- UTF-8: Кодирование и декодирование
- О Юникоде
- О UTF-8
- Кодируем в UTF-8
- Декодируем UTF-8
- Ссылки
- Проблемы с кодировкой в Mail и их возможные решения
- UTF-8 vs UTF-16. Несколько советов программистам
- Введение
- Стандарт Юникод
- Стандарт кодирования UTF-8
- Стандарт кодирования UTF-16
- Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
- Несколько советов программистам
UTF-8: Кодирование и декодирование
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Ссылки
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
Источник
Проблемы с кодировкой в Mail и их возможные решения
 Встроенный почтовый клиент Mac OS X с логичным и незамысловатым названием Mail есть за что похвалить — например, за развитую систему фильтрации писем на основе правил, за поддержку дополнительных плагинов, расширяющих возможности почты (вроде шифрования), за тесную интеграцию с клиентом iPhone и т.д. Но поводов для недовольства у пользователей Mail тоже хватает, особенно если они проживают не в англоговорящих странах. Главный повод — кодировка. Пожалуй, нет ни одного русского владельца Мака, который не сталкивался в Mail.app с тем, что принято называть словом «кракозябры» — это символьные шедевры вроде ÈØàÞÚÐï íÛÕÚâàØäØÚÐæØï, аЈаИб�аОаКаАб� б�аЛаЕ или даже Ð¨Ð¸Ñ€Ð¾ÐºÐ°Ñ ÑлектрРв названиях тем, содержимом писем или именах вложений.
Встроенный почтовый клиент Mac OS X с логичным и незамысловатым названием Mail есть за что похвалить — например, за развитую систему фильтрации писем на основе правил, за поддержку дополнительных плагинов, расширяющих возможности почты (вроде шифрования), за тесную интеграцию с клиентом iPhone и т.д. Но поводов для недовольства у пользователей Mail тоже хватает, особенно если они проживают не в англоговорящих странах. Главный повод — кодировка. Пожалуй, нет ни одного русского владельца Мака, который не сталкивался в Mail.app с тем, что принято называть словом «кракозябры» — это символьные шедевры вроде ÈØàÞÚÐï íÛÕÚâàØäØÚÐæØï, аЈаИб�аОаКаАб� б�аЛаЕ или даже Ð¨Ð¸Ñ€Ð¾ÐºÐ°Ñ ÑлектрРв названиях тем, содержимом писем или именах вложений.
Сегодня мы расскажем вам о сущности этой проблемы и некоторых путях её решения.
Mail.app от других почтовых клиентов традиционно отличает повышенная чувствительность к тому, из какой программы было отправлено письмо. Дело в том, что разные почтовые клиенты имеют присущие только им особенности разметки и оформления электронных писем, невидимые глазу пользователя, зато воспринимаемые серверами и программами.
Проблема усугубляется ещё и тем, что в настройках Mail невозможно задать кодировку входящих писем по умолчанию — т.е. способ перевода привычных нам букв, цифр и знаков препинания в привычные компьютеру биты и байты. Mail пытается автоматически распознать кодировку входящей почты, и как-то непосредственно повлиять на этот процесс пользователь тоже не может.
Зато возможно повлиять на этот процесс косвенно. Набор кодировок, которые Mail использует для распознания, зависит от набора используемых всей системой кодировок. А Этот набор, в свою очередь, зависит от количества используемых системой языков. Отсюда вытекает первый совет — удалите из системы все неиспользуемые вами языки.
Зайдите в Системные настройки, выберите пульт «Язык и текст», и увидите следующий список:
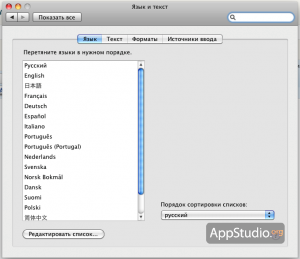 Список языков Mac OS X
Список языков Mac OS X
Нажмите на кнопку «Редактировать список» и снимите соответствующие галочки. После этого перезагрузите компьютер или завершите сеанс.
Представленный скриншот сделан в системе Mac OS X 10.6.2. В Mac OS X 10.5 данный пульт настроек устроен несколько иначе, однако редактирование списка языков там организовано почти так же.
Следующий шаг — это настройки самого клиента Mail. Как мы уже сказали, в программе не предусмотрено никаких постоянных настроек кодировки. Но это не значит, что их нет вообще. На самом деле, через Терминал всё-таки можно заставить Mail работать с определённой кодировкой.
Но перед тем, как задать кодировку по умолчанию, надо узнать, какая это должна быть кодировка. Это придётся делать экспериментальным путём:
- найдите несколько писем с кракозябрами
- выберите первое и зайдите в меню Сообщение — Кодировка текста
- последовательно перепробуйте все кодировки, начинающиеся со слова «Кириллическая» (KOI8-R, ISO 8859-5, Windows), а также UTF-8
- если письмо стало читабельным, посмотрите на остальные письма: если и их можно прочесть, то считайте, что решение найдено
- в противном случае продолжайте перебор кодировок
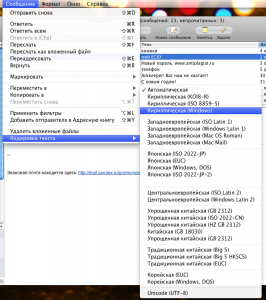 Меню кодировок Mail
Меню кодировок Mail
Если вы нашли подходящую кодировку, то останется её зафиксировать. Скорее всего, это будет либо кодировка KOI8-R, либо UTF-8. Полностью завершите Mail (по комбинации Cmd+Q). Запустите Терминал (через Spotlight или из папки Программы/Служебные программы), и введите команду:
defaults write com.apple.mail NSPreferredMailCharset koi8-r
defaults write com.apple.mail NSPreferredMailCharset utf-8
После чего нажмите Enter и закройте Терминал.
Если не хотите возиться с Терминалом, то можете установить пульт настроек Secrets и сменить кодировку через него:
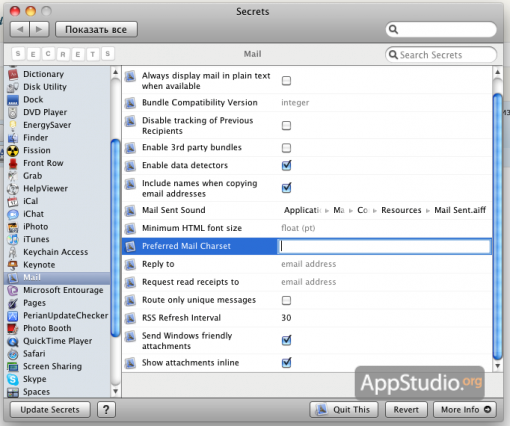 Смена кодировки Mail через пульт Secrets
Смена кодировки Mail через пульт Secrets
Если предложенный выше вариант не сработает, попробуйте прописать через Терминал ещё один параметр:
defaults write com.apple.mail LeopardPreferredMailCharset utf-8
(или defaults write com.apple.mail LeopardPreferredMailCharset koi8-r)
Возможно, это поможет вам избавиться от проблем с кодировкой в темах и тексте писем. С русскими именами вложений ситуация ещё более загадочна. Многолетние наблюдения позволяют говорить о том, что в их порче виноват вовсе не Mail, а отправляющая почту программа. Например, известен глюк с письмами из Thunderbird — практически всегда имена вложений на русском приходят на Мак испорченными. Для решения этой проблемы в самом Thunderbird необходимо изменить значение параметра mail.strictly_mime.parm_folding равным единице.
Таким образом, причины и решения проблем в Mail лежат гораздо глубже, чем кажется сначала. Если же ничего не поможет, и адресованные вам письма по-прежнему будут приходить испорченными, советуем обратить внимание на другие почтовые клиенты.
Источник
UTF-8 vs UTF-16. Несколько советов программистам
Введение
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка. Первые 128 символов таблицы представлены на рис.1:
 Рис.1. Первые 128 символов таблицы ASCII.
Рис.1. Первые 128 символов таблицы ASCII.
Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева. Началом кода является управляющий символ (выделен жирным):
0 – используется 8-битная кодировка,
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 00000100 (пробел) 00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o).
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма. Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535. Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Рис.2. Буква древнетюркского алфавита.
Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам. Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.
К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
В ячейках таблицы 1 содержится количество бит, требуемое для кодирования одного символа из таблицы Юникод. Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Источник



