- How to create custom views in android?
- Создание собственной View под Android – может ли что-то пойти не так?
- 1. Как это работает?
- 2. Android SDK «хочет сыграть с тобой в игру» © Goog… Пила
- 2.1. Inflate разметки внутрь кастомного View с использованием DataBinding
- 2.2. Measure & Layout passes
- 2.3. ScrollView не разрешает менять размер ребенка
- 2.4. Закругленные углы у background
- 2.5. Позиционирование View внутри FrameLayout
- 2.6. Видишь отступы шрифта? Нет? А они тебя видят! © includeFontPadding
- 2.7. У ViewPropertyAnimator нет метода reverse()
- 2.8. ScaleGestureDetector (он же «пинч», он же «зум»)
- 2.8.1. Небольшие замечания
- 2.8.2. Проблемы
- 2.8.2.1. Минимальный пинч
- 2.8.2.2. Слоп
- 2.8.2.3. Скачки detector.getScaleFactor() при первом пинче
- 2.9. ScrollView.setScroll() срабатывает только после super.onLayout() ?
- 3. Задача кластеризации юзеров
- 3.1. Что делать с граничными юзерами?
- 3.2. Какое кол-во очков показывать у группы?
- 3.3. Алгоритм
- 3.3.1. Задача
- 3.3.2. Пару слов об алгоритмах
- 3.3.3. Алгоритм №1
- 3.3.4. Алгоритм №2
- 3.3.5. Алгоритм №3
- 3.3.6. Алгоритм №3.1
- 3.3.7. Алгоритм №4
- 4. Нерешенные проблемы (UPD: уже решенные)
- 4.1. ScrollView.setScroll() внутри ScrollView.onLayout() срабатывает корректно только после вызова super.onLayout() (если изменять размер child’а внутри child’а этого ScrollView )
- 4.2. View.setVisibility(GONE) вызывает requestLayout()
- 4.999. Решение описанных проблем
- 5. Заключение
How to create custom views in android?
Before diving into the process of creating a custom view, It would be worth stating why we may need to create custom views.
- Uniqueness: Create something that cannot be done by ordinary views.
- Optimisation: A lot of times we tend to add multiple views or constraints to create the desired view that can be optimized drastically in terms of draw, measure or layout time.
The best way to start would be to understand how android manages view groups and lays out views on the screen. Let us take a look at the diagram below.

onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int)
Every parent view passes a height and width constraint to its child view based on which the child view decides how big it wants to be. The child view then calls setMeasuredDimension() to store its measured width and height.
How are these constraints passed?
Android uses a 32-bit int called the measure spec to pack a dimension and its mode. The mode is a constraint and can be of 3 types:
- MeasureSpec.EXACTLY: A view should be absolutely the same size as dimension passed along with spec. Eg. layout_width= “100dp”, layout_width=”match_parent”,layout_weight=”1″.
- MeasureSpec.AT_MOST: A view can have maximum height/width of dimension passed. However, it can be also smaller if it wishes to be. Eg android:layout_width=”wrap_content”
- MeasureSpec.UNSPECIFIED: A view can be of any size. This is passed when we are using a ScrollView or ListView as our parent.
onLayout(changed: Boolean, left: Int, top: Int, right: Int, bottom: Int)
Android applies any offsets or margins and calls this method to inform your view about where exactly it would be placed on the screen. Unlike onMeasure, it is called only once during the traversal. So it is recommended to perform any complex calculations in this method.
onDraw(canvas: Canvas)
Finally, Android provides you with a 2D drawing surface i.e the canvas on which you can draw using a paint object.
The UI thread then passes display lists to render thread which does a lot of optimizations and finally GPU process the data passed to it by render thread.
How to define attributes for your view?
Declaring XML attributes is simple. You just need to add a declarable-style in your attrs.xml and declare a format for every attribute.
For instance, if you are creating a simple view which displays a circle with its label. Your attributes may look like this.
The same is referenced while creating a view in the following manner.
Now, we have to parse these attributes in your java or kotlin class.
- Create your view class which extends the android.view class
- Obtain a reference to the attributes declared in XML. While attrs is passed in the constructor, the second parameter is a reference to the styleable we just declared. The latter two are used for getting default style attributes in theme or supplying a default style attributes.
- Parsing the attribute arguments
Android automatically handles the process of converting dp or sp to the right amount of pixels according to screen size when parsing a dimension attribute. But, You need to ensure that the fallback value is converted to appropriate pixel value since android returns fallback value without any conversions if an attribute value is not defined in XML.
While parsing all other attributes is quite straightforward. I will brief you about how to parse flags. Declaring flags attributes can be really useful sometimes since we can check for multiple properties using a single attribute. This is the same way android handles the visibility flag.
colorType here is an integer which represents a flagSet. Now, since every bit in an integer can be used to represent an indication. We can check if a flag exists and perform our operations accordingly. To check if a flag type stroke exits, we can simply perform an or operation on flagSet with the stroke value. If the result stays the same that means the flag actually exists in the flagSet.
- Finally, recycle the typed array to be used by the later caller.
Initialising your objects
It is always better to initialize your paint and path objects or other variables in the constructor itself. Since declaring it any other traversal method may result in the meaningless creation of objects again and again.
Calculating your view size
Calculating view size can be really challenging sometimes. You have to make sure that your view does not take any extra pixel or request any less pixel as it may end up showing extra white space or not showing complete view respectively. These are the basic steps that you need to follow to calculate the size of your view.
- Calculate how much width and height your view requires. For instance, if you are drawing a simple circle with its label below the circle. The suggested width would be :
(circle diameter+ any extra width if occupied by the label). - Calculate the desired width by adding the suggested width with paddingStart and paddingEnd. Similarly, desiredHeight would be suggested height plus paddingTop & paddingBottom.
- Calculate actual size respecting the constraints. To calculate this, you simply need to pass measure spec passed to you in onMeasure() and your desired dimension in this method called resolveSize(). This method would tell you closest possible dimension to your desired width or height while still respecting its parent’s constraints.
- Most importantly, you need to set the final width and height in onMeasure method by calling setMeasuredDimension(measuredWidth,measuredHeight) to store the measured width and height of this view otherwise, you might see your view crashing with an IllegalStateException.
Positioning your views
We can position our child views by using the onLayoutMethod. The code simply may involve iterating over any child views and assigning them a left, top, right and a bottom bound depending on measured widths and heights.
Drawing your view
Before using the canvas there are few things that we need to understand:
- Paint: The Paint class holds the style and color information about how to draw geometries, text, and bitmaps. Here is how we create a paint object.
You can read about more about the properties here.
- Drawing Shapes: You can directly draw shapes like a line, arc, circle etc on the canvas. Let us take a look at the diagram below to gain a better understanding.

Using Paths: Drawing complex shapes with the above methods may get a bit complex so android offers a Path class. With the Path class, you can imagine that you are holding a pen and you can draw a shape, then maybe move to a different position and draw another shape. Finally, when you are done creating a path. You can simply draw the path on the canvas like this. Also, when using paths you can also use different path effects (discussed below in detail). Below, is an example of the shape created using paths.

- Path Effects: If you also apply a Corner path effect to your paint object with a certain radius the polygon will look like this. You can also use other path effects like DashPathEffect, DiscretePath etc. To combine two different path effects you can use the ComposePathEffect.

bitmap: Bitmap that you want to draw on canvas
src: It takes a rect object which specifies the portion of the bitmap you want to draw. This can be null if you want to draw the complete bitmap.
dest: A rect object which tells how much area do you want to cover on the canvas with the bitmap
paint: The paint object with which you want to draw the bitmap
Android automatically does all the necessary scaling or translation to fit the source on destination area.
You can also draw drawables on canvas.
Before drawing a drawable, you would need to set bounds to your drawable. The left, top, right and bottom describe the drawable’s size and its position on the canvas. You can find the preferred size for Drawables using getIntrinsicHeight() and getIntrinsicWidth() methods and decide bounds accordingly.
Drawing Texts: Drawing texts can be a bit of pain. Not the drawing itself, but the alignment or measurement of text. This occurs because different characters have different heights and to make it more worse there can be different typefaces too. So to measure a text’s height you would need to calculate specific text bounds for your text like this.
Then, the rect object passed in the end would then contain the text bounds of actual text to be drawn. This way you can calculate the actual height of text to be drawn and set a correct baseline y for your text. To calculate the width of your text you should use textPaint.measureText() as it is more accurate than the width given by paint text bounds (because of the way these methods are implemented in skia library). Alternatively, for ensuring the text is centered horizontally on the canvas you can just set your paint’s alignment to TextAlign.CENTER and pass center point of your canvas in the x coordinate.
Drawing multiline text: If you want to handle line breaks (\n) or If you have a fixed width to draw a text you can use Static Layout or Dynamic Layout. This would automatically handle all the word breaks or line breaks and also tell you how much height would be needed to draw a text in given width.
- Saving & Restoring Canvas: As you might have noticed, we need to save the canvas and translate it before drawing on it and finally we have to restore the canvas. A lot of times we need to draw something with a different setting such as rotating the canvas, translating it, or clipping a certain part of canvas while drawing a shape. In this case, we can call canvas.save() which would save our current canvas settings on a stack. After this, we change canvas settings ( translation etc) and then draw whatever we want to with these settings. Finally, when we are done drawing we can call canvas.restore() which would restore canvas to the previous configuration that we had saved.
- Handling User Inputs: Finally, you have created your own custom view using XML attributes, BUT what if you want to change any property at runtime such as the radius of the circle, text color etc. You would need to inform Android API’s to reflect the changes. Now, if any change in property affects the size of your view you will set the variable and call requestLayout() which would recalculate your view’s size and redraw it. However, if a property like a text color is changed you would only need to redraw it with new text paint color and in this case, it would be wise to just call invalidate().
Additional Note: Now if your view has a lot of attributes, there may be a lot of times you would have to write invalidate()/requestLayout after every setter. This problem can be solved by using kotlin’s delegates. Let us take a look a the example below to be more clear.
Now, If I know that a property if changed should only redraw the view, I would initialize it using OnValidateProp but if it can affect the size of the view I would initialize by creating a new OnLayoutProp delegate.
Finally! You can start by creating your own custom views. If you are interested to see what an actual custom view code looks like. You can check out the library that I just published. It displays steps along with the descriptions and covers most of the things that I have discussed in this article.
Источник
Создание собственной View под Android – может ли что-то пойти не так?
 «Дело было вечером, делать было нечего» — именно так родилась идея сделать вью с возможностью зума, распределяющую юзеров по рангам в зависимости от кол-ва их очков. Так как до этого я не имел опыта в создании собственных вьюшек такого уровня, задача показалась мне интересной и достаточно простой для начинающего… но, *ох*, как же я ошибался.
«Дело было вечером, делать было нечего» — именно так родилась идея сделать вью с возможностью зума, распределяющую юзеров по рангам в зависимости от кол-ва их очков. Так как до этого я не имел опыта в создании собственных вьюшек такого уровня, задача показалась мне интересной и достаточно простой для начинающего… но, *ох*, как же я ошибался.
В статье я расскажу о том, с какими проблемами мне пришлось столкнутся как со стороны Android SDK, так и со стороны задачи (алгоритма кластеризации). Основная задача статьи – не научить делать так называемыми “custom view”, а показать проблемы, которые могут возникнуть при их создании.
Тема будет интересна тем из вас, кто имеет мало (или не имеет вовсе) опыта в создании чего-то подобного, а также тем, кто хочет словить лулзов с автора в сто первый раз уверовать в «гибкость» Android SDK.
1. Как это работает?
Для начала кратко опишу то, как устроено сделанная вьюшка:
Иерархия (зеленым отмечены собственные вьюшки)
RankingsListView
Во главе стола – RankingsListView (наследник ScrollView ). Он управляет скроллом (неожиданно, да?) и зумом, а также занимается созданием списка из RankingView .
RankingView
RankingView отображает ранг (слева) и UsersView (справа).
UsersView
UsersView , как вы могли уже догадаться, занимается отображением юзеров и показом анимаций объединения и разъединения юзеров в группы.
GroupView
И юзер, и группа юзеров отображаются одним вью, называемым GroupView . Только в случае, когда отображается один юзер, а не группа, будет отсутствовать зеленый круг (внутри которого отображается кол-во юзеров в группе). Ну а справа расположен показатель очков юзера/группы со знаком «%».
Пожалуй всё со скучной частью, переходим к проблемам.
p.s. Ссылка на исходники в «Заключении».
2. Android SDK «хочет сыграть с тобой в игру» © Goog… Пила
Начнем с безобидного.
2.1. Inflate разметки внутрь кастомного View с использованием DataBinding
DataBinding с её генерацией кода творит чудеса:
Пару строк и через переменную binding доступны по id все вью, указанные в разметке, какой бы сложной эта разметка не была. Никаких больше:
… и ещё с десяток подобных строк как при ButterKnife . Но постойте! setContentView() – это метод Activity . А что же вьюшкам делать
Для того, чтобы добавить разметку внутрь текущего вью нужно вызвать метод inflate(getContext(), R.layout.my_view_layout, this) , например, внутри конструктора. Интересен последний флаг. Он добавляет вью, созданную по разметке, внутрь текущего вью. Это приводит к тому, что если в вашей разметке корневой тег, например, LinearLayout , и вы попробуете использовать inflate(…) внутри вашей вьюшки, унаследованной от LinearLayout , то вы получите два LinearLayout в иерархии…
…И это вполне логично, хоть и не приятно, ведь один из LinearLayout ’ов избыточен. Что же делать? Обойти подобное достаточно просто. Нужно воспользоваться тегом внутри разметки, обернув в него всё, что должно быть внутри вашего вью, как это описано здесь.
Но! DataBinding не поддерживает . Его корневым тегом обязан быть тег , внутри которого должен быть единственный дочерний элемент-не- (на самом деле там может быть ещё тег , но уже совсем другая история).
Как итог, на данный момент нет способа использовать DataBinding в собственный вьюшках, не наплодив дополнительных Layout ’ов, что не лучшим образом скажется на производительности. ButterKnife по-прежнему наше всё.
2.2. Measure & Layout passes
Несмотря на то, что я не имел опыта в создании вьюшек, я всё же читал изредка попадавшиеся на глаза статьи по этой тематике, а также же видел раздел документации, посвященной теме «как вьюшки отрисовываются». Если верить последней, то всё проще простого:
- вызывается пару раз onMeasure() для определения размеров;
- вызывается onLayout() для расположения элемента внутри контейнера;
- вызывается onDraw() для отрисовки.
Ну о-о-о-очень просто. Именно по этой причине я считал, что реализовать собственную вьюшку не составит труда. Но не тут-то было (спойлер: автор отхватит больших проблем от метода onLayout далее по тексту). Вот список советов и правил, которые я вывел после создания вьюшки:
- onMeasure() предназначен только для определения размеров. Не имеет абсолютно никакого смысла помещать в него что-либо ещё. Причина не только в том, что метод вызывается несколько раз, но и в том, что нельзя с уверенностью сказать, будет ли вызван он ещё раз до onLayout() или же текущий подсчитанный размер – финальный;
onSizeChanged() , который по какой-то невероятной причине зачастую не упоминается в статьях по кастомным вьюшкам, вызывается до onLayout() , но внутри метода layout() , вызванным родителем. Суть такова, что layout() вызывает setFrame() , который вызывает onSizeChanged() , а уже потом (после выхода из setFrame() ) вызывается onLayout() . Это означает, что внутри метода onSizeChanged() вы всё ещё не можете положиться на то, что все дочерние вью внутри вашего вью расположены как нужно. Более того, у них ещё не были вызваны их onSizeChanged() , не говоря уже об onLayout() ;
Внутри onLayout() можно вызывать measureChildren() самостоятельно. Иначе говоря, если вью того пожелает, он может ещё несколько раз прогнать measurement pass;
Ни в одной статье, которую я читал по теме вьюшек, я не видел подобных описаний этих методов. То ли никто не сталкивается с подобным, то ли это первое правило клуба кастомных вью – не говорить об onLayout() (исключен; потрачено).
В моем случае внутри UsersView.onLayout() происходит изменение Y-координат вьюшек, из-за чего некоторые вьюшки становятся видны, а другие прячутся, и это приводит к… (внимание на правый низ):
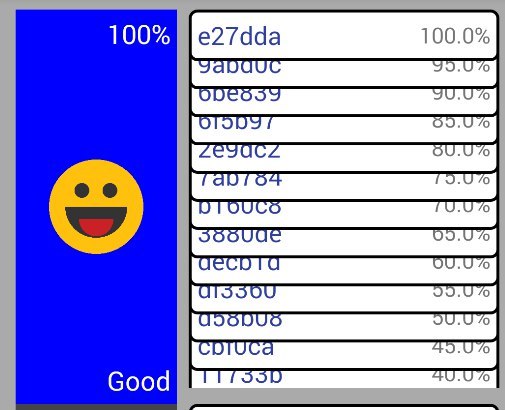
…обрезанию нижней вьюшки. Подобное происходило только при отдалении. Пришлось потупить повозиться, но удалось разобраться, что, похоже, дочерняя вьюшка определила, что со своей текущей позицией Y она в родителе появится лишь на половину, а посему можно обрезать свой Bitmap drawingCache; . Тут на помощь и пришел тот самый дополнительный «measurement pass» в виде measureChildren() внутри onLayout() , заставивший вьюшку пересмотреть свои кэши после изменения её Y-координаты.
2.3. ScrollView не разрешает менять размер ребенка
Пожалуй, многие из вас сталкивались с необходимостью установить высоту дочернего к ScrollView элементу layout_height=match_parent , после чего мгновенно терпели неудачу, ведь результат был всё равно как при wrap_content , а затем находили статью вроде этой с описанием флага fillViewport , угадал? А теперь вопрос: как добиться такого же результата, как с флагом fillViewport , но при этом динамически изменять высоту дочернего элемента?
Давайте по порядку. Как вообще можно изменить высоту элемента? Через LayoutParams.height конечно же, больше никак. Проблема решена? Нет. Высота осталась неизменной. Что же произошло? Изучив onMeasure() в дочернем вью, я пришел к выводу, что ScrollView просто игнорирует установленный height в параметрах, отсылая ему сначала onMeasure() с mode равным « UNSPECIFIED », а затем onMeasure() с « EXACTLY » и значением height ’а, равным размеру ScrollView (если установлен fillViewport ). А так как единственный способ изменить height вьюшки – изменить его LayoutParams – то ребенок и не меняется.
Решений я нашел два:
- Коль ScrollView такой
Тем самым сделав работу ScrollView за него. Но естественно создавать каждый раз подкласс лишь для этого — не очень хорошая идея. Мало ли, какого именно класса должно быть дочернее вью: FrameLayout , LinearLayout , RelativeLayout и т.д. Делать для каждого возможного Layout ’а свой подкласс – только мусорить. Поэтому вот вам решение №2.
Именно подход №2 использовал я, и он сработал на ура. Однако, я не уверен, что это действительно допустимый способ (хак). Возможно, данный хак работает не потому, что дополнительный FrameLayout оказывает должное уважение принимает во внимание LayoutParams.height , а потому, что внутри ScrollView.onLayout() происходит всякая дичь нечто, из-за чего просчитывается размер ребенка лишь частично. Это всего лишь догадка, но иначе объяснить проблему со скроллом (спойлер: проблема будет описана позднее) я не могу.
Ах да, проблема с неизменяемым размером ребенка у ScrollView есть на багтрекере, но как это обычно и бывает с Android’ом, оно всё ещё в статусе New с 2014-го года.
2.4. Закругленные углы у background
Сабж (слева снизу и слева сверху):
Казалось бы, что может быть проще — сделать drawable с тегом , установить background ’ом и готово… но нет. Задача такова, что цвет меняется программно, а закругленные края добавляются лишь первому и последнему элементам.
Как ни странно, у класса ShapeDrawable нет методов для работы с закругленными углами, как можно было бы ожидать. Но к счастью, есть наследник RoundRectShape и PaintDrawable (зачем нужен этот класс – не спрашивайте, сам в шоке), у которых присутствуют недостающие методы. На этом проблему для практически всех приложений можно было бы считать решенной, но не для данной задачи.
Специфика задачи такова, что максимальный zoom in может быть каким угодно, а значит вьюшка с её background ’ом сильно растянутся, что приводет к…
Logcat: W/OpenGLRenderer: Path too large to be rendered into a texture
Выглядит это так, что после превышения некоторого размера, background просто перестает отображаться. Как можно понять из предупреждения, некий Path слишком большой, чтобы можно было его отрисовать в текстуру. Чуток покопавшись в исходниках, я пришел к выводу, что виной всему этот товарищ:
… в mPath которого и помещают закругленный прямоугольник:
Решить данную проблему можно только унаследовав, например, ColorDrawable и в его методе draw() вызвав не drawPath() , а:
Но, к сожалению, у данного подхода есть относительно существенный недостаток: canvas.clipPath() не подвержен antialias. Однако за неимением другого способа сделать подобное, приходится довольствоваться этим.
2.5. Позиционирование View внутри FrameLayout
Данная задача встала передо мной при попытке реализации UsersView , внутри которого GroupView могли быть на любом месте вдоль оси OY.
Первое, что приходило на ум (да и то, что я считал единственным возможным способом перемещения вьюшки внутри FrameLayout ) – использовать MarginLayoutParams и изменять параметр topMargin . Об этом же свидетельствуют большинство ответов на stackoverflow (раз, два, три).
Недостатком данного подхода является то, что изменение LayoutParams вызывает requestLayout() , а это крайне дорогая операция, особенно если она вызывается у всех GroupView внутри UsersView , даже с учетом того, что непосредственно сам layout pass откладывается до лучших времен (следующего 16мс-фрейма).
Но к счастью, есть другой способ – View.setY() (ответ на stackoverflow). Идеально для анимаций и для дочерних элементов внутри неизменяющихся Layout ’ов. Он не вызывает requestLayout() , а использует только поля самой вьюшки и влияет лишь на фазу (pass) layout’а. А так как просчет новых позиций вьюшек происходит прямо в onLayout() до вызова super.onLayout() , requestLayout() и вовсе не нужен.
2.6. Видишь отступы шрифта? Нет? А они тебя видят! © includeFontPadding
Когда юзеры объединяются в группу, добавляется иконка, отображающая кол-во юзеров в группе. Вот как она выглядит сейчас:
А вот как она выглядела раньше:
Замечаете разницу? Есть неприятное чувство, когда смотрите на вторую картинку? Если да, то вы меня понимаете. Я долго не мог сообразить, почему, когда я смотрю на эту иконку, она выглядит не так привлекательно, как предполагалось. Догадавшись взять пэинт в руки и подсчитать, сколько же пикселей слева/справа/сверху/снизу от текста, я понял причину – текст не центрирован до конца. Что-то явно не так гравитацией текста. Да. Нет. Гравитация была установлена верно, другие параметры тоже. Всё выглядело идеально.
В общем, не буду томить, решение оказалось очень простым, но вот найти сходу его не получалось просто потому, что я не понимал, что вообще. Вот, кстати, ссылка на решение. Суть в том, что, оказывается, у шрифтов самих по себе есть padding’и, которые и являлись причиной нецентрируемости. Добавив TextView параметр includeFontPadding=false , проблема исчезла целиком и полностью.
2.7. У ViewPropertyAnimator нет метода reverse()
Хотелось мне сделать анимацию сокрытия иконок рангов при определенном размере. Выглядеть это должно было так:
Чтобы определить момент запуска анимации, сверяем текущий размер с необходимым для умещения всех вьюшек и, если нужно, используем view.animate().setDuration(fadeDuration).alpha(0 or 1) .
Однако, подобное работает хорошо только при быстрой анимации fade ’а. Однако если fade будет медленным, то при резком zoom in после zoom out , альфа канал вьюшки будет не 1 или 0, а, например, 0.5. Из-за чего, анимация будет проигрывается от 0.5 до 0 за те же fadeDuration . Выглядеть это будет так, словно анимация замедлилась в 2 раза. Добавлять до вызова view.animate() нечто вроде view.setAlpha(0 or 1) не является хорошим решением. Вьюшка начнет мерцать при быстром зуме.
В идеале, здесь должен был бы быть какой-нибудь метод вида setReverseDuration() (без параметров), который бы понял, что, «ага, я проигрывал анимацию fade ’а 500мс, поэтому столько же и будет играть reverse-анимация». Но такого нет, увы. Единственный выход, что мне удалось найти, делать подобное ручками. В моем случае анимация была довольно простая, так что мне хватило этого для скрытия:
… и этого для показа:
Ну а дальше как обычно: view.animate().setDuration((long) realDuration) — и всё в ажуре.
2.8. ScaleGestureDetector (он же «пинч», он же «зум»)
Сам по себе API у ScaleGestureDetector довольно хороший – повесил listener и ждешь себе эвенты, не забыв передавать все onTouchEvent() ‘ы в сам детектор. Однако, не всё так радужно.
2.8.1. Небольшие замечания
Во-первых, нигде не сказано, как разграничить внутри onTouchEvent() эвенты между собственно самим ScaleGestureDetector и ScrollView (ведь, напоминаю, дело происходит внутри RankingsListView , который является наследником ScrollView ). Как итог, метод выглядит так:
И таким его советуют делать все stackoverflow-ответы (пример). Однако такой подход обладает недостатком. Скролл происходит даже тогда, когда вы производите пинч. Может показаться что это пустяк, но на деле очень неприятно случайно листнуть вьюшку, когда пытался её прозумить.
Я был готов долго и нудно рыскать в поисках сложного решения разграничения ответственности между super.onTouchEvent() и scaleDetector.onTouchEvent() … и я и правда искал… Но как оказалось, решение было ужасно простое:
Гениально, да? super.onTouchEvent() не отслеживает id пальца, которым был произведен скролл в первый раз, поэтому даже если вы начали скролл пальцем №1, а закончили пальцем №2 – ему норм, схавает. К сожалению, я так был уверен, что Android SDK в который раз вставит палки в колеса, что удосужился попробовать подобное только после: гуглинга и изучения исходников. Что сказать, Android SDK умеет иногда работать как надо удивлять.
Во-вторых, если вы страдаете микро оптимизационной болезнью, то вам придётся следить за размером ваших дочерних вью с особой осторожностью. Как вы уже знаете, при пинче я увеличиваю высоту для child внутри child у ScrollView . Этим child’ом является LinearLayout , дочерним элементам которого прописан layout_weight=1 . Иначе говоря, все они одной высоты… хотя нет.
Это совершенно никогда не заметно, но его дочерние вью не всегда могут быть одной высоты, ведь пиксели – атомарные единицы. То есть, если LinearLayout имеет высоту 1001 и у него 2 дочерних элемента, то один из них будет размером 501, а другой 500. Заметить это на глаз практически нереально, но вот косвенные последствия могут быть.
Когда я говорил про ViewPropertyAnimator и reverse() , я показал анимацию сокрытия иконки ранга. Сама проверка простая – суммируем высоту 2-ух TextView и ImageView в onLayout() , и если они не влазят внутрь текущей вьюшки разом, то прячем fade ’ом ImageView . Стоит отметить также, что эта суммарная высота (так сказать «порог высоты») не меняется. Как итог, если порог равен 500 пикселей, то в описанном случае, у одного вью размером 500 иконка спрячется, а у второго, размером 501, нет.
Ситуация редкая и не слишком критичная (было не так уж просто (но и не сложно) двигать мышкой так медленно, чтобы обнаружить не скрытые и скрытые иконки одновременно). Но всё же если вам не нравится такое поведение, исправить это можно только одним способом – не использовать getHeight() для сверки с порогом. В onSizeChanged() внутри LinearLayout ’а находите наименьший размер у всех дочерних элементов и оповещаете всех о том, чтобы они сравнивали порог именно с этим числом. Я назвал это shared height и выглядит у меня это так:
А сама сверка с пороговым значением так:
2.8.2. Проблемы
А теперь поговорим не о придирках к ScaleGestureDetector , а о его проблемах.
2.8.2.1. Минимальный пинч
И-и-и-и-и-и… он (минимальный пинч) не отключаем. Во время кодинга я ещё не знал ни о какой «минимальной дистанции для срабатывания пинча», поэтому мне пришлось чуток поизучать логов, чтобы понять, косяк ли это в моем коде или же в чем-то ещё. Логи гласили, что если расстояние между пальцами было менее 510 пикселей, то ScaleGestureDetector просто переставал реагировать на касания, присылая эвент onScaleEnd() . Информации о том, что есть какой-то там «минимальный пинч» не присутствовала ни в доках, ни на stackoverflow. Возможно, я бы даже не заметил подобное, если бы отладка происходила не на эмуляторе. На нём дистанция пинча может быть хоть миллиметровой, что и послужило поводом для поиска информации по вопросу. Однако, она оказалась куда ближе, чем я думал, а именно, как всегда, в исходниках:
И-и-и-и-и… конечно же у класса нет методов для изменения этого поля, и конечно же com.android.internal.R.dimen.config_minScalingSpan равен магическим 27mm. Для меня вообще существование минимального пинча представляется очень странным явлением. Даже если и есть смысл в подобном, почему не дать возможность его изменить?
Решением проблемы как обычно является рефлексия.
2.8.2.2. Слоп
Для тех, кто не знает, что такое «слоп» (как и я), перевожу:
Slop — чушь, бессмыслица © ABBYY Lingvo
Ладно-ладно, шутки в сторону. «Слоп» это такое состояние, когда считается, что юзер случайно задел экран и на самом деле не хотел ничего двигать/скроллить/зумить/ещё чего. Эдакая «защита от случайного движения». Гифка объяснит:
… на гифке видно, что до начала пинча допускаются минимальные движения, которые не будут считаться пинчем. В принципе, хорошая вещь, плюсую.
Но… слоп то тоже не изменяем! ScaleGestureDetector описывает его так:
… а ViewConfigeuration так:
Откуда именно такое значение? Зачем? Почему? Непонятно… В общем, Android SDK – это лучший учебник по рефлексии.
2.8.2.3. Скачки detector.getScaleFactor() при первом пинче
Внутрь эвента onScale(ScaleGestureDetector detector) передается detector , у которого при помощи метода detector.getScaleFactor() можно узнать коэффициент пинча. Так вот, при самом первом пинче, этот метод возвращает странные скачкообразные значения. Вот логи значений при строго движении zoom out :
Выглядело это, мягко говоря, не очень – постоянно дергался размер вьюшки, а уж как анимации при этих скачках выглядели – лучше и вовсе опустить.
Я долго пытался понять, в чем же проблема. Проверял на реальном устройстве (мало ли, вдруг проблема эмулятора), двигал мышкой так, будто за лишний миллиметр движения где-то умирает котик (мало ли, вдруг я дерганный и отсюда коэф. > 1 в логах) – но нет. Ответ найден не был, но мне повезло. Так сказать «от балды», решил попробовал отправить в ScaleGestureDetector эвент MotionEvent.ACTION_CANCEL сразу после инициализации:
… и это помогло О_о… Покопавшись (который уже раз, а, Android SDK?) в исходниках, обнаружилось, что у первого пинча нет слопа (да-да, это того, о котором писалось выше). Почему так – для меня осталось загадкой, ровно как и то, почему этот хак помог. Вероятнее всего где-то они намудрили с инициализацией и часть класса считает, что самый первый пинч уже прошел проверку на слоп, а другая часть считает, что нет, и в итоге в пылу жаркой битвы вида «прошел / не прошел» попеременно побеждает одна из них. ¯\_(ツ)_/¯ © SDK
2.9. ScrollView.setScroll() срабатывает только после super.onLayout() ?
Возвращаемся к проблеме с игнорированием ScrollView установленных дочерними элементами height ’ов. Ситуация следующая: как только происходит пинч, хотелось бы чтобы текущий фокус (куда ты кликнул мышкой и из какой точки вообще делаешь зум) остался тем же. Почему? Ну просто так зум выглядит более user-friendly, считай, ты не просто изменяешь height дочернего элемента, а именно зумишь к какому-то юзеру, в то время как все остальные разъезжаются от него:
Сделать это не сложно через ScaleGestureDetector.getFocusY() вместе с ScrollView.getScrollY() . Затем, казалось бы, достаточно сделать ScrollView.setScrollY(newPosition) и дело в шляпе… Но нет, вью начинает странно дергаться при зуме к самому нижнему дочернему элементу:
Решение нашлось здесь. Происходит следующее: в момент, когда мы делаем setScroll() происходит проверка того, не выходит ли позиция скролла за размер дочернего элемента, и если выходит, то устанавливаем максимально возможную позицию. А так как setScroll() вызывается при зуме, то и получается следующая последовательность действий:
- Просчитываем newHeight
- Просчитываем newScrollPos
- Устанавливаем newHeight через setLayoutParams()
- Устанавливаем newScrollPos через setScroll()
Проблема в пункте №3. Реальный height не изменится до следующего super.onLayout() , поэтому setScroll() и делает не то, что ожидается. Исправляется следующий образом. Вместо setScroll() делаем так:
… а в onLayout() после метода super.onLayout() вызываем этот метод:
Как вы помните, я писал, что лучше бы не вызывать никаких методов после super.onLayout() . Это по-прежнему так. Позже я опишу ещё одну проблему, связанную с этим решением. Но факт остается фактом, это – решение для проблемы скачка скролла.
p.s. Однако если не использовать хак с «меняем height для child внутри child внутри ScrollView », то такой проблемы не будет. Но тогда возвращаемся к проблеме десятка подклассов.
3. Задача кластеризации юзеров
Теперь время поговорить о самой задаче, её алгоритме и некоторых её особенностях.
3.1. Что делать с граничными юзерами?
Я говорю о юзерах, которые находятся на границе своего ранга:
На картинке граничные юзеры — это юзеры с очками 0%, 30%, 85% (его почти полностью перекрыл юзер с 80%). Самым простым способом было бы рисовать их на своей законной позиции (равной:  ), но в таком случае они начнут заезжать в чужие ранги, что выглядело бы мягко говоря «не комильфо». Основная причина отказа от этого – группировка. Представьте себе юзера с 29% очков. Он находится на границу ранга «Newbie». Но вот он вдруг объединяется с юзером с 33% очками и их совместная группа теперь расположена в позиции, соответствующей 31%, т.е., в ранге «Good». Мне не очень понравилась идея, что группировка вьюшек может менять ранги юзеров, поэтому от неё я отказался и решил ограничить юзеров внутри рангов так, как вы видели на картинке выше.
), но в таком случае они начнут заезжать в чужие ранги, что выглядело бы мягко говоря «не комильфо». Основная причина отказа от этого – группировка. Представьте себе юзера с 29% очков. Он находится на границу ранга «Newbie». Но вот он вдруг объединяется с юзером с 33% очками и их совместная группа теперь расположена в позиции, соответствующей 31%, т.е., в ранге «Good». Мне не очень понравилась идея, что группировка вьюшек может менять ранги юзеров, поэтому от неё я отказался и решил ограничить юзеров внутри рангов так, как вы видели на картинке выше.
Забегая вперед отмечу, что это добавило очень много мороки алгоритму группировку и логике работы приложения в целом.
3.2. Какое кол-во очков показывать у группы?
Допустим, в группу объединились 2 юзера с очками 40% и 50%. Где расположить их совместную группу и с какими очками? Ответ простой: 45% у группы, позиция соответствует очкам группы.
Усложним задачу. А этих как объединить?
Здесь есть 2 способа решения:
- Так же, как с юзерами 40% и 50%. То есть, ставим группу на позицию 2.5%.
- Ставим группу в позицию
 , а очки уже вычисляем из позиции вьюшки в пикселях.
, а очки уже вычисляем из позиции вьюшки в пикселях.
 , а очки уже вычисляем из позиции вьюшки в пикселях.
, а очки уже вычисляем из позиции вьюшки в пикселях.Разница подходов в том, что в первом случае вьюшка группы будет не по центру между вьюшками юзеров, во втором же она будет именно по центру, что куда более благоприятно с точки зрения user experience.
Предпочитая UX, я решил делать именно способом №2, однако у подхода обнаружился существенный недостаток: очки группы вычисляются совершенно криво. Дело в том, что юзер с 0% на самом деле расположен не в позиции 0 (ведь в таком случае он бы заезжал на территорию чужого ранга), поэтому можно сказать что у всех вьюшек в ранге не может быть очков меньше, чем некоторый minScore , который ещё и меняется при зуме, ведь вычисляется по формуле (упрощенная версия):

… так как userViewHeight неизменен, а containerHeight меняется, то в разные моменты пинча очки у граничных вью будут разные.
Более того, сама формула:

… привносит ошибку округления, т.к. позиция измеряется в пикселях, которая добавляет случайность последней цифре в числе очков (на самом деле всё не совсем так. Если использовать view.getY() , то она возвращает float , а не пиксели, и всё в порядке, а вот если испоьзовать MarginLayoutParams.topMargin , то да, ошибка будет).
Учитывая все эти недостатки способа №2, было принято решение использовать способ №1, хоть и групповая вьюшка будет появляться не точно по центру между юзер-вьюшками.
3.3. Алгоритм
Вот уж где можно разгуляться. Что я и сделал. У меня было по крайней мере 5 различных реализаций, которые так или иначе были подвержены «неприятным» эффектам, которые вынуждали меня вновь и вновь решать проблему по-новому.
Я мог бы написать финальную реализацию и закончить на этом, но всё же предпочел описать несколько своих реализаций. Если вам интересна описанная ниже проблема кластеризации, подумайте, как бы вы её решили (какой алгоритм бы придумали/использовали), а уже затем читайте абзац за абзацем, меняя своё решение, если оно, также как было моё, подвержено артефактам.
3.3.1. Задача
Сделать кластеризацию с хорошим UX, а это значит, что:
- Граничные вью должны оставаться внутри ранга.
- Юзеры должны объединяться в строго заданном порядке – не допускается, что при zoom in с последующим zoom out и повторным zoom in юзеры будут объединяться в группы как-то иначе.
- Юзеры устанавливаются единожды и больше не добавляются/удаляются (правило добавлено из соображений по пункту №2).
3.3.2. Пару слов об алгоритмах
Важно отметить, что во всех реализациях перед запуском самого алгоритма производится сортировка всех юзеров по их очкам и каждый юзер оборачивается в класс Group , ведь по сути, одиночный юзер — это просто группа из одного человека. Также, используя слово «юзер» я могу подразумевать как одного юзера до объединения в группу, так и группу юзеров.
По поводу обозначений. Я буду отмечать номер юзера одной цифрой: «7», — а группы – двумя: «78». Цифры в номере группы обозначают номера юзеров в неё входящих, то есть группа 78 состоит из юзеров 7 и 8.
К каждому алгоритму будет приведено как словесное описание, так и псевдокод.
3.3.3. Алгоритм №1
Простой последовательный алгоритм, объединяющий юзеров в порядке следования, если они пересекаются.
1. Проверить, пересекаются ли юзеры с индексом i и i+1.
2.1. Если пересекаются – объединить и сделать ячейкой №1.
2.2. Если не пересекаются, инкрементировать индекс.
3. Повторять с шага 1 пока не достигнут последний индекс.
Но у этого алгоритма есть проблема с UX:
Он объединяет всех юзеров воедино, если те достаточно близки изначально, что приводит к нерациональному использованию пространства, а значит – алгоритм не подходит по UX.
3.3.4. Алгоритм №2
Очевидно, проблема в том, что все юзеры проверяются последовательно. Поэтому я решил чуть доработать алгоритм №1. Теперь будет как минимум пара проходов по списку юзеров: четный и нечетный проходы. Как только в обоих проходах не будет найдено пересечение, алгоритм закончится.
Шаги:
0. i = 0.
1. Проверить, пересекаются юзеры с индексом i и i+1.
2.1. Если пересекаются – объединить, и записать в первую ячейку. Индекс инкрементируется на 1.
2.2. Если не пересекаются, индекс инкрементируется на 2.
3. Если не достигнут последний индекс, повторить шаг 1.
4. Если i == 1 и не нашлось пересекающихся групп, то закончить алгоритм.
5. Повторить с шага 0, инвертировав i (с 0 на 1 или с 1 на 0 – смена на нечетный или четный проходы).
Алгоритм решает предыдущую проблему, но появляется новая, связанная с неправильным разъединением после объединения (из-за иной скорости зума). Такую проблему я называю «проблема 21-12» (название поясню позже):
Объясню, что здесь произошло. При запуске алгоритма, было выявлено, что 1 и 2 юзеры пересекаются и образуют группу. С их группой пересекается 3ий юзер, а посему все они образуют ещё одну группу.
Однако если попробовать их расцепить при более быстром зуме, то произойдет то, что вы видите в нижней части картинки – два юзера будут пересекаться, но не будут образовывать группу.
Даже если после разбиения запускать ещё один проход объединения, мы получим группу 23, которой раньше не существовало. Раньше юзеры объединялись в группы с размером 2 и 1, а теперь, после разъединения, они образуют группы размером 1 и 2. Отсюда и название «проблема 21-12». Это плохо сказывается на UX, когда группу объединяются по-разному в зависимости от скорости зума, а значит алгоритм не подходит.
3.3.5. Алгоритм №3
Тут мне стало ясно, что тупо в лоб задачу не решить и придётся использовать артиллерию потяжелее. Поэтому я решил объединять юзеров на основе расстояния между ними (их вьюшками). Чем меньше расстояние между юзерами – тем первее их объединение. А для того, чтобы разбивать группы, можно просто ввести поле типа Stack groupsStack; и добавлять туда каждую новую группу. Таким образом при разъединении потребуется проверять лишь самый верхний элемент на стэке.
Шаги:
0. Создать массив дистанций между каждой последовательной парой юзеров (массив получится длиной groups.size() – 1, ведь пересечься юзер/группа может только со своими соседями слева и справа). Отсортировать массив дистанций по возрастанию
1. Проверить первую дистанцию между вьюшками. Она меньше либо равно 0?
YES.1. Объединить 2-ух юзеров в группу и добавить группу в стэк групп.
YES.2. Удалить текущую дистанцию. Обновить дистанции, которые зависели от этих 2-ух юзеров, заменив их на дистанцию до их совместной группы.
YES.3. Отсортировать массив дистанций по возрастанию.
YES.4. Перейти к шагу 1.
NO.1. Закончить алгоритм.
Я думал «ну уж этого точно будет достаточно». Но нет. Оказалось, и здесь есть своя проблема: неверный порядок объединения групп. «Как такое может быть?!» — подумали вы? Да очень просто. Что если сделать о-о-о-о-очень резкий зум?
В результате резкого зума у всех юзеров позиция стала одной и той же, ведь они и до зума были достаточно близки друг к другу. Из-за этого sortAsc() не знал, что делать, ведь расстояние между юзерами 1 и 2 равно 0, но и между юзерами 2 и 3 оно также равно 0. Как итог, группы объединились в неверном порядке. Особенно это будет заметно при разъединении. Первыми будут разъединены 12, ведь объединились они последними (стэк — это LIFO. Все помнят?), хотя они и ближе к друг другу.
3.3.6. Алгоритм №3.1
Самый простой способ починить предыдущий алгоритм – дать понять для sortAsc() разницу между разными «расстояние равно 0». И это можно сделать, просто добавив доп. проверку при сортировке, что, если distance == 0 сразу между 2-мя парами юзеров, то сверяй их group.scoreAfterMerge . Если пояснять кодом, то функцию сравнения для сортировки GroupsDistance, используемую при реализации в прошлом алгоритме:
… заменяем этой с доп. сравнением group.scoreAfterMerge ‘ов:
Действительно, user.score и group.scoreAfterMerge всегда будут неравны (а если и равны, то нет разницы, в каком порядке их объединять — всё равно они никогда не расцепятся). Это означает, что доп. сравнения по score должно хватить для решения задачи… но нет, и в этом случае присутствует недочет.
Помните условие задачи: «Граничные вью должны оставаться внутри ранга»? Проблема кроется в нём. Если бы не это условие, distance между юзерами всегда изменялся бы пропорционально, а позиция вьюшки юзера однозначно отображала бы его score , но это не так. Из-за этого условия, у граничных вью нарушается зависимость позиции от score . Это довольно неочевидно, поэтому вот подробный пример подобного «нарушения»:
Допустим, высота у вьюшек юзеров 100. Тогда если у юзера позиция 0, то его нижняя координата равна 100. Юзеров я буду отмечать вот так: [0, 100], то есть в виде [начало_вьюшки, конец_вьюшки]. Считайте, что мы работаем с 1D пространством. Для определения пересечения между двумя вьюшками (например, [0, 100] и [60, 160]) нужно вычесть из конца вьюшки №1 начало вьюшки №2, т.е.  .
.
Итак, имеем вьюшку ранга высотой 1000 и 3-ех юзеров:
Юзер №1 с 60%: [600, 700].
Юзер №2 с 79%: [790, 890].
Юзер №3 с 100%: [900, 1000] (до коррекции: [1000, 1100]).
Примечание: у юзера №3 позиция не [1000, 1100] потому, что выход за границы ранга недопустим. Поэтому его вьюшка была перемещена на ближайшую возможную позицию внутри вьюшки ранга.
Казалось бы, расстояние между №1 и №2 равно 90, между №2 и №3 равно 10. Последние пересекутся раньше при зуме, верно. Произведем зум с коэффициентом 0.5 (вьюшка ранга стала размером 500):
Юзер №1 со 60%: [300, 400].
Юзер №2 с 79%: [395, 495].
Юзер №3 с 100%: [400, 500] (до коррекции: [500, 600]).
Расстояние между №1 и №2 равно -5, между №2 и №3 равно -95. №2 и №3 объединились раньше, чем №1 и №2, всё как и хотели, ура. Нет :D. Вернем зум обратно и на этот раз произведем зум с коэффициентом 0.2 (размер вьюшки ранга стал 200):
Юзер №1 со 60%: [100, 200] (до коррекции: [120, 220]).
Юзер №2 с 79%: [100, 200] (до коррекции: [158, 258]).
Юзер №3 с 100%: [100, 200] (до коррекции: [200, 300]).
Расстояние между №1 и №2 равно 0, расстояние между №2 и №3 тоже равно 0. Как гласит алгоритм, сравним тогда вьюшки по user.score и… Совершенно внезапно, №1 и №2 объединились в группу раньше, чем №2 и №3, что в итоге приведет к рывкам при разъединении.
Ситуация может показаться довольно синтетической, однако она происходит не только на границе ранга, но и в центре, если сделать достаточно резкий зум. Просто для примера было проще показать проблему на границе.
«И этот алгоритм не подходит. Что же вообще делать? Что лучше, чем сортировка дистанций между вьюшками юзеров да сравнение по score ?!» — думал я в момент обнаружения проблемы.
3.3.7. Алгоритм №4
Давайте создадим время. Континуум, если быть точнее. Это довольно известная задача в сфере компьютерной физики. Если квантовать время слишком большими отрезками, то объект «A» пересечет объект «B» и это не будет детектировано из-за слишком большой скорости движения. Вот пример:


Даже если мы квантуем время на наносекунды ( ), то в следующий момент времени позиция «B» будет считаться так:
), то в следующий момент времени позиция «B» будет считаться так: 
То есть мы получим: 
«B» просто прошел «A» насквозь, и мы этого никак не заметили, ведь их координаты никогда не пересекались и даже не находились вблизи.
С задачей кластеризации та же беда, только вместо скорости движения – скорость зума, а вместо позиции объектов – позиции вьюшек. В общем, суть нового, и последнего, алгоритма в том, чтобы считать не дистанции между вьюшками юзеров, а height , при котором эти 2 юзера пересекутся! Затем останется лишь отсортировать этот массив willIntersectWhenHeight ’ов и проделать всё то же самое, что с массивом дистанций в предыдущем алгоритме. Главное – не забывать, что у боковых (называемых также border или bound ) юзеров/групп позиция меняется иначе, чем у остальных. Случаи пересечения с ними нужно рассматривать отдельно.
Так как шаги алгоритма те же, что и раньше, то приведу только код функции, ответственной за подсчет willIntersectWhenHeight ’а в классе GroupCandidates . Пожалуй, важно отметить, что я использовал для обозначения групп не массивы, а двоичные деревья. Это позволило упростить логику работы как самого алгоритма, так и анимаций кластеризации.
Примечание: getNormalizedPos() возвращает нормализованную (т.е., от 0 до 1) позицию внутри ранга.
Этот алгоритм прошел все проверки, что я смог придумать, а также показал довольно резвую скорость работы. В общем, задача решена.
4. Нерешенные проблемы (UPD: уже решенные)
А теперь о плохом. Изначально я планировал написать статью уже после того, как решу все проблемы, но из-за нехватки времени и мысли «а вдруг в комментах помогут – время сэкономлю», я решил выложить так, как есть. Как освободится время, я вернусь к этим проблемам, и, если не забуду, добавлю решение сюда.
4.1. ScrollView.setScroll() внутри ScrollView.onLayout() срабатывает корректно только после вызова super.onLayout() (если изменять размер child’а внутри child’а этого ScrollView )
Эта проблема была описана ранее. Я не нашел способа, как заставить ScrollView воспринимать setScroll() до super.onLayout() . Почему это важно? Дело в requestLayout() . Данный вызов устанавливает флаг вида «нужно сделать layout pass» и откладывает просчеты до следующего 16мс-фрейма. То есть, сколько ты requestLayout() не вызывай, до тех пор, пока не будет вызвать super.onLayout() (который расставит дочерние вью и снимет флаг), layout pass произведен не будет.
Однако, если вдруг requestLayout() будет вызван после super.onLayout() , то флаг будет установлен заново. А это значит, что во время следующего фрейма отрисовки (через 16мс), произойдет новый layout pass, который вызовет ScrollView.onLayout() , в котором опять будет запрошен requestLayout() после super.onLayout() и… в общем, каждый 16мс-фрейм будет происходить полный пересчет Layout ’ов всех вьюшек на экране. Короче, тихий ужас. Но если такое случается только после попытки сделать requestLayout() после super.onLayout() , а ScrollView.setScroll() не вызывает requestLayout() , то в чем же проблема? А вот в чем:
4.2. View.setVisibility(GONE) вызывает requestLayout()
Текущая реализация алгоритма (которая с континуумом) работает очень быстро, но не реализация отрисовки вьюшек. В идеале, необходимо добавить recycling вьюшек юзеров/групп, да и вообще не пытаться отрисовывать вьюшки, что находятся за пределами экрана.
Такое возможно сделать, используя View.getLocalVisibleRect() (возвращает координаты видимого окна) внутри UsersView и затем для каждого вью что попал на экран, делать groupView.setUsersGroup(group) , внутри которого будет groupsCountView.setVisiblity(…) .
Однако! Его нужно использовать после того, как будет произведен ScrollView.setScroll() , ведь данный вызов меняет результат View.getLocalVisibleRect() . А так как ScrollView.setScroll() вызывается после super.onLayout() , а groupView.setUsersGroup(group) может вызвать View.setVisiblity(GONE) , который вызывает requestLayout() , то мы получаем бесконечный цикл, описанный в предыдущей проблеме.
Более того, при каждом скролле даже не связанном с зумом будет меняться видимое окно, а значит нужно будет показывать иные вьюшки, вызывая заново View.getLocalVisibleRect() , который приведет к вызовам View.setVisiblity(GONE) , а они к requestLayout() . То есть, при каждом скролле будет происходить requestLayout() – это просто немыслимо!
Я пытался решить это по-разному, но даже если переопределить метод requestLayout() внутри GroupView , получается полурабочий результат (дочерние вью внутри GroupView начинают периодически «скакать»… сложно объяснить. Причину не нашел), да и способ «переопределить requestLayout() » мне не слишком то нравится. Слишком уж он «дерзкий», так сказать. Возможно, есть иное решение, но stackoverflow вместе с гуглом молчат как партизаны.
4.999. Решение описанных проблем
Указанные выше проблемы так или иначе связаны с тем, что requestLayout() вызывается чаще, чем того хотелось бы (а то и вовсе зацикливается). Как правильно указали в комментариях, всех проблем можно избежать, если воспользовать RecyclerView и его LayoutManager .
Однако, так как моей целью было поработать с графикой, а не RecyclerView , был найден другой способ. Итак, чтобы избавиться от навязчивых requestLayout() , которые вызываются при любом чихе (например, child.setVisibility(GONE) ), нужно… не добавлять child ‘ов в Layout вообще! То есть не вызывать: layout.addView(myChild) .
Подобный подход приводит к следующему:
- появляется необходимость самому хранить View ‘шки child ‘ов;
- необходимо вручную вызывать measure() , layout() и drawChild() для child ‘ов в нужное время;
- child ‘ы становятся абсолютно независимыми, а потому любые изменения над ними не вызовут requestLayout() .
Именно пункт №3 и позволяет решить все приведенные проблемы. А дальше — дело за малым. При помощи View.getLocalVisibleRect() отслеживать видимые в данный момент на экране юзеров/группы и только для них вызывать группировку/разъединение/отрисовку.
p.s. Хотя и здесь без проблем не обошлось… например, вы знали, что onScrollChanged() может быть вызван во время onLayout() , даже если вы предварительно не вызывали setScrollY() ? В моём случае это приводило к тому, что View.getLocalVisibleRect() возвращал false (мол, UsersView сейчас не на экране). Пришлось же помучиться, чтобы понять, как такое вообще возможно :/ В общем, результирующий код вместе с recycling ‘ом лежит на гитхабе. Работает довольно шустро даже при 1.000 юзерах на старых телефонах. А вот с большим кол-вом уже начинает подтормаживать. Тут уже поможет только перенесение кода кластеризации на NDK.
5. Заключение
Задача оказалась куда сложнее и интереснее, чем я себе представлял. Хотел лишь поучиться делать анимацию пересечения, а в итоге поработал с алгоритмами, порылся в исходниках SDK и много чего ещё. С Android’ом скучать не приходится.
Большинство алгоритмических проблем вылезло из-за условия о том, что юзеры не должны заходить за границы ранга. Пока делал алгоритм, столько раз хотел выкинуть это условие, вы б знали -_-«… но по итогу я доволен. Надеюсь, и вы тоже.
Если у вас есть предложения по решению «нерешенных проблем» — пишите в комментариях. Я проверю решение и, если всё хорошо, то обновлю текст.
UPD 1: как предложил мистер Artem_007, добавлены feature-request/bug-report ссылки на упомянутые проблемы.
UPD 2: добавлен пунтк 4.999. с решением «нерешенных» проблем.
Источник



