем «говорить»:
Пришло время дать волю фантазии и решить какие команды использовать. Сам я сначала хотел показать на примере тетрисного танчика: диктовали бы ему «up», «down», «left», «fire» и так далее, но это сложно оставляю вам. Я же отдавал команды по смене цвета кнопки, выходу из приложения, открытию страниц в браузере, запуску карт и перезагрузке устройства. Что касается последнего, reboot, это команда будет работать, как я понял, только на рутованных устройствах. На телефоне у меня есть права СП и все хорошо работает, а вот на планшете, он просто игнорирует эту команду. В записи команд нет ничего сложного, думаю комментариев будет достаточно:
Так выглядит окно записи команд:
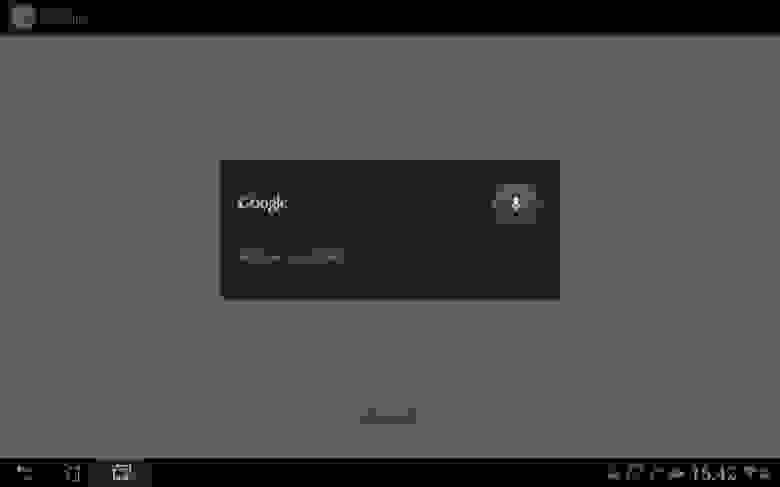
Скажем с красивым английским акцентом «maps». Вызвали Google Maps:
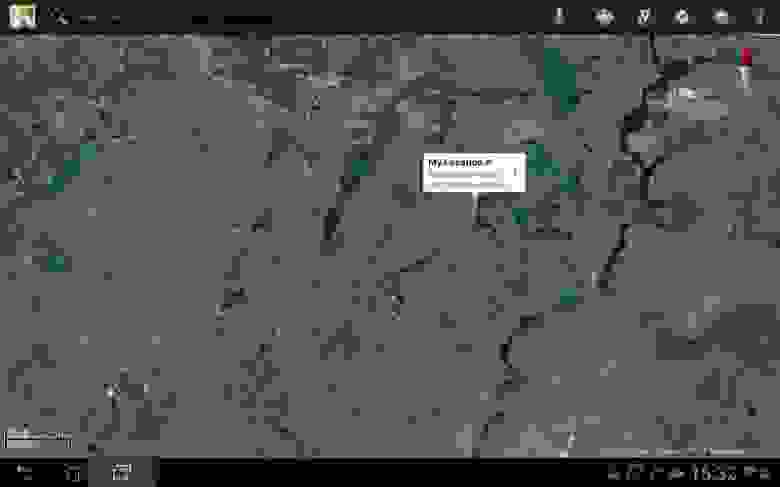
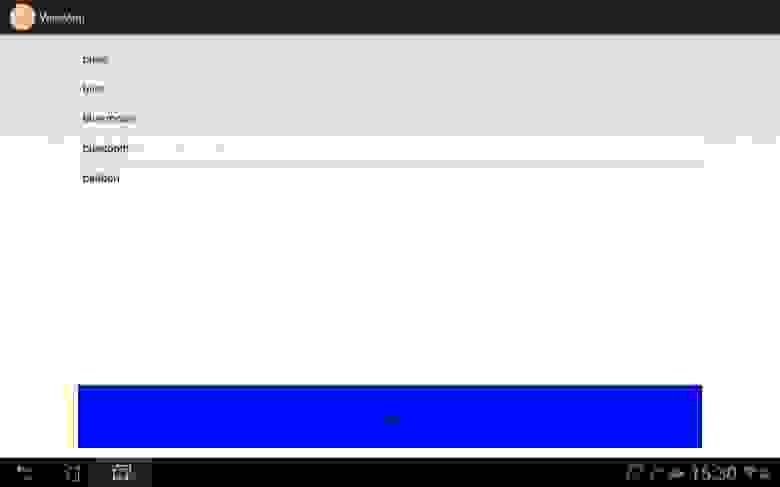
Как видите, в списке выводятся все возможные (похожие) слова и из них уже выбирается необходимое нам.
Ну и на «finish», я закончил беседу с бездушной (или нет?) машиной.
Надеюсь моя небольшая статья побудит кого-нибудь на создание (не, не терминатора) какого-либо перспективного проекта, который упростит повседневную жизнь людям, а вам принесет миллионы, ну или хотя бы окажется полезной. Дерзайте!
Источник
Сверхбыстрое распознавание речи без серверов на реальном примере
В этой статье я подробно расскажу и покажу, как правильно и быстро прикрутить распознавание русской речи на движке Pocketsphinx (для iOS порт OpenEars) на реальном Hello World примере управления домашней техникой.
Почему именно домашней техникой? Да потому что благодаря такому примеру можно оценить ту скорость и точность, которой можно добиться при использовании полностью локального распознавания речи без серверов типа Google ASR или Яндекс SpeechKit.
К статье я также прилагаю все исходники программы и саму сборку под Android.
С чего вдруг?
Наткнувшись недавно на статью о прикручивании Яндекс SpeechKit-а к iOS приложению, я задал вопрос автору, почему для своей программы он захотел использовать именно серверное распознавание речи (по моему мнению, это было излишним и приводило к некоторым проблемам). На что получил встречный вопрос о том, не мог бы я поподробней описать применение альтернативных способов для проектов, где нет необходимости распознавать что угодно, а словарь состоит из конечного набора слов. Да еще и с примером практического применения…
Зачем нам что-то еще кроме Яндекса и Google?
Так Android же умеет распознавать речь без интернета!
Да-да… Только на JellyBean. И только с полуметра, не более. И это распознавание — это та же диктовка, только с использованием гораздо меньшей модели. Так что управлять ею и настраивать ее мы тоже не можем. И что она вернет нам в следующий раз — неизвестно. Хотя для СМС-ок в самый раз!
Что будем делать?

Будем реализовывать голосовой пульт управления домашней техникой, который будет работать точно и быстро, с нескольких метров и даже на дешевом тормозном хламе очень недорогих Android смартфонах, планшетах и часах.
Логика будет простой, но очень практичной. Активируем микрофон и произносим одно или несколько названий устройств. Приложение их распознает и включает-выключает их в зависимости от текущего состояния. Либо получает от них состояние и произносит его приятным женским голосом. Например, текущая температура в комнате.
Микрофон будем активировать или голосом, или нажатием на иконку микрофона, или даже просто положив руку на экран. Экран в свою очередь может быть и полностью выключенным.
На видео показано, что получилось в итоге. Далее же речь пойдет о технической реализации с выдержками из реально работающего кода и немного теории.
Что такое Pocketsphinx
Pocketsphinx — это движок распознавания с открытым исходным кодом под Android. У него также имеется порт под iOS, WindowsPhone, и даже JavaScript.
Он позволит нам запустить распознавание речи прямо на устройстве и при этом настроить его именно под наши задачи. Также он предлагает функцию голосовой активации «из коробки» (см далее).
Мы сможем «скормить» движку распознавания русскую языковую модель (вы можете найти ее в исходниках) и грамматику пользовательских запросов. Это именно то, что будет распознавать наше приложение. Ничего другого оно распознать не сможет. А следовательно, практически никогда не выдаст что-то, чего мы не ожидаем.
Формат грамматики JSGF используется Pocketsphinx, как и многими другими подобными проектами. В нем можно с достаточной гибкостью описать те варианты фраз, которые будет произносить пользователь. В нашем случае грамматика будет строиться из названий устройств, которые есть в нашей сети, примерно так:
Pocketsphinx также может работать по статистической модели языка, что позволяет распознавать спонтанную речь, не описываемую контекстно-свободной грамматикой. Но для нашей задачи это как раз не нужно. Наша грамматика будет состоять только из названий устройств. После процесса распознавания Pocketsphinx вернет нам обычную строчку текста, где устройства будут идти один за другим.
Знак плюса обозначает, что пользователь может назвать не одно, а несколько устройств подряд.
Приложение получает список устройств от контроллера умного дома (см далее) и формирует такую грамматику в классе Grammar.
Транскрипции

Грамматика описывает то, что может говорить пользователь. Для того, чтобы Pocketsphinx знал, как он это будет произносить, необходимо для каждого слова из грамматики написать, как оно звучит в соответствующей языковой модели. То есть транскрипцию каждого слова. Это называется словарь.
Транскрипции описываются с помощью специального синтаксиса. Например:
В принципе, ничего сложного. Двойная гласная в транскрипции обозначает ударение. Двойная согласная — мягкую согласную, за которой идет гласная. Все возможные комбинации для всех звуков русского языка можно найти в самой языковой модели.
Понятно, что заранее описать все транскрипции в нашем приложении мы не можем, потому что мы не знаем заранее тех названий, которые пользователь даст своим устройствам. Поэтому мы будем гененрировать «на лету» такие транскрипции по некоторым правилам русской фонетики. Для этого можно реализовать вот такой класс PhonMapper, который сможет получать на вход строчку и генерировать для нее правильную транскрипцию.
Голосовая активация
Это возможность движка распознавания речи все время «слушать эфир» с целью реакции на заранее заданную фразу (или фразы). При этом все другие звуки и речь будут отбрасываться. Это не то же самое, что описать грамматику и просто включить микрофон. Приводить здесь теорию этой задачи и механику того, как это работает, я не буду. Скажу лишь только, что недавно программисты, работающие над Pocketsphinx, реализовали такую функцию, и теперь она доступна «из коробки» в API.
Одно стоит упомянуть обязательно. Для активационной фразы нужно не только указать транскрипцию, но и подобрать подходящее значение порога чувствительности. Слишком маленькое значение приведет к множеству ложных срабатываний (это когда вы не говорили активационную фразу, а система ее распознает). А слишком высокое — к невосприимчивости. Поэтому данная настройка имеет особую важность. Примерный диапазон значений — от 1e-1 до 1e-40 в зависимости от активационной фразы.
Запускаем распознование
Pocketsphinx предоставляет удобный API для конфигурирования и запуска процесса распознавания. Это классы SppechRecognizer и SpeechRecognizerSetup.
Вот как выглядит конфигурация и запуск распознавания:
Здесь мы сперва копируем все необходимые файлы на диск (Pocketpshinx требует наличия на диске аккустической модели, грамматики и словаря с транскрипциями). Затем конфигурируется сам движок распознавания. Указываются пути к файлам модели и словаря, а также некоторые параметры (порог чувствительности для активационной фразы). Далее конфигурируется путь к файлу с грамматикой, а также активационная фраза.
Как видно из этого кода, один движок конфигурируется сразу и для грамматики, и для распознавания активационной фразы. Зачем так делается? Для того, чтобы мы могли быстро переключаться между тем, что в данный момент нужно распознавать. Вот как выглядит запуск процесса распознавания активационной фразы:
А вот так — распозанвание речи по заданной грамматике:
Второй аргумент (необязательный) — количество миллисекунд, после которого распознавание будет автоматически завершаться, если никто ничего не говорит.
Как видите, можно использовать только один движок для решения обеих задач.
Как получить результат распознавания
Чтобы получить результат распознавания, нужно также указать слушателя событий, имплементирующего интерфейс RecognitionListener.
У него есть несколько методов, которые вызываются pocketsphinx-ом при наступлении одного из событий:
- onBeginningOfSpeech — движок услышал какой-то звук, может быть это речь (а может быть и нет)
- onEndOfSpeech — звук закончился
- onPartialResult — есть промежуточные результаты распознавания. Для активационной фразы это значит, что она сработала. Аргумент Hypothesis содержит данные о распознавании (строка и score)
- onResult — конечный результат распознавания. Этот метод будет вызыван после вызова метода stop у SpeechRecognizer. Аргумент Hypothesis содержит данные о распознавании (строка и score)
Реализуя тем или иным способом методы onPartialResult и onResult, можно изменять логику распознавания и получать окончательный результат. Вот как это сделано в случае с нашим приложением:
Когда мы получаем событие onEndOfSpeech, и если при этом мы распознаем команду для выполнения, то необходимо остановить распознавание, после чего сразу будет вызван onResult.
В onResult нужно проверить, что только что было распознано. Если это команда, то нужно запустить ее на выполнение и переключить движок на распознавание активационной фразы.
В onPartialResult нас интересует только распознавание активационной фразы. Если мы его обнаруживаем, то сразу запускаем процесс распознавания команды. Вот как он выглядит:
Здесь мы сперва играем небольшой сигнал для оповещения пользователя, что мы его услышали и готовы к его команде. На это время микрофон долже быть выключен. Поэтому мы запускаем распознавание после небольшого таймаута (чуть больше, чем длительность сигнала, чтобы не услышать его эха). Также запускается поток, который остановит распознавание принудительно, если пользователь говорит слишком долго. В данном случае это 3 секунды.
Как превратить распознанную строку в команды
Ну тут все уже специфично для конкретного приложения. В случае с нагим примером, мы просто вытаскиваем из строчки названия устройств, ищем по ним нужное устройство и либо меняем его состояние с помощью HTTP запроса на контроллер умного дома, либо сообщаем его текущее состояние (как в случае с термостатом). Эту логику можно увидеть в классе Controller.
Как синтезировать речь
Синтез речи — это операция, обратная распознаванию. Здесь наоборот — нужно превратить строку текста в речь, чтобы ее услышал пользователь.
В случае с термостатом мы должны заставить наше Android устройство произнести текущую температуру. С помощью API TextToSpeech это сделать довольно просто (спасибо гуглу за прекрасный женский TTS для русского языка):
Скажу наверное банальность, но перед процессом синтеза нужно обязательно отключить распознавание. На некоторых устройствах (например, все самсунги) вообще невозсожно одновременно и слушать микрофон, и что-то синтезировать.
Окончание синтеза речи (то есть окончание процесса говорения текста синтезатором) можно отследить в слушателе:
В нем мы просто проверяем, нет ли еще чего-то в очереди на синтез, и включаем распозанвание активационной фразы, если ничего больше нет.
И это все?
Да! Как видите, быстро и качественно распознать речь прямо на устройстве совсем несложно, благодаря наличию таких замечательных проектов, как Pocketsphinx. Он предоставляет очень удобный API, который можно использовать в решении задач, связанных с распознаванием голосовых команд.
В данном примере мы прикрутили распознавание к вполне кокрентной задаче — голосовому управлению устройствами умного дома. За счет локального распознавания мы добились очень высокой скорости работы и минимизировали ошибки.
Понятно, что тот же код можно использовать и для других задач, связанных с голосом. Это не обязательно должен быть именно умный дом.
Все исходники, а также саму сборку приложения вы можете найти в репозитории на GitHub.
Также на моем канале в YouTube вы можете увидеть некоторые другие реализации голосового управления, и не только системами умных домов.
Источник



