Что такое терафлопс? Почему они так важны для следующего поколения?
Что же за звери они такие и почему все только о них и говорят?

Когда Microsoft раскрыла техническую информацию о Xbox Series X, то главным своим достоинством компания выставила количество терафлопс. Но есть большой вопрос вокруг того, что такое терафлоп, и мы действительно должны быть взволнованы тем, что преемник Xbox One будет иметь 12 терафлопсов мощности GPU, а PS5 в районе 10.2 тера?
Насколько же на самом деле это важная спецификация и что это означает для будущего консолей следующего поколения? Давайте разбираться. Поехали!

Что же такое терафлоп?
Прежде чем мы перейдем к специфике того, должны ли мы быть впечатлены консолью, которая утверждает, что предлагает 12 терафлопсов мощности GPU, давайте поговорим о том, что такое терафлоп на самом деле.
То, на что мы, по сути, смотрим, когда углубляемся в самые технические области вычислений, — это способ измерения производительности компьютера. Слово «tera» означает триллион, а «flops» -операции с плавающей запятой в секунду.
Эти операции с плавающей запятой относятся к сложным вычислениям, выполняемым компьютером (или игровой консолью в данном случае), когда выполняются такие вещи, как рендеринг (рисование и перемещение) полигона. Количество этих операций с плавающей запятой, которые компьютер или консоль может выполнять в секунду, является способом измерения его вычислительной мощности. В случае Xbox Series X есть обещание способности обрабатывать двенадцать триллионов операций с плавающей запятой в секунду.

Подводя итог, Microsoft говорит нам, что есть серьезная мощность GPU для разработчиков, чтобы играть и делать игры. В сырых цифрах это говорит о том, что скачок в качестве игр от предыдущей консоли Xbox будет довольно существенным.
Хотя это число само по себе не говорит нам всей истории. Мы также должны учитывать другие компоненты консолей связанных с производительностью. Такие элементы, как тактовая частота и пропускная способность памяти, которые являются центральными для производительности, еще не были выявлены корпорацией Майкрософт. Пока это не произойдет, это немного игра в угадайку с точки зрения того, что мы действительно можем ожидать от серии X, насколько это касается производительности.

Консоли, предлагающие терафлопс мощности GPU, не новы, хотя и заметно меньше.
Босс Xbox Фил Спенсер поделился информацией, что следующая консоль Microsoft использует свой собственный специально разработанный процессор, который будет использовать новейшие архитектуры Zen 2 и RDNA 2 от AMD. Если мы сравним цифры, Xbox One X обеспечивает шесть терафлопсов мощности GPU. Оригинальная Xbox One имела 1.31 терафлопс. Таким образом, серия X предлагает удвоить флопы ONE X.
PS4 Pro от Sony поставляется с 4.2 терафлопсами. 18 марта на прямой трансляции Sony поделилась что у PS5 будет примерно 10,3 тера. Это конечно немного меньше чем у майков, но все равно большой скачек в мире консолей.

Гораздо более полезным сравнением флопов было бы увидеть в сопоставление с графическими картами, доступными на ПК. GeForce RTX 2080 Ti от Nvidia выдает 14,2 терафлопса и является одной из самых мощных карт, доступных прямо сейчас. Таким образом, можно уже судить о том что мощность новых консолей будет сопоставима в этом аспекте с дорогими сборками персональных компьютеров на настоящее время.

Что на самом деле означает 12 терафлопсов?
Так что же означают эти двузначные флопы для геймеров? Ну, есть базовое обещание, что мы сможем играть в игры, которые графически более впечатляют и намного больше, чем то, что доступно на консолях текущего поколения. По сути, это открывает дверь к производительности наравне с играми высокого класса на ПК. Это дает разработчикам возможность быть более экспансивными с открытыми мировыми средами, потому что теперь у них есть инструменты и дополнительные мощности для разработки некстген игр.
Еще одним большим преимуществом этого повышения мощности является то, что игры будут комфортно работать с более высокой частотой кадров, даже в 4к или 8к гейминге.
Для разработчиков появится возможность применять фишки такие как трассировка лучей и затенение с переменной скоростью. Будет возможным создавать миры, которые богаче, более детализированы и более реалистичны. На это требуется много мощностей GPU, поэтому с удвоенной силой доступной на предыдущей консоли, можно распределить эту рабочую нагрузку более равномерно, чтобы помочь создать эти более динамичные игровые среды.
Источник
iPhone 12, PlayStation 5, Xbox X: все о главных премьерах осени

Sony PlayStation 5
Когда: в ноябре
Что известно:
- Приставка будет поддерживать видеоигры в разрешении 4K Ultra HD (3840 на 2160 пикселей).
- Пользователям будут доступны все игры для двух предыдущих версий — PlayStation 4 и PlayStation 4 Pro. Еще более 100 новых игр выпустят специально для новой модели.
- Накопитель SSD со скоростью 5,5 ГБ/с (почти в два раза больше, чем у Xbox). Производительность — 10,28 терафлопс (триллионов операций в секунду). Это означает высокую детализацию игры и персонажей, быстрый запуск и отклик на команды.
- Предзаказ на новые модели уже запущен, но пока что только для жителей США и по специальным приглашениям. Их будут рассылать только тем игрокам, которые уже активно проявили себя в играх для PS4. При этом приглашение не гарантирует покупку, а всего лишь место в очереди.
Что интересного:
Главная технологическая фишка — адаптер для самого современного стандарта беспроводной связи Wi-Fi 6 (при этом у предыдущей модели изначально был Wi-Fi 4). Также внутри будет модуль Bluetooth 5.1. Это обеспечит максимальную скорость передачи данных между всеми устройствами.
В дополнение к PlayStation 5 обещают множество совместимых VR-аксессуаров: двойную станцию для зарядки игровых контроллеров, беспроводные наушники Pulse 3D, пульт ДУ, веб-камеру для захвата изображения в HD, а к концу года — вторую, беспроводную версию шлема PS VR.
Но самое любопытное — это технология распознавания лиц, точнее — телеметрии. Ее применят для того, чтобы приставка могла «узнавать» новых игроков. Sony уже получила патент на технологию и опубликовала его.
Эта опция не позволит игрокам анонимно переключать профили на одном и том же устройстве вручную. То есть «читерский» ход с передачей приставки более опытному пользователю, чтобы тот прошел за тебя сложный уровень, больше не пройдет.
Предполагаемая цена: $399 или ₽29,5 тыс. за обычную приставку и $499 или ₽36,9 тыс. — за версию с Blu-ray.
Microsoft Xbox Series X
Главный конкурент PS уже приготовил ответный удар. И, по мнению некоторых инсайдеров, по-настоящему сокрушительный.
Когда: в ноябре
Что обещают:
- Игры будут доступны не только в Full HD, но и в 4К и 8К — специально для владельцев больших телевизоров с отличным разрешением.
- Совместимость с играми под все 4 поколения приставок: Xbox One, Xbox 360 и Xbox. Причем при переходе на новую модель сохранятся не только все игры, но и пройденные уровни с персонажами. Также аксессуары от Series X будут совместимы с Xbox One.
- К выходу модели уже подготовили тысячи игр, из них более 100 оптимизируют специально под Series X: включая суперхиты Assassin’s Creed Valhalla, Dirt 5, Gears Tactics, Watch Dogs: Legion, The Medium, Scorn, Tetris Effect: Connected, а также — улучшенные версии Destiny 2 и Forza Horizon 4.
- Производительность приставки составит 12 терафлопс, что на 14% больше, чем у PS. Скорость SSD — ниже, чем у PS5: 2,8 ГБ/с. Зато Xbox работает стабильнее и тише, не разгоняясь и не перегреваясь.
Что интересного:
Внутри новой Xbox — супермощный гибридный процессор от AMD с 8 ядрами и 15,3 млрд транзисторов. Предположительно, часть ядер на нем будут выделены специально для того, чтобы ускорить машинное обучение приставки.
Предполагаемая цена: от $499 или ₽36,9 тыс. до $599 или ₽44,4 тыс.
iPhone 12
Когда: в октябре
Что обещают:
- В серии представят четыре модели — iPhone 12, iPhone 12 Max, iPhone 12 Pro и iPhone 12 Pro Max, с диагоналями от 5,4 до 6,7’’.
- Батарея при максимальной загрузке будет работать до 6 часов — на 2 часа дольше, чему у iPhone 11 Pro.
- Камера на 16 Мп — что очень немного, даже по сравнению с дешевыми китайскими конкурентами. Зато есть 64-мегапиксельный оптический датчик и 5-кратный зум.
- Все это — в комплекте со светосильными широкоугольным и сверхширокоугольным объективами и двойной оптической стабилизацией HDR-дисплеи с частотой обновления 120 Гц и поддержкой ProMotion, которую уже используют в iPad. Эта технология позволяет автоматически регулировать частоту смены изображения в зависимости от движения в кадре. Также есть поддержка Slo-mo видео в разрешении 4К.
Что интересного:
По слухам, внутри iPhone 12 Pro Max будет 6-ядерный процессор А14 нового поколения. Предварительные тесты показали, что по производительности он обгоняет самую мощную мобильную платформу Qualcomm.
Как и iPad Pro 2020-го года, новые iPhone оснастят сканером LiDAR — такие используют в беспилотниках, чтобы распознавать объекты на дороге. В двух словах: сканер измеряет, сколько потребуется времени пучку лазера на отражение от стоящих перед камерой объектов, и составляет 3D-карту объектов вокруг.
Зачем он нужен здесь? Прежде всего, для построения объемного изображения при работе в дополненной реальности (о ней расскажем подробнее). Face ID распознает лица на расстоянии до 60 см, а LiDAR — до 5 метров. Он составляет объемную карту помещения или ландшафта: то есть не распознает детали вроде волос или ушей, зато позволит точно наложить AR-объекты на реальные. Инструмент будет особенно полезен дизайнерам и архитекторам, студентам и профессорам, музеям и экскурсоводам.
По словам Apple, именно такую технологию будет использовать NASA в своей миссии по отправке людей на Марс. Не все согласны с тем, что лидар так уж необходим в смартфоне. Но на AR Apple возлагает особые надежды и, похоже, будет развивать технологию во всех устройствах.
Предполагаемая цена: от $1 099 или ₽81,5 тыс. до $1 199 или ₽89 тыс. При этом зарядку и наушники теперь нужно будет покупать отдельно. Apple объяснила это «борьбой за экологию», но издание TrendForce считает, что причина — в удорожании комплектующих, в том числе — из-за поддержки 5G.
Бонус: AR от Apple
И в завершении — про инновации, которые мы можем увидеть уже в следующем году. Не так давно Bloomberg выяснил, что Apple добавит AR-технологии в iPhone, iPad и сервис Apple TV+. Как считают в агентстве, компания таким образом пытается удержать подписчиков и подготовить их к выпуску своей же VR-гарнитуры.
Как это будет выглядеть?
Герои кино и сериалов якобы будут отображаться на смартфоне или планшете на фоне реального окружения пользователя — прямо в квартире, на улице или в метро.
Ранее Apple анонсировала другую ожидаемую новинку — очки дополненной реальности (выйдут в 2022-2023 годах), которые решили выпускать вместо шлема. Похоже, компания взяла фокус на продукты с AR, используя технологию как главное конкурентное преимущество.
Источник
Как и зачем мерить FLOPSы
 Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (
Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (попугаях) операциях с плавающей точкой, которой часто пользуются, чтобы померить у кого больше. Особенно важно померяться FLOPS’ами в мире Top500 суперкомпьютеров, чтобы выяснить, кто же среди них самый-самый. Однако, предмет измерения должен иметь хоть какое-нибудь применение на практике, иначе какой смысл его замерять и сравнивать. Поэтому для выяснения возможностей супер- и просто компьютеров существуют чуть более приближенные к реальным вычислительным задачам бенчмарки, например, SPEC: SPECint и SPECfp. И, тем не менее, FLOPS активно используется в оценках производительности и публикуется в отчетах. Для его измерения давно уже использовали тест Linpack, а сейчас применяют открытый стандартный бенчмарк из LAPACK. Что эти измерения дают разработчикам высокопроизводительных и научных приложений? Можно ли легко оценить производительность реализации своего алгоритма в FLOPSaх? Будут ли измерения и сравнения корректными? Обо всем этом мы поговорим ниже.
Давайте сначала немного разберемся с терминами и определениями. Итак, FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Здесь используется слово «вычислительных», так как микропроцессор умеет выполнять и другие инструкции с такими операндами, например, загрузку из памяти. Такие операции не несут полезной вычислительной нагрузки и поэтому не учитываются.
Значение FLOPS, опубликованное для конкретной системы, – это характеристика прежде всего самого компьютера, а не программы. Ее можно получить двумя способами – теоретическим и практическим. Теоретически мы знаем сколько микропроцессоров в системе и сколько исполняемых устройств с плавающей точкой в каждом процессоре. Все они могут работать одновременно и начинать работу над следующей инструкцией в конвеере каждый цикл. Поэтому для подсчета теоретического максимума для данной системы нам нужно только перемножить все эти величины с частотой процессора – получим количество FP операций в секунду. Все просто, но такими оценками пользуются, разве что заявляя в прессе о будущих планах по построению суперкомпьютера.
Практическое измерение заключается в запуске бенчмарка Linpack. Бенчмарк осуществляет операцию умножения матрицы на матрицу несколько десятков раз и вычисляет усредненное значение времени выполнения теста. Так как количество FP операций в имплементации алгоритма известно заранее, то разделив одно значение на другое, получим искомое FLOPS. Библиотека Intel MKL (Math Kernel Library) содержит пакет LAPAСK, — пакет библиотек для решения задач линейной алгебры. Бенчмарк построен на основе этого пакета. Cчитается, что его эффективность находится на уровне 90% от теоретически возможной, что позволяет бенчмарку считаться «эталонным измерением». Отдельно Intel Optimized LINPACK Benchmark для Windows, Linux и MacOS можно качать здесь, либо взять в директории composerxe/mkl/benchmarks, если у вас установлена Intel Parallel Studio XE.
Очевидно, что разработчики высокопроизводительных приложений хотели бы оценить эффективность имплементации своих алгоритмов, используя показатель FLOPS, но уже померянный для своего приложения. Сравнение измеренного FLOPS с «эталонным» дает представление о том, насколько далека производительность их алгоритма от идеальной и каков теоретический потенциал ее улучшения. Для этого всего-навсего нужно знать минимальное количество FP операций, требуемое для выполнения алгоритма, и точно измерить время выполнения программы (ну или ее части, выполняющей оцениваемый алгоритм). Такие результаты, наряду с измерениями характеристик шины памяти, нужны для того, чтобы понять, где реализация алгоритма упирается в возможности аппаратной системы и что является лимитирующим фактором: пропускная способность памяти, задержки передачи данных, производительность алгоритма, либо системы.
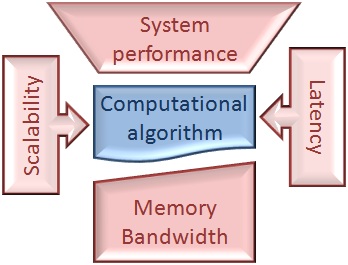
Ну а теперь давайте покопаемся в деталях, в которых, как известно, все зло. У нас есть три оценки/измерения FLOPS: теоретическая, бенчмарк и программа. Рассмотрим особенности вычисления FLOPS для каждого случая.
Теоретическая оценка FLOPS для системы
Чтобы понять, как подсчитывается количество одновременных операций в процессоре, давайте взглянем на устройство блока out-of-order в конвеере процессора Intel Sandy Bridge.
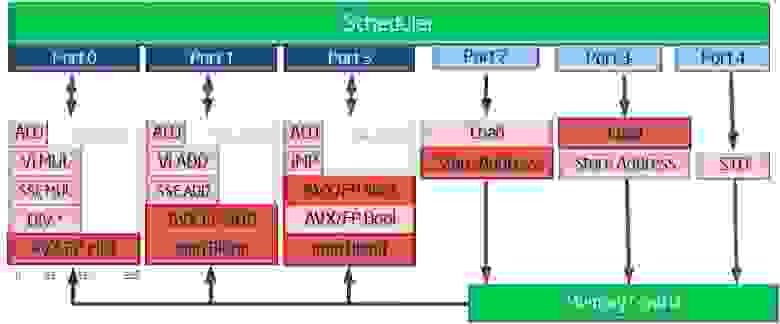
Здесь у нас 6 портов к вычислительным устройствам, при этом, за один цикл (или такт процессора) диспетчером может быть назначено на выполнение до 6 микроопераций: 3 операции с памятью и 3 вычислительные. Одновременно могут выполняться одна операция умножения (MUL ) и одна сложения (ADD ), как в блоках x87 FP, так и в SSE, либо AVX. С учетом ширины SIMD регистров 256 бит мы может получить следующие результаты:

8 MUL (32-bit) и 8 ADD (32-bit): 16 SP FLOP/cycle, то есть 16 операций с плавающей точкой одинарной точности за один такт.
4 MUL (64-bit) и 4 ADD (64-bit): 8 DP FLOP/cycle, то есть 8 операций с плавающей точкой двойной точности за один такт.
Теоретическое пиковое значение FLOPS для доступного мне 1-сокетного Xeon E3-1275 (4 cores @ 3.574GHz) составляет:
16 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 228 GFLOPS SP
8 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 114 GFLOPS DP
Запуск бенчмарка Linpack
Запускам бенчмарк из пакета Intel MKL на системе и получаем следующие результаты (порезано для удобства просмотра):
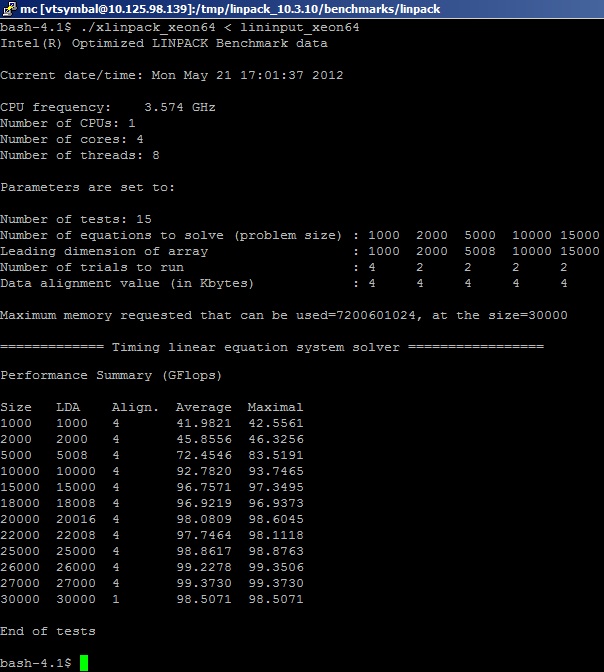
Здесь нужно сказать, как именно учитываются FP операции в бенчмарке. Как уже упоминалось, тест заранее «знает» количество операций MUL и ADD, которые необходимы для перемножения матриц. В упрощенном представлении: производится решение системы линейных уравнений Ax=b (несколько тысяч штук) путем перемножения плотных матриц действительных чисел (real8) размером MxK, а количество операций сложения и умножения, необходимых для реализации алгоритма, считается (для симметричной матрицы) Nflop = 2*(M^3)+(M^2). Вычисления производятся для чисел с двойной точностью, как и для большинства бенчмарков. Сколько операций с плавающей точкой действительно выполняется в реализации алгоритма, пользователей не волнует, хотя они догадываются, что больше. Это связано с тем, что выполняется декомпозиция матриц по блокам и преобразование (факторизация) для достижения максимальной производительности алгоритма на вычислительной платформе. То есть нам нужно запомнить, что на самом деле значение физических FLOPS занижено за счет неучитывания лишних операций преобразования и вспомогательных операций типа сдвигов.
Оценка FLOPS программы
Чтобы исследовать соизмеримые результаты, в качестве нашего высокопроизводительного приложения будем использовать пример перемножения матриц, сделанный «своими руками», то есть без помощи математических гуру из команды разработчиков MKL Performance Library. Пример реализации перемножения матриц, написанный на языке С, можно найти в директории Samples пакета Intel VTune Amplifier XE. Воспользуемся формулой Nflop=2*(M^3) для подсчета FP операций (исходя из базового алгоритма перемножения матриц) и померим время выполнения перемножения для случая алгоритма multiply3 при размере симметричных матриц M=4096. Для того, чтобы получить эффективный код, используем опции оптимизации –O3 (агрессивная оптимизация циклов) и –xavx (использовать инструкции AVX) С-компилятора Intel для того, чтобы сгенерировались векторные SIMD-инструкции для исполнительных устройств AVX. Компилятор нам поможет узнать, векторизовался ли цикл перемножения матрицы. Для этого укажем опцию –vec-report3. В результатах компиляции видим сообщения оптимизатора: «LOOP WAS VECTORIZED» напротив строки с телом внутреннего цикла в файле multiply.c.
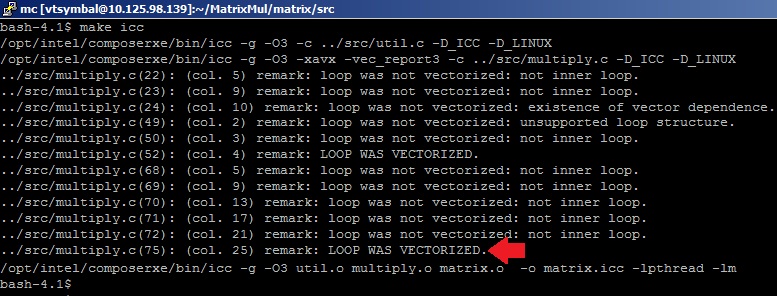
На всякий случай проверим, какие инструкции сгенерированы компилятором для цикла перемножения.
$icl –g –O3 –xavx –S
По тэгу __tag_value_multiply3 ищем нужный цикл — инструкции правильные.
$vi muliply3.s 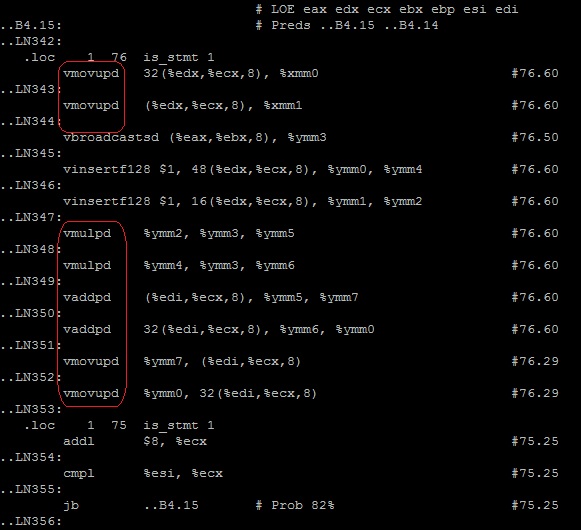
Результат выполнения программы (
7 секунд) 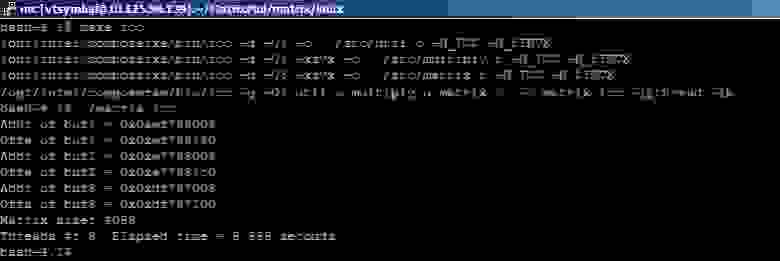
нам дает следующее значение FLOPS = 2*4096*4096*4096/7[s] = 19.6 GFLOPS
Результат, конечно, очень далек от того, что получается в Linpack, что объясняется исключительно квалификционной пропастью между автором статьи и разработчиками библиотеки MKL.
Ну, а теперь дессерт! Собственно то, ради чего я затеял свое исследование этой, вроде бы скучной и давно избитой, темы. Новый метод измерения FLOPS.
Измерение FLOPS программы
Существуют задачи в линейной алгебре, программную имплементацию решения которых очень сложно оценить в количестве FP операций, в том смысле, что нахождение такой оценки само является нетривиальной математической задачей. И тут мы, что называется, приехали. Как считать FLOPS для программы? Есть два пути, оба экспериментальных: трудный, дающий точный результат, и легкий, но обеспечивающий приблизительную оценку. В первом случае нам придется взять некую базовую программную имплементацию решения задачи, скомпилировать ее в ассемблерные инструкции и, выполнив их на симуляторе процессора, посчитать количество FP операций. Звучит так, что резко хочется пойти легким, но недостоверным путем. Тем более, что если ветвление исполнения задачи будет зависеть от входных данных, то вся точность оценки сразу поставится под сомнение.
Идея легкого пути состоит в следующем. Почему бы не спросить сам процессор, сколько он выполнил FP инструкций. Процессорный конвеер, конечно же, об этом не ведает. Зато у нас есть счетчики производительности (PMU – вот тут про них интересно), которые умеют считать, сколько микроопераций было выполнено на том или ином вычислительном блоке. С такими счетчиками умеет работать VTune Amplifier XE.
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
- Создаем новый проект и указываем в качестве target application наше приложение matrix.
- Выбираем профиль Lightweight Hotspots (который использует технологию сэмплирования счетчиков процессора Hadware Event-based Sampling) и копируем его для создания пользовательского профиля. Обзываем его My FLOPS Analysis.
- Редактируем профиль, добавляем туда новые процессорные счетчики событий процессора Sandy Bridge (Events). На них остановимся чуть подробнее. В их названии зашифрованы исполнительные устройства (x87, SSE, AVX) и тип данных, над которыми выполнялась операция. Каждый такт процессора счетчики складывают количество вычислительных операций, назначенных на исполнение. На всякий случай мы добавили счетчики на все возможные операции с FP:
- FP_COMP_OPS_EXE. SSE_PACKED_DOUBLE – векторы (PACKED) данных двойной точности (DOUBLE)
- FP_COMP_OPS_EXE. SSE_PACKED_SINGLE – векторы данных одинарной точности
- FP_COMP_OPS_EXE. SSE_SCALAR_DOUBLE – скалярые DP
- FP_COMP_OPS_EXE. SSE_ SCALAR _SINGLE – скалярные SP
- SIMD_FP_256.PACKED_DOUBLE – векторы AVX данных DP
- SIMD_FP_256.PACKED_SINGLE – векторы AVX данных SP
- FP_COMP_OPS_EXE.x87 – скалярые данные x87
Нам остается только запустить анализ и подождать результатов. В полученных результатах переключаемся в Hardware Events viewpoint и копируем количетво events, собранных для функции multiply3: 34,648,000,000.
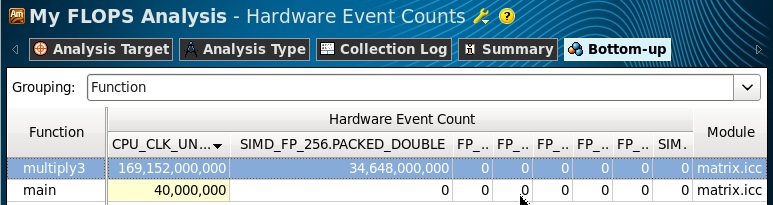
Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time
FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE.
Удостоверимся, что данные события собраны для нашего цикла в функции multiply3 (переключившись в Source View):

FLOPS = 4 *34.6Gops/7s = 19.7 GFlops
Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение
FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.
Источник



